Abstract
The rapid evolution of Large Language Models (LLMs) has ushered in a new era of AI-native applications and agentic AI systems. While LLMs demonstrate remarkable reasoning, planning, and generation capabilities, they inherently lack long-term memory. This limitation poses significant challenges for enterprises seeking to deploy robust, cost-effective, and consistently performing AI solutions. This white paper introduces Context Engineering as a critical design paradigm that addresses this memory gap. By strategically shaping, curating, and delivering relevant information to LLMs at inference time, Context Engineering enables more intelligent and context-aware AI behavior without requiring the models to “remember” in a traditional sense. We explore the limitations of conventional prompt engineering, detail the principles and components of Context Engineering, provide real-world examples, analyze its current challenges and cost implications, outline best practices, and discuss its future trajectory in overcoming critical hurdles to become mainstream in the AI landscape.
1. Introduction: The Rise of AI Agents and the Prompt Engineering Foundation
The advent of sophisticated Large Language Models (LLMs) has catalyzed a paradigm shift in software development, giving rise to AI agents and agentic AI systems. These autonomous entities are designed to reason, plan, and execute complex tasks, often mimicking human-like problem-solving. At the heart of their initial interaction and guidance lies Prompt Engineering.
Prompt Engineering is the art and science of crafting precise and effective inputs (prompts) to guide an LLM towards generating desired outputs. It involves structuring queries, providing examples, defining constraints, and specifying formats to elicit optimal responses. For AI agents, prompt engineering is a critical cog because it serves as the primary mechanism for:
- Task Definition: Clearly articulating the agent’s objective.
- Role Assignment: Defining the agent’s persona or function.
- Constraint Setting: Imposing boundaries on behavior or output.
- Initial Context Provision: Supplying immediate, relevant information for the current task.
In essence, a well-engineered prompt is the initial blueprint that directs an AI agent’s cognitive processes, enabling it to embark on its reasoning and action sequences.
2. Limitations of Prompt Engineering: The Enterprise Conundrum
Despite its foundational role, prompt engineering, when used in isolation, faces inherent limitations that become particularly pronounced in enterprise-scale AI deployments. The core challenge stems from the stateless nature of current LLMs: they process each prompt independently, lacking persistent memory across interactions.
2.1. Where Enterprises Struggle
Enterprises encounter several significant hurdles when relying solely on prompt engineering:
- Lack of Long-Term Memory: LLMs do not inherently “remember” past conversations, previous outputs, or historical context. This means that for multi-turn interactions or complex, ongoing tasks, vital information must be re-injected into every prompt, leading to redundancy and inefficiency.
- Context Window Constraints: Every LLM has a finite “context window” – a limit on the amount of text (tokens) it can process in a single input. As tasks become more complex and require more background information, enterprises struggle to fit all necessary context into a single prompt without exceeding this limit. This often necessitates truncation, leading to loss of critical information, or complex, multi-stage prompting that is difficult to manage.
- Inconsistent Behavior: Without a persistent memory, an AI agent’s responses can become inconsistent across different sessions or even within a long conversation if crucial context is not perfectly replicated in every prompt. This undermines reliability and trust in AI systems.
- Scalability Challenges: Managing and optimizing prompts for hundreds or thousands of distinct use cases across an enterprise becomes an arduous task. Each new scenario may require a unique prompt, leading to a sprawling and difficult-to-maintain prompt library.
- “Brilliant Interns with No Long-Term Memory”: As articulated in the provided document, LLMs are akin to “brilliant interns” who perform exceptionally well when given clear, constrained instructions and all necessary wisdom upfront. However, their lack of long-term memory means this “prepping” must be done repeatedly, consuming significant human effort and time.
2.2. Impact on Cost, Infrastructure, and ROI
The limitations of prompt engineering directly translate into tangible business impacts:
- Increased API Costs: Re-injecting historical context or extensive background information into every prompt significantly increases the number of tokens processed per interaction. This directly inflates API costs, as most LLM providers charge per token. For high-volume applications, this can lead to prohibitive operational expenses.
- Real-World Example: Consider an AI-powered customer service chatbot. If a customer has a complex issue that spans multiple turns, the chatbot needs to be reminded of the entire conversation history, previous customer details, and past interactions with the company in every single prompt. For a large enterprise handling millions of customer queries daily, this repetitive re-injection of context can lead to an exponential increase in token usage, driving up monthly API bills by hundreds of thousands or even millions of dollars, significantly impacting the ROI of the chatbot deployment.
- Infrastructure Strain and Latency: Larger prompts require more computational resources and time for the LLM to process. This can lead to increased latency in responses, degrading user experience, and necessitating more robust and expensive infrastructure to handle the load.
- Real-World Example: In a legal tech firm utilizing an AI for document analysis and case research, each new query about a specific case might require the LLM to be re-fed hundreds of pages of legal documents, precedents, and client notes. This not only consumes a large number of tokens but also increases the processing time for each query (latency). If legal professionals are waiting longer for AI responses, their productivity decreases, and the firm might need to invest in more powerful, expensive GPUs or higher-tier LLM services to meet performance demands, negating the initial cost-saving potential of the AI.
Diminished Return on Investment (ROI): If AI agents require constant human oversight to manage context, or if their performance is inconsistent due to memory gaps, the promised productivity gains and cost savings from AI adoption may not materialize. The effort spent on meticulous prompt engineering and re-prompting can outweigh the benefits, leading to a poor ROI.
3. The Next Frontier: Unblocking Limitations with Context Engineering
The challenges posed by prompt engineering’s inherent limitations highlight a critical gap in AI-native development. Instead of waiting for LLMs to develop true, robust long-term memory (a major AI research challenge), the industry is actively building systems around this gap. This proactive approach has given rise to Context Engineering as the next frontier.
Context Engineering is designed to overcome the memory limitations of prompt engineering by providing LLMs with the illusion of memory. It is not about teaching models to remember, but rather about teaching us how to communicate more effectively, albeit in a relatively inefficient manner, with high-leverage, stateless minds. It represents a shift from static, one-off prompt creation to a dynamic, system-level approach to information delivery.
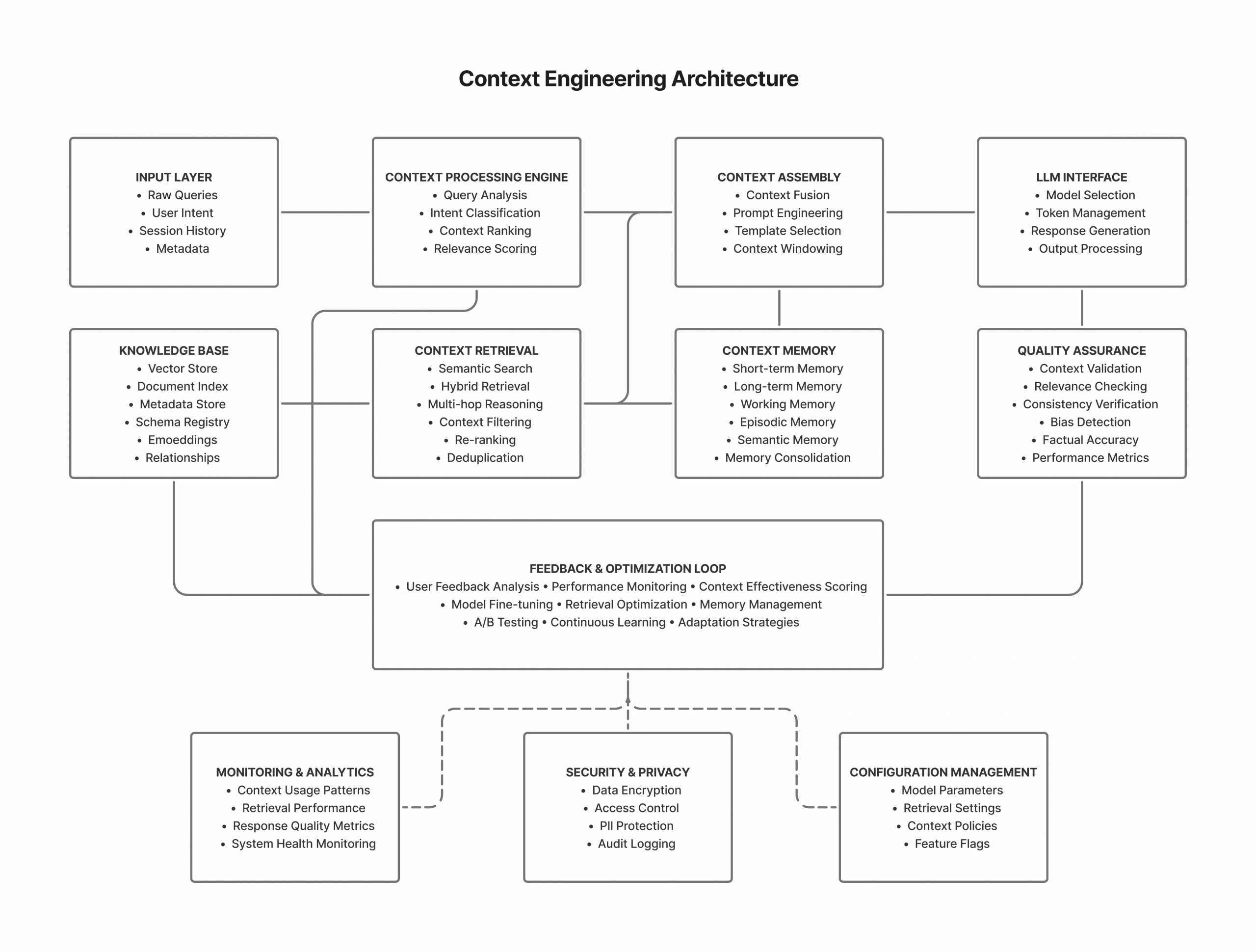
4. What is Context Engineering?
Context Engineering is defined as the strategic process of shaping, curating, and delivering relevant information to a language model at inference time, so it can behave more intelligently—without actually learning or remembering anything long-term. It’s about “tricking the LLM, with a lot of effort, into feeling like it remembers, by embedding the right context at the right time—without overwhelming its token window.”
This discipline extends beyond merely crafting prompts; it encompasses system design, repository architecture, and real-time tooling to ensure that the AI always has access to the most pertinent information for its current task.
4.1. Components of Context Engineering in AI Agents
The principles of Context Engineering are manifested through several key components that collectively form a “Knowledge-Ready Codebase” or operational environment for AI agents:
- Codified Rules & Guidance: Explicitly defined rules, policies, and best practices translated into a machine-readable format that can be easily accessed and understood by the LLM. This includes coding standards, architectural guidelines, or business logic.
- Actionable Knowledge Base: A structured repository of domain-specific knowledge, documentation, FAQs, and historical data that an AI agent can query and retrieve information from. This might involve internal wikis, technical specifications, or customer interaction logs.
- Pruned Dead Code & Bad Docs: Regularly cleaning up irrelevant, outdated, or erroneous code and documentation. A clean and concise codebase ensures that the LLM is not distracted by noise and can focus on truly relevant information.
- Enabling System Architecture: The underlying infrastructure and tooling that facilitates the efficient retrieval, processing, and injection of context into the LLM’s prompt. This includes vector databases, retrieval-augmented generation (RAG) systems, and context management frameworks.
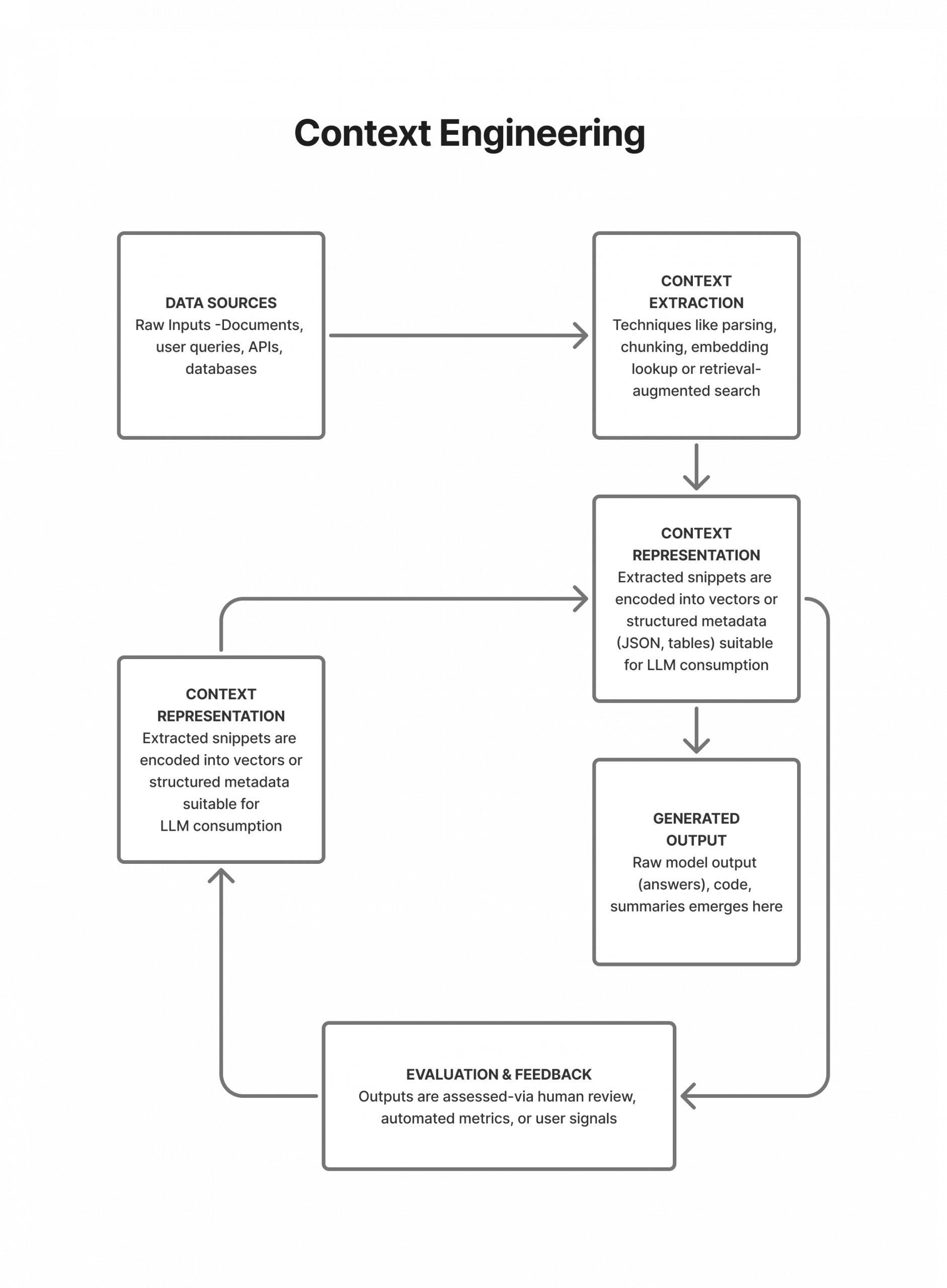
4.2. Conceptual Diagram of Context Engineering
The process can be visualized as a pipeline where various inputs are transformed into a “Knowledge-Ready Codebase” that feeds into AI-assisted operations, leading to significant productivity gains.
This diagram illustrates how various inputs (AI-Assisted Coding, AI PR Review, Enabling System Architecture) contribute to building a “Knowledge-Ready Codebase” through the integration of Codified Rules & Guidance, an Actionable Knowledge Base, and the pruning of Dead Code & Bad Docs. This refined codebase then serves as the essential context for AI Pair Programming, ultimately leading to significant productivity gains.
5. Real-World Applications of Context Engineering in Enterprises
Enterprises are increasingly adopting Context Engineering principles, often integrated within specialized AI development tools and workflows. These examples demonstrate how relevant information is dynamically provided to LLMs to enhance their performance:
- Code Assistants: Tools like Cursor and Claude Code implement sophisticated context stacking. Cursor uses “thread-local + repo-aware context stacking” to ensure the AI understands the specific file, function, or even line of code a developer is working on, along with relevant repository-wide information. Claude Code utilizes claude.md files as a “persistent summary of dev history,” allowing the AI to recall past decisions and architectural choices relevant to the current task.
- Automated PR Review: AI systems performing Pull Request (PR) reviews leverage context engineering by feeding the LLM not just the code changes, but also the project’s coding standards, architectural patterns, relevant issue tickets, and even the history of previous PRs. This enables the AI to provide more intelligent and contextually appropriate feedback.
- Prompt-Engineered PRDs (Product Requirement Documents): By placing detailed, prompt-engineered PRDs directly alongside source files, development teams ensure that the LLM has immediate access to the design intent, user stories, and technical specifications when generating code or performing tasks related to that feature.
- Custom Evaluation and Test Suites: Piped into the session as “scaffolding,” these suites provide real-time feedback and constraints to the LLM. For instance, an AI agent generating code might receive immediate feedback from a unit test, allowing it to iteratively refine its output based on the test results, effectively using the test suite as context for improvement.
- Vector Stores / RAG / MCP Servers: These technologies act as “external memory prosthetics.” Enterprises use vector databases to store embeddings of vast amounts of unstructured data (e.g., internal documents, customer support transcripts, research papers). When an LLM needs information, a Retrieval-Augmented Generation (RAG) system queries the vector store for semantically similar documents, retrieves the most relevant snippets, and injects them into the LLM’s prompt. This allows the LLM to access and synthesize information far beyond its original training data or current context window.
These examples illustrate that Context Engineering is not a theoretical concept but a practical, evolving discipline actively being implemented to make AI systems more capable and aligned with enterprise needs.
6. Current Limitations of Context Engineering and Its Impact
While Context Engineering offers a powerful solution to the memory limitations of LLMs, it is not without its own set of challenges and implications, particularly concerning cost and complexity. It is still in a nascent state of its execution, requiring significant ongoing effort.
6.1. Current Limitations
- “Constant Time and Effort Commitment”: The most significant limitation is the inherent manual overhead. Curating, structuring, and maintaining the “Knowledge-Ready Codebase” requires continuous human effort. Ensuring that codified rules are up-to-date, knowledge bases are accurate, and dead code is pruned is an ongoing operational burden.
- “Relatively Inefficient Manner”: The process of context retrieval and injection, though optimized, is still a workaround. It adds layers of complexity and potential points of failure compared to an LLM with true, integrated long-term memory. This inefficiency can manifest in increased latency or resource consumption.
- Context Overload and Noise: While aiming to prevent overwhelming the token window, poorly implemented context engineering can still suffer from “context overload.” If too much or irrelevant information is injected, it can dilute the LLM’s focus, lead to hallucination, or increase processing time and cost. Determining the optimal amount and most relevant context remains a challenge.
- Complexity of System Integration: Implementing robust context engineering solutions often requires integrating multiple systems: LLM APIs, vector databases, knowledge management systems, code repositories, and custom context-aware tooling. This integration can be complex, requiring specialized engineering expertise.
- Dynamic Context Challenges: For highly dynamic environments where context changes rapidly (e.g., real-time data streams, rapidly evolving codebases), keeping the context up-to-date and instantly available to the LLM is a significant technical hurdle.
6.2. Impact on Cost of Tokens, Infrastructure, and Computation
Despite its benefits, Context Engineering introduces its own set of cost implications:
- Token Cost (Optimized vs. Absolute): While context engineering aims to optimize the relevance of tokens sent to the LLM (reducing redundant information), it still involves sending more tokens than a simple prompt. The cost shifts from sending all history to sending relevant history, which can still be substantial, especially with verbose knowledge bases.
- Infrastructure Costs:
- Storage: Maintaining large knowledge bases, vector stores, and structured data for context requires significant storage infrastructure.
- Compute for Retrieval: Vector similarity search, data processing, and context assembly (e.g., RAG pipeline execution) demand dedicated computational resources, adding to infrastructure expenses.
- Computation and Latency: The retrieval and preparation of context before it’s sent to the LLM introduces additional computational steps and potential latency. This can impact the responsiveness of AI agents, especially in real-time applications. Optimizing these pipelines for speed and efficiency is crucial but adds to the engineering effort and cost.
Development and Maintenance Costs: The initial development of context engineering pipelines, along with ongoing maintenance, monitoring, and refinement of context sources, represents a substantial investment in engineering resources. This “constant time and effort commitment” translates directly into operational expenditure.
7. Comparative Analysis: Prompt Engineering vs. Context Engineering
To further delineate the value proposition of Context Engineering, a direct comparison with traditional Prompt Engineering is essential:
| Attribute | Prompt Engineering | Context Engineering |
|---|---|---|
| Primary Goal | Guide LLM behavior within a single, isolated interaction. | Enable LLM to behave more intelligently by providing relevant, dynamic information, mimicking memory. |
| Information Scope | Limited to the current prompt’s context window. | Extends beyond the current prompt; leverages external knowledge bases and dynamic retrieval. |
| Information Delivery | Information directly embedded and manually managed within the prompt. | Information curated, structured, and delivered dynamically from external sources/systems. |
| Addressing LLM Memory | Does not address the LLM’s lack of long-term memory. | Works around the LLM’s lack of long-term memory by providing “external memory prosthetics.” |
| Complexity | Can be simple for basic tasks; becomes complex for nuanced or multi-turn interactions due to repetition. | Involves sophisticated system design, data architecture, and real-time tooling. |
| Effort | Focus on crafting effective, often repetitive, prompts. | “Constant time and effort commitment” to optimize context sources and delivery mechanisms. |
| Scalability | Limited scalability for complex, evolving, or multi-turn tasks without significant manual overhead. | Designed for greater scalability by automating context retrieval and management. |
| Cost Implications | High token cost for repetitive context; lower infrastructure for simple use cases. | Potentially higher infrastructure and development costs for context management; optimized token cost for relevant context. |
| Typical Use Cases | Simple Q&A, single-turn tasks, basic content generation. | AI agents, complex coding assistants, automated PR reviews, knowledge retrieval systems. |
| Productivity Impact | Good for specific, well-defined tasks. | Aims for “significant productivity gains” by enabling more autonomous and intelligent AI behavior. |
8. Best Practices for Implementing Context Engineering
To maximize the benefits of Context Engineering and mitigate its challenges, enterprises should adhere to several key best practices:
| Best Practice | Advantage |
|---|---|
| 1. Knowledge-Ready Codebase | Foundation for AI: Ensures the LLM always has access to the most accurate and up-to-date information directly from the source. |
| 1.1 Codify Rules & Guidance | Provides consistent, explicit instructions and guardrails to the LLM, reducing ambiguity and improving predictability of AI behavior. |
| 1.2 Create an Actionable Knowledge Base | Centralizes valuable domain-specific information, making it easily queryable and leverageable by AI agents, reducing reliance on manual input. |
| 1.3 Prune Dead Code & Bad Docs | Reduces noise and irrelevant information, improving the signal-to-noise ratio for the LLM, leading to more accurate and focused outputs. |
| 2. Strategic Context Stacking | Optimized Context: Ensures only the most relevant information is provided, preventing context overload and optimizing token usage. |
| 2.1 Thread-local Context | Provides highly specific context relevant to the immediate conversation or task, maintaining conversational flow. |
| 2.2 Repo-aware Context | Injects broader project or repository-level information, giving the AI a comprehensive understanding of the codebase. |
| 3. External Memory Prosthetics (RAG) | Scalable Knowledge: Enables LLMs to access and synthesize information from vast, dynamic external data sources beyond their training data. |
| 3.1 Vector Stores | Efficiently indexes and retrieves semantically similar information, crucial for large knowledge bases. |
| 3.2 Retrieval-Augmented Generation (RAG) | Combines retrieval with generation, ensuring the LLM’s responses are grounded in factual, current information. |
| 4. Iterative Refinement & Monitoring | Continuous Improvement: Allows for ongoing optimization of context sources and delivery mechanisms based on AI performance and user feedback. |
| 4.1 Custom Eval & Test Suites | Provides real-time feedback to the LLM, guiding it towards more accurate and robust outputs and enabling automated validation. |
| 4.2 Performance Metrics | Track token usage, latency, and output quality to identify bottlenecks and areas for optimization. |
| 5. Modular and Extensible Architecture | Flexibility & Future-Proofing: Designs context pipelines that can easily integrate new data sources, LLM versions, or tools. |
| 6. Security and Data Governance | Trust & Compliance: Ensures sensitive information is handled securely and in compliance with regulations (e.g., PII filtering, access controls). |
9. The Future of Context Engineering
Context Engineering is a rapidly evolving field, poised to become an even more central tenet of AI-native development. Its future trajectory is likely to involve increased automation, intelligence, and integration, moving closer to providing LLMs with a more seamless and efficient form of “external memory.”
9.1. Critical Challenges to Overcome for Mainstream Adoption
For Context Engineering to become truly mainstream, several critical challenges must be addressed:
- Automation of Context Curation: The “constant time and effort commitment” needs to be significantly reduced. Future solutions must automate the identification, extraction, structuring, and updating of relevant context from diverse and dynamic data sources. This includes automated summarization, entity extraction, and knowledge graph construction.
- Intelligent Context Selection: Moving beyond simple keyword or semantic similarity, future systems need to develop more sophisticated reasoning to determine which context is truly relevant for a given query and how much of it is optimal. This involves understanding user intent, task complexity, and historical interaction patterns.
- Real-time Context Updates: For applications requiring immediate access to the latest information (e.g., financial trading, real-time diagnostics), ensuring that context sources are updated and propagated instantly to the LLM pipeline without significant latency is a major technical hurdle.
- Cost Efficiency at Scale: While optimizing token usage, the underlying infrastructure and computational demands of advanced context engineering (e.g., large vector databases, complex RAG pipelines) can still be substantial. Innovations in efficient data indexing, retrieval algorithms, and model serving will be crucial for cost reduction at enterprise scale.
- Standardization and Interoperability: The current landscape is fragmented, with various tools and approaches to context management. Developing industry standards for context representation, exchange, and integration will foster greater interoperability and accelerate adoption.
- Explainability and Debugging: As context pipelines become more complex, understanding why an LLM produced a particular output based on the context it received becomes challenging. Enhanced observability, logging, and debugging tools are needed to trace context flow and identify issues.
- Bridging the Gap to True Memory: While context engineering is a workaround, ongoing research into LLM architectures that incorporate more robust, long-term memory mechanisms could eventually reduce the reliance on external context injection, or at least simplify its implementation.
10. Conclusion
Context Engineering stands as a pivotal design concept in the burgeoning AI-native world. It directly confronts the fundamental limitation of current LLMs—their lack of long-term memory—by intelligently providing them with the necessary information at the point of inference. This paradigm shift from static prompt engineering to dynamic context management is unlocking unprecedented levels of intelligence and productivity from AI agents.
While still in its nascent stages, with challenges related to automation, cost, and complexity, the trajectory of Context Engineering is clear. As enterprises continue their journey towards AI adoption, mastering the art and science of shaping, curating, and delivering context will be paramount. The future promises more intelligent, automated, and seamlessly integrated context solutions, further blurring the lines between an LLM’s inherent capabilities and its extended knowledge, ultimately driving the next wave of innovation in AI.
11. References
- “Context Engineering: quietly becoming one of the most important design problems in AI-native development.” (Internal Document/Uploaded File)
- NStarX Inc. Official Website
- Additional references would be listed here if external research was conducted for specific examples, metrics, or industry reports.