
In today’s hyper-competitive artificial intelligence landscape, LLM inference latency has emerged as the decisive battleground separating market leaders from also-rans. As enterprises race to deploy large language models at scale—powering conversational AI, coding copilots, enterprise automation, and multimodal applications—one metric towers above all others: response time.
The stakes couldn’t be higher. Users now expect AI-powered applications to respond in under 200 milliseconds, mirroring the responsiveness of fast websites and mobile applications[1]. Yet even state-of-the-art models like GPT-4 or Llama-70B can take agonizing seconds to respond without proper optimization. This performance gap translates directly into business consequences: speed influences user retention, latency determines customer satisfaction, slow responses crush engagement, and higher inference time means escalating infrastructure costs[2].
Amazon’s legendary finding that 100 milliseconds of latency costs 1% of sales underscores a universal truth: in AI-driven products where users expect “instant intelligence,” latency optimization becomes the deciding factor between market adoption and abandonment.
Understanding What Drives LLM Inference Latency
Before diving into optimization strategies, it’s crucial to understand the anatomy of LLM latency. Several interconnected components contribute to total response time:
Time to First Token (TTFT) represents the critical delay before any output appears—the moment that shapes perceived responsiveness. Token generation speed, typically measured at 30-70 tokens per second in optimized systems, determines overall throughput[3]. Queue time introduces delays when concurrent requests compete for scarce GPU resources, while model loading time adds overhead from initializing massive models in memory. Finally, network latency contributes data transfer delays between distributed services.
Counterintuitively, the speed at which data—weights, keys, values, and activations—transfers to the GPU from memory dominates latency far more than raw computation speed, making LLM inference fundamentally a memory-bound operation. Since average human visual reaction time hovers around 200 milliseconds, keeping time-to-first-token below this threshold makes systems feel instantaneously responsive, transforming user experience from frustrating to delightful.
Strategy 1: GPU Batching—Unlocking Massive Throughput Gains
GPU batching represents perhaps the single most impactful optimization technique for production LLM deployments. Rather than processing inference requests sequentially, batching enables systems to process multiple requests simultaneously on a single GPU, grouping inputs into unified GPU passes that dramatically improve hardware utilization.
The evolution from static batching to continuous batching marked a watershed moment in LLM serving efficiency. While static batching uses fixed time windows or batch sizes, continuous batching can admit new requests dynamically as others process, with the most advanced in-flight batching techniques processing sequences at different stages within the same batch[4].
The performance results speak volumes. Research demonstrates that frameworks like vLLM achieved up to 23× throughput improvement while significantly reducing P50 latency through continuous batching[1]. Anthropic’s optimization of Claude 3 showcases the multiplicative benefits: continuous batching increased throughput from 50 to 450 tokens per second, lowered latency from 2.5 to 0.8 seconds, slashed GPU costs by 40%, and improved user satisfaction by 25%[5].
NVIDIA’s research on NIM microservices demonstrates that combining continuous batching with in-flight batching techniques achieves 2.5× throughput improvement and 4× faster TTFT for Llama 3.1 8B Instruct models[6]. However, careful tuning remains essential: using one NVIDIA A100 GPU, increasing batch size to 64 can boost throughput by 14× but simultaneously raises latency by 4×[7].
GPU batching proves most valuable for high concurrent request volumes exceeding 100 requests per minute, variable traffic patterns, cloud or large-scale deployments, and applications prioritizing throughput alongside latency.
Strategy 2: Model Quantization—Enabling Cost-Effective Deployment
Model quantization reduces the numerical precision of model weights and activations—transitioning from FP32 to FP16 to INT8 to INT4—thereby decreasing model size, memory bandwidth requirements, and computational overhead. This technique delivers 2–4× faster inference, 4–8× lower VRAM usage, and enables deployment on cheaper hardware or edge devices[8].
Popular quantization methods include GPTQ for post-training quantization that maintains accuracy, AWQ for activation-aware weight quantization, GGUF/GGML formats optimized for CPU inference, and mixed-precision approaches using different precision levels for different layers[9].
Real-world validation confirms quantization’s power: a 4-bit GPTQ quantized version of Llama-3.3-70B demonstrated nearly identical MMLU zero-shot accuracy compared to the FP16 version while reducing model size from approximately 141 GB to just 39.8 GB[10]. Comprehensive benchmarking across Qwen2.5, DeepSeek, Mistral, and LLaMA 3.3 found that Q5_K_M and GPTQ-INT8 formats offer optimal trade-offs for most domains, with Mistral-7B-Instruct maintaining performance within 2% of BF16 across most tasks even under 8-bit quantization[11].
However, organizations must navigate critical trade-offs. Research reveals that 4-bit quantization can lead to quality degradation on long-context tasks[12], while INT4 quantization studies show negligible accuracy degradation for encoder-only and encoder-decoder models but significant drops for decoder-only models[13]. Self-hosting with quantization can achieve approximately 90% cost savings compared to hosted APIs when optimized for prefill-heavy scenarios[14].
Strategy 3: Async Execution—Eliminating Pipeline Bottlenecks
Asynchronous execution overlaps operations that would otherwise run sequentially—CPU-GPU communication, tokenization, inference, and post-processing execute concurrently, dramatically reducing total wall-clock time by 20–70% in production pipelines[15].
Key async patterns include request-level asynchrony using non-blocking I/O and async/await patterns, pipeline parallelism where tokenization runs while previous tokens decode, speculative decoding that generates multiple token candidates in parallel, and streaming output that returns tokens immediately as generated[16].
MLC Engine’s architecture demonstrates the power of async design: by driving the engine loop with a standalone thread while leaving frontend request processes on another thread, the system enables asynchronous processing with CPU overhead counting toward just 3% of batch decoding time[17]. PipeInfer, using continuous asynchronous speculation and early inference cancellation, achieved up to 1.5× improvement in generation speed over standard speculative inference[18].
Real-world applications showcase async execution’s transformative potential. DoorDash built a RAG-based support system handling thousands of daily requests, reducing hallucinations by 90% and compliance issues by 99%[19]. Complex retrieval-plus-generation pipelines using async execution patterns reduced latency from 6–8 seconds sequential processing to 2–3 seconds[20].
Real-World Applications
RAG Pipeline Optimization: Doordash built a RAG-based support system that handles thousands of daily requests, strategically defaulting to human agents when latency becomes an issue. Their system reduced hallucinations by 90% and compliance issues by 99%.
Complex Workflows: DXC Technology developed an LLM-powered AI assistant for oil and gas data exploration, significantly reducing analysis time by routing queries to specialized tools optimized for different data types, accelerating time to first oil.
When Async Execution Delivers Maximum Value
High-impact scenarios:
- Multi-step AI pipelines (RAG, agent workflows)
- Applications with external API calls or database queries
- Systems with complex preprocessing requirements
- Real-time applications requiring immediate user feedback
Strategy 4: Dynamic Routing—Intelligent Compute Allocation
Dynamic routing directs inference requests to different models or compute resources based on query complexity, latency requirements, user tier, or current system load. This intelligent orchestration enables organizations to route simple queries to faster, smaller models while reserving expensive, powerful models for genuinely complex tasks[21].
The RouteLLM framework demonstrates remarkable cost reductions: over 85% on MT Bench, 45% on MMLU, and 35% on GSM8K compared to using only GPT-4, while achieving 95% of GPT-4’s performance[22]. When routing between GPT-4 and Mixtral 8x7B, RouteLLM achieved cost savings of approximately 3.66× compared to random baseline with 50% cost-performance threshold[23].
Research shows that LLM routers can achieve the same performance as baselines with up to 70% cost reduction on MT Bench, 30% on MMLU, and 40% on GSM8K[24]. A hybrid query routing system that only invoked an LLM for complex analytical tasks reduced overall LLM usage by 37–46% and improved latency by 32–38% for simpler queries, translating to 39% reduction in AI processing costs while successfully answering all queries[25].
Production implementations validate the approach: Bito, an AI coding assistant, built a multi-LLM orchestration system intelligently routing requests across OpenAI, Anthropic, and Azure while selecting models based on context size, cost, and performance[26].
Real-World Implementation
Bito, an AI coding assistant, built a multi-LLM orchestration system to handle API rate limits and ensure high availability, intelligently routing requests across providers like OpenAI, Anthropic, and Azure, while selecting models based on context size, cost, and performance.
Adyen, a global fintech platform, enhanced its support operations by deploying a smart ticket routing system powered by LLMs, resulting in improved ticket routing accuracy and faster response times through automated document retrieval and answer suggestions.
When Dynamic Routing Creates Competitive Advantage
High-value scenarios:
- Applications with highly variable query complexity
- Multi-tier service models (free, premium, enterprise)
- Cost-sensitive, high-volume deployments
- Systems requiring graceful degradation under load
The Multiplicative Effect: Combining Strategies for Maximum Impact
The most sophisticated production deployments combine all four strategies, creating multiplicative benefits that transform business outcomes. NVIDIA research highlighted that optimized batch processing can boost throughput by 26% for the GPT-3 175B model on an A100 GPU—processing 1.2 million tokens per second while cutting latency[27]. When organizations layer quantization atop batching, add async execution, and implement intelligent routing, the cumulative effect dramatically exceeds individual optimizations.
Implementation Roadmap: From Zero to Optimized in 12 Weeks
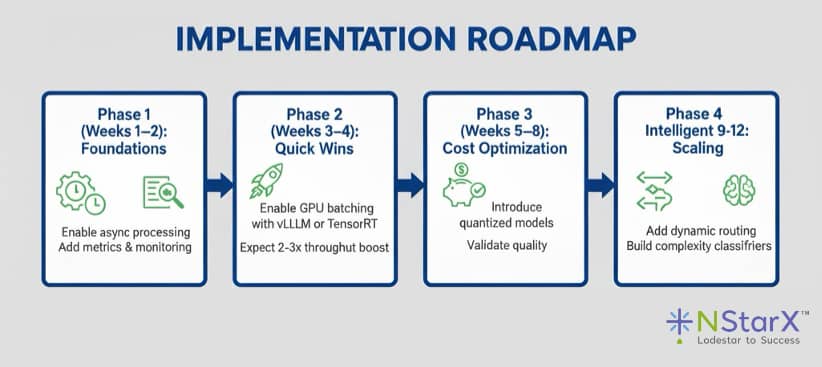
Successfully implementing LLM latency optimization requires a systematic, phased approach that balances quick wins with sustainable long-term improvements. This roadmap guides organizations from initial assessment through full-scale production optimization.
Phase 1: Foundation and Assessment (Weeks 1-2)
The foundation phase establishes critical infrastructure for measuring, monitoring, and understanding your current LLM performance baseline. Begin by instrumenting your existing inference pipeline with comprehensive observability tooling that captures time-to-first-token, tokens-per-second, end-to-end latency, queue times, and GPU utilization metrics[28].
Week 1 Activities:
- Deploy monitoring infrastructure using tools like Prometheus, Grafana, or specialized LLM observability platforms
- Instrument all inference endpoints to capture P50, P95, and P99 latency distributions
- Document current request patterns: traffic volume, query complexity distribution, peak load characteristics
- Establish baseline performance metrics across different query types and user segments
- Audit current infrastructure: GPU types, memory configurations, network topology, service dependencies[3]
Week 2 Activities:
- Enable async processing patterns in your application layer using async/await paradigms
- Refactor synchronous API calls to non-blocking I/O operations
- Implement request queuing mechanisms to handle burst traffic
- Set up A/B testing infrastructure for comparing optimization strategies
- Create dashboards visualizing latency distributions, throughput trends, and resource utilization[15]
Organizations that skip this foundational phase often struggle to validate optimization impact or identify performance regressions. Comprehensive metrics enable data-driven decision-making throughout the optimization journey[28].
Phase 2: Quick Wins with GPU Batching (Weeks 3-4)
GPU batching delivers the most dramatic immediate performance improvements with relatively low implementation complexity. This phase focuses on deploying continuous batching frameworks that can yield 2-3× throughput gains within days[1].
Week 3 Implementation:
- Evaluate batching frameworks: vLLM for general-purpose deployments, TensorRT-LLM for NVIDIA-optimized inference, or Text Generation Inference (TGI) for Hugging Face models
- Deploy your chosen framework in a staging environment
- Configure initial batch size parameters conservatively (start with batch sizes of 8–16)
- Run load testing comparing batched vs. non-batched inference
- Measure impact on both throughput and latency across different batch sizes[4]
Week 4 Optimization:
- Fine-tune batch size parameters based on your specific latency requirements and traffic patterns
- Implement request prioritization: latency-sensitive requests get smaller batch slots, throughput-focused requests can wait for larger batches
- Configure timeout parameters to prevent long-tail latency degradation
- Deploy continuous batching to production with gradual traffic rollout (10% → 25% → 50% → 100%)
- Monitor for regressions in user-facing latency metrics[29]
Research shows that properly configured continuous batching can reduce infrastructure costs by 40% while simultaneously improving user experience—a rare win-win in performance optimization[5]. However, organizations must carefully balance batch size against latency tolerance: larger batches maximize throughput but increase per-request latency[7].
Phase 3: Cost Optimization Through Quantization (Weeks 5-8)
Quantization reduces operational costs while maintaining model quality, but requires rigorous validation to avoid quality degradation. This phase introduces quantized model variants with comprehensive quality assurance processes[8].
Week 5-6: Model Selection and Validation:
- Identify quantization candidates: start with models where inference costs are highest
- Download or create quantized model variants: GPTQ-INT8 for minimal quality loss, Q5_K_M for balanced trade-offs, or INT4 for maximum compression[11]
- Establish quality validation methodology: benchmark quantized models against your specific use cases, not just generic benchmarks
- Create evaluation datasets representing real production queries across different complexity levels
- Run comprehensive quality comparisons measuring accuracy, coherence, factuality, and domain-specific performance[12]
Week 7: Production Testing:
- Deploy quantized models in shadow mode: serve quantized responses alongside full-precision responses without exposing to users
- Implement automated quality monitoring comparing quantized vs. full-precision outputs
- Analyze quality degradation patterns: identify query types where quantization impacts quality
- Calculate cost savings potential based on reduced memory footprint and faster inference[14]
Week 8: Gradual Rollout:
- Begin serving quantized models to non-critical traffic segments
- Implement fallback mechanisms: automatically route to full-precision models if quality drops below thresholds
- Monitor user satisfaction metrics: response quality ratings, task completion rates, user retention
- Scale quantized model usage based on quality validation results
- Document which model variants work best for different query types[10]
Studies demonstrate that Q5_K_M and GPTQ-INT8 quantization maintain performance within 2% of full-precision models for most tasks while delivering 2-4× inference speedups and 4-8× memory savings[11]. However, organizations must remain vigilant about quality on long-context tasks where 4-bit quantization can cause degradation[12].
Phase 4: Intelligence Layer with Dynamic Routing (Weeks 9-12)
Dynamic routing represents the most sophisticated optimization strategy, directing requests intelligently across model tiers to optimize the cost-quality-latency tradeoff. This phase builds the intelligence layer that makes your inference infrastructure truly adaptive[21].
Week 9-10: Routing Strategy Design:
- Analyze query complexity distribution: classify historical queries by difficulty, context length, reasoning requirements
- Design routing tiers: fast/cheap models for simple queries, mid-tier models for moderate complexity, premium models for complex reasoning
- Implement query classification: use lightweight models or rule-based systems to predict query complexity before inference
- Establish routing policies: define which query types route to which models based on cost, latency, and quality requirements[24]
Week 11: Framework Integration:
- Deploy routing framework such as RouteLLM or build custom routing logic
- Integrate with existing inference infrastructure: ensure routing layer doesn’t become a bottleneck
- Implement confidence scoring: route to more powerful models when cheaper models express uncertainty
- Configure cascading fallback: start with small models, escalate to larger models if confidence is low
- Set up cost tracking per request to validate economic impact[22]
Week 12: Production Optimization:
- Deploy routing to production with continuous monitoring
- Implement adaptive routing: adjust routing thresholds based on current system load and cost targets
- Track key metrics: cost per request, average model tier usage, quality satisfaction rates
- Optimize routing policies based on production data: refine classification rules, adjust tier boundaries
- Document cost savings and quality impact across different user segments[25]
Production implementations demonstrate that routing can reduce costs by 40-85% while maintaining 95% of top-model quality[22]. Organizations serving diverse query types see the most dramatic benefits, as routing enables precise matching of computational resources to task requirements[26].
Advanced Optimization Strategies
Beyond the core roadmap, advanced organizations can implement additional optimizations that compound the benefits of the four primary strategies.
Speculative Decoding: Generates multiple token candidates in parallel, then validates them against the full model. This technique can improve generation speed by 1.5–2× for appropriate workloads, particularly benefiting applications requiring low latency over maximum throughput[18].
KV Cache Optimization: Reduces memory bandwidth requirements by efficiently managing the key-value cache used in autoregressive generation. Techniques like paged attention in vLLM enable more efficient memory usage, allowing larger batch sizes and higher throughput[29].
Multi-Model Serving: Deploys multiple model variants simultaneously—quantized versions for high-throughput scenarios, full-precision for quality-critical requests, and specialized fine-tuned models for domain-specific queries. This approach maximizes infrastructure utilization while meeting diverse performance requirements[7].
Measuring Success: Key Performance Indicators
Effective optimization requires tracking the right metrics throughout implementation:
Performance Metrics:
- Time-to-First-Token (P50, P95, P99 distributions)
- Tokens-per-Second throughput
- End-to-end request latency
- GPU utilization and memory efficiency[3]
Business Metrics:
- Cost-per-1000-tokens across model tiers
- Infrastructure cost reduction percentage
- User satisfaction and retention rates
- Query success rates and quality scores[28]
Quality Metrics:
- Task-specific accuracy benchmarks
- Human evaluation scores
- Automated quality monitoring alerts
- Regression detection on critical use cases[11]
Organizations should establish clear success criteria before optimization begins, ensuring that performance improvements translate to measurable business value rather than vanity metrics that don’t impact user experience or costs.
Conclusion: Latency as Strategic Differentiator
The evidence is unambiguous: LLM latency optimization directly determines business outcomes in 2025 and beyond. Organizations that master these four strategies—GPU batching, model quantization, async execution, and dynamic routing—will establish compounding advantages: superior user experiences driving higher engagement, lower costs enabling competitive pricing, faster innovation cycles, and institutional expertise becoming organizational capability.
The competitive landscape is rapidly evolving. As next-generation models process text, images, video, and audio simultaneously, computational requirements will increase by 10–100×, making optimization existential rather than optional[2]. AI agents executing multi-step workflows will make latency compound across each step—a 10-step agent workflow with 2 seconds per step creates an unusable 20-second experience, but at 200ms per step delivers a responsive 2-second interaction that transforms user engagement[15].
Over the next 3–5 years, LLM latency optimization will transition from specialized expertise to fundamental infrastructure requirement. User expectations are compressing: today’s “acceptable” 1–2 second threshold will become 200–500ms, then eventually sub-100ms for many applications. Privacy regulations and data sovereignty requirements are driving inference closer to users, making quantization and efficiency techniques prerequisites for market participation[8].
The latency wars have begun. Success belongs to organizations that recognize optimization not as technical minutiae but as business imperative, establishing latency as a first-class metric alongside accuracy and cost, building internal optimization capabilities or partnering with specialized providers, implementing continuous optimization processes, and future-proofing architectures to incorporate emerging techniques.
In this high-stakes battle where milliseconds determine market leadership, the gap between optimized and non-optimized systems will widen dramatically as user expectations compress and model complexity increases. The question is no longer whether to optimize LLM inference, but how quickly your organization can implement these proven strategies to capture competitive advantage.
Energy consumption regulations will increasingly penalize inefficient AI deployments, creating both direct costs through electricity and carbon taxes, and reputational risks from inefficient resource utilization[2]. Organizations that build optimization capabilities today will find themselves not just with better-performing products, but with sustainable, cost-effective infrastructure that can scale as AI becomes increasingly central to business operations.
The roadmap is clear, the tools are available, and the business case is compelling. Organizations that act decisively on latency optimization in 2025–2026 will establish market positions that become increasingly difficult to challenge as the technology landscape evolves and user expectations continue their relentless compression toward instant AI intelligence.
References
- Cade Daniel, Chen Shen, Eric Liang & Richard Liaw. “How continuous batching enables 23× throughput in LLM inference while reducing P50 latency.” Anyscale blog, June 22, 2023.
https://www.anyscale.com/blog/continuous-batching-llm-inference
- “Ultimate Guide to LLM Inference Optimization.” Latitude Blog, June 6, 2025.
https://latitude-blog.ghost.io/blog/ultimate-guide-to-llm-inference-optimization
- “LLM Inference Performance Engineering: Best Practices.” Databricks Blog.
https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices
- “A practical guide to continuous batching for LLM inference.” Hivenet blog, October 17, 2025.
https://compute.hivenet.com/post/continuous-batching-explained
- “Scaling LLMs with Batch Processing: Ultimate Guide.” Latitude Blog, February 21, 2025.
https://latitude-blog.ghost.io/blog/scaling-llms-with-batch-processing-ultimate-guide/
- “Optimizing Inference Efficiency for LLMs at Scale with NVIDIA NIM Microservices.” NVIDIA Technical Blog, August 22, 2024.
Optimizing Inference Efficiency for LLMs at Scale with NVIDIA NIM Microservices
- “Best practices to accelerate inference for large-scale production workloads.” Together.ai guide, November 6, 2025.
https://www.together.ai/guides/best-practices-to-accelerate-inference-for-large-scale-production-workloads
- “LLM Quantization: Making models faster and smaller.” MatterAI Blog, May 13, 2025.
https://www.matterai.so/blog/llm-quantization
- “A Visual Guide to Quantization.” Maarten Grootendorst Newsletter, July 22, 2024.
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization
- Satwik11. “Llama-3.3-70B-Instruct-AutoRound-GPTQ-4bit.” Hugging Face model card.
https://huggingface.co/Satwik11/Llama-3.3-70B-Instruct-AutoRound-GPTQ-4bit
- “Benchmarking Quantized LLMs: What Works Best for Real Tasks?” Ionio.ai, 2024.
https://www.ionio.ai/blog/llm-quantize-analysis
- Mekala, Atmakuru, Song, Karpinska & Iyyer. “Does quantization affect models’ performance on long-context tasks?” arXiv preprint, May 2025.
https://arxiv.org/abs/2505.20276
- “Understanding INT4 Quantization for Transformer Models: Latency Speedup, Composability, and Failure Cases.” arXiv, January 27, 2023.
https://arxiv.org/abs/2301.12017
- “[Part 1] Optimizing LLM inference: A practical guide with vLLM, Quantization and Google GPUs.” Medium, November 2024.
https://medium.com/@injae.kwak/part-1-optimizing-llm-inference-a-practical-guide-with-vllm-quantization-and-google-cloud-gpus-tpus-30521202d15b
- “GPU Scheduling for Large-Scale Inference: Beyond ‘More GPUs’.” James Fahey, Medium blog.
https://medium.com/@fahey_james/gpu-scheduling-for-large-scale-inference-beyond-more-gpus-dcac81f952a2
- “Optimizing OpenAI API Performance – Reducing Latency.” SigNoz guide, October 2, 2024.
https://signoz.io/guides/open-ai-api-latency/
- “Optimizing and Characterizing High-Throughput Low-Latency LLM Inference in MLCEngine.” MLC Blog, October 10, 2024.
https://blog.mlc.ai/2024/10/10/optimizing-and-characterizing-high-throughput-low-latency-llm-inference
- “PipeInfer: Accelerating LLM Inference using Asynchronous Pipelined Speculation.” arXiv, July 16, 2024.
https://arxiv.org/html/2407.11798v1
- “LLMOps in Production: 457 Case Studies of What Actually Works.” ZenML Blog.
https://www.zenml.io/blog/llmops-in-production-457-case-studies-of-what-actually-works
- “Strategies for Optimal Performance of RAG.” Bijit Ghosh, Medium, June 23, 2024.
https://medium.com/@bijit211987/strategies-for-optimal-performance-of-rag-6faa1b79cd45
- “Doing More with Less – Implementing Routing Strategies in Large Language Model-Based Systems: An Extended Survey.” arXiv, February 4, 2025.
https://arxiv.org/html/2502.00409v2
- “RouteLLM: An Open-Source Framework for Cost-Effective LLM Routing.” LMSYS Org, July 1, 2024.
https://lmsys.org/blog/2024-07-01-routellm/
- “RouteLLM GitHub Repository.” lm-sys/RouteLLM.
https://github.com/lm-sys/RouteLLM
- “Choosing the Right LLM for the Job with LangDB’s Dynamic Routing.” LangDB Blog, January 22, 2025.
https://blog.langdb.ai/choosing-the-right-llm-for-the-job-with-langdb
- “Saving costs with LLM Routing: The art of using the right model for the right task.” Pondhouse Data.
https://www.pondhouse-data.com/blog/saving-costs-with-llm-routing
- “Intelligent LLM Routing in Enterprise AI: Uptime, Cost Efficiency, and Model Selection.” Requesty Blog.
https://www.requesty.ai/blog/intelligent-llm-routing-in-enterprise-ai-uptime-cost-efficiency-and-model
- “Mastering LLM Techniques: Inference Optimization.” NVIDIA Technical Blog, November 17, 2023.
- “🚀 LLM Inference Deep Dive: Metrics, Batching & GPU Optimization.” Machine Learners Guide.
https://muhtasham.github.io/blog/posts/batching-strategies/index.html
- “How to optimize inference speed using batching, vLLM, and UbiOps.” Medium blog, May 16, 2024.
https://medium.com/ubiops-tech/how-to-optimize-inference-speed-using-batching-vllm-and-ubiops-10f30ce2d810