Across most organizations, analytics and ML initiatives depend on a steady flow of customer, product, and behavioral data. The issue, however, is that this data tends to contain highly sensitive PII (Personally Identifiable Information). Privacy requirements are no longer the concern of only the legal department, they directly affect time-to-market, vendor risk reviews, customer trust, and even whether certain datasets can be used at all. Teams that don’t bake privacy into their pipelines end up with downstream rework like manual scrubbing, access exceptions, and retroactive masking, creating slower delivery cycles, and higher exposure when auditors ask where personal data lives and who can access it. A privacy-first ETL approach flips this. You preserve the ability to run analytics quickly, while reducing the surface area of raw identity data and making compliance evidence repeatable rather than ad-hoc.
When data engineers build ETL pipelines, we must treat General Data Protection Regulation (GDPR) and data privacy as design fundamentals. Regulatory frameworks, like the EU’s GDPR, impose strict rules on handling personal data, including heavy fines for breaches. In practice this means pipelines must minimize Personal Identifiable Information (PII), apply encryption in transit and at rest, and favor early pseudonymization (e.g., tokenization or hashing) alongside auditable lineage and access logs.
On AWS, tools like Glue and Spark can integrate PII detection and masking transforms directly into your jobs so sensitive fields don’t leak downstream, without significantly slowing daily workloads. Data engineers effectively hold the keys to compliance by embedding encryption, tokenization, and hashing into ETL code instead of relying on manual scrubbing. With Glue transforms, KMS keys, Lake Formation policies, and related services, teams can automate privacy controls while keeping their pipelines fast and productive.
In this post, we’ll look at practical patterns for handling PII safely in AWS-based ETL pipelines.
Handling Sensitive Columns
Teams have a few core options for protecting PII as it flows through ETL pipelines such as salted hashing, tokenization, encryption, and redaction or masking. The right choice depends on your needs downstream and whether or not you need data to remain joinable, reversible, or simply unreadable.
- Salted Hashing (Pseudonymization): This is the process of applying a cryptographic hash (e.g. SHA-256) with a secret, consistent salt/key to identifiers. This produces irreversible tokens that preserve joinability. For example, a data engineer may need a pipeline to create a hash of incoming user emails. This pipeline might create an email_hash column, then drop the clear-text email to protect user identity. The salt which is stored securely, in something like AWS Secrets Manager or KMS, prevents rainbow‐table attacks, a password cracking technique which involves using precomputed hashing to quickly find the users actual email from their stolen hashed email. Nevertheless, you can still join on it and be confident on your results, because the hash is deterministic (it will always produce the same resulting characters when hashed). The tradeoff is that although there is strong query power, the hash is final. Many transformations an engineer may want to execute can be done so with this hash, but the hash itself can never be reversed and the original PII can never be recovered.
- Tokenization (Vaulted or Vaultless): This method replaces a PII value with a token (often format-preserving) using a key store or token service. Tokens look random but can be reversible if a lookup table or vault holds the mapping back to the original value. For example, a Glue job might call an AWS Lambda or external tokenization API per row to swap out emails for tokens. This swap-out creates “fake” but valid-looking data. Tokenizing only the username part of an email and keeping the domain visible for analytics could turn an email like john@gmail.com into something like q9m1@gmail.com. The token service then stores the generated token and the original value in a secure lookup table so analysts can query trends on tokenized data, and only authorized users or jobs are allowed to re-join against the vault for permitted cases. Tokenization preserves data formats and usability (types, lengths, and sometimes checksums) but requires strictly guarding the token vault and managing key/service access; in vaultless approaches, a deterministic cryptographic function replaces the lookup table, but the same access-control concerns still apply.
- Encryption-at-Rest: Encryption-at-rest means enabling encryption on your storage layers (for example S3, Redshift, or RDS) using AWS Key Management Service (KMS). On top of that, sensitive fields can also be column-encrypted in-flight or directly in the warehouse. AWS Glue’s Encrypt transform in PySpark lets you encrypt specific columns with a KMS key, appending an encrypted version to your DataFrame and writing only that field downstream. In Redshift, you can expose a user-defined function that decrypts encrypted values for authorized users or applications. With the right keys, encryption is reversible—unlike hashing—which makes it useful for controlled re-identification. Encryption keeps data scrambled on disk, while TLS/SSL protects it in transit so that both storage and network paths are covered
- Redaction/Masking: In some cases, you may simply mask or drop PII entirely, depending on the needs of your use case. AWS Glue Studio’s Detect PII transform can automatically identify PII fields (emails, addresses, etc.) and either replace them with a static mask or remove them altogether. This is effectively one-way pseudonymization. You might keep an email-shaped string for format, but not the real value behind it. The downside is that masking removes almost all analytical utility, you can’t join or group on masked values; but the upside is strong privacy because the original PII cannot be recovered. When a field isn’t truly needed downstream, best practice is to drop it entirely for maximum protection and minimal risk.
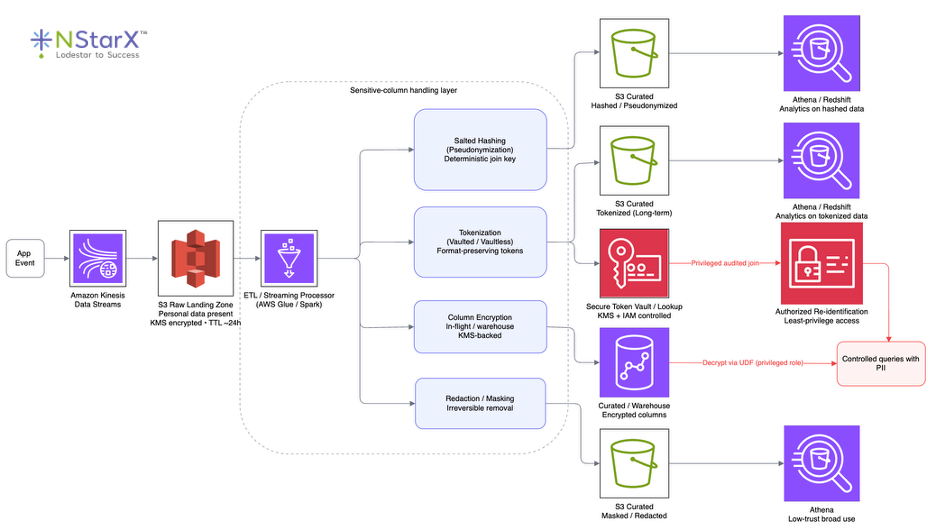
Figure: Example sensitive-column handling pipeline. Raw app event streams land in an encrypted S3 raw zone with short retention; sensitive fields are then protected via pseudonymization (salted hashing), tokenization, column encryption, or redaction before being stored in curated datasets for analytics. For tokenized or encrypted fields, a secure lookup/vault or key management layer holds mappings back to real values, allowing only privileged, audited re-identification queries when permitted, while hashed and redacted outputs remain permanently irreversible.
Each method has trade-offs. Salted hashing (pseudonymization) is irreversible but deterministic, so it protects identity while still enabling joins on the hash. Encryption keeps data unreadable without the right keys, great for privacy and controlled re-identification, but it adds access and operational overhead. Redaction or masking offers the strongest privacy but irreversibly removes detail and eliminates joinability. Tokenization (especially format-preserving) maintains usability because values keep the same type and shape for analytics, but it requires managing a vault or service and enforcing strict access controls. In practice, pipelines often use a mix. Apply encryption-at-rest by default on storage, hash or tokenize fields needed for linkage and longitudinal analytics, and redact fields where linking isn’t needed. For example, you might hash user emails for churn modeling (so you can join by hash), mask social security numbers entirely if they’re not required downstream and tokenize phone numbers when support or operations may need to contact users later.
Designing Schemas to Isolate PII
Once you’ve decided how to protect your sensitive data fields (hashing, tokenizing, encrypting, or masking), the next question is “where should that data live?”. A lot of GDPR risk doesn’t come from the specific protection method you choose, but from PII being scattered across dozens of tables, buckets, and dashboards.
The solution is to design schemas that keep personal data in clearly defined zones and link it to analytic tables only when necessary, through controlled keys rather than raw identifiers. This makes it much easier to enforce access controls, rotate keys, and answer the classic audit question: “Where exactly does this person’s data live in your lake?”
Good pipeline design isolates sensitive data so it’s easy to guard. Best practices include separating PII and Non-PII data, column-level security, tag-based policies and data minimization:
- Separate PII vs Non-PII: Physically separate columns and tables based on whether the data is PII. For instance, you might have one table that holds anonymized usage data and another secure table that holds fields like user_email. This lets you create PII-free views for general analytics and, at ingestion time, drop or hash PII so that only pseudonymized data is loaded into analysis tables, keeping raw PII only where it is absolutely needed. Tools like AWS Glue Crawlers and the Glue Data Catalog let you register schema differences, so you can manage access controls, encryption keys, and retention policies separately for PII and non-PII zones.
- Column-Level Security: This method involves using AWS Lake Formation or Redshift’s built-in controls to hide columns. Lake Formation supports column-level filtering, so you can restrict a role to only see non-PII columns. In this case, you could set a table to have a column which everyone could see, such as customer_id and purchase_amount, but hide customer_email for everyone except for customer service representatives. In Redshift, you also have this form of data access granularity where you can grant rights on some columns and not others. This ensures unauthorized users simply cannot query the sensitive fields, even if they exist in the table, without ever having to alter the table itself.
- Tag-Based Policies: AWS Glue Data Catalog has a tagging feature which can be leveraged to classify sensitive columns and automate policies. Through Lake Formation’s tag-based access control (LF-TBAC), you can attach tags to specific databases, tables, and even columns, then grant data permissions based on those tags instead of on individual objects. For example, you might tag any column with personal data as pii-sensitive and grant rights on resources with that tag only to a dedicated customer-support or privacy role. Tags can be applied at multiple levels (database, table, column), and table-level tags can be propagated to all columns unless you override them. In practice, marketing analysts might see everything tagged analytics, while only a small set of users are allowed to query columns tagged pii-sensitive. Combining tags with Lake Formation reduces manual access control list changes and keeps PII clearly marked in the catalog.
- Data Minimization: This strategy involves only capturing fields you really need when defining/designing the final schema. If a downstream job doesn’t require a field like name or address, don’t include them. Raw PII should rarely be persisted beyond initial transformation. To meet compliance requirements, a best practice would be to delete or expire raw partitions quickly. Configure your S3 bucket lifecycles or Glue ETL to purge or overwrite PII data that is older than a certain set threshold. In other words, treat PII as ephemeral data, keeping it only as long as needed to transform or link it, then drop it entirely.
Usability vs Irreversible Pseudonymization
Every transformation on PII data is a balance between usability and privacy. Joinable transformations like hashes and tokens preserve the data’s analytical value, while fully irreversible approaches, such as redaction or encryption where no decryption keys are retained, maximize privacy but break data linkage. Data teams must choose the appropriate transformation based on the requirements and risk profile of each specific use case.
For example, a churn model that identifies user turnover for your service might benefit from knowing whether user_abc@example.com also used another product. In this case, a join on emails is a crucial part of the data pipeline. Here you could hash emails in your user data with a fixed salt so that identical addresses always produce the same hashed result. In the above example, user_abc@example.com would become something that looks like random text, where an unauthorized user would not be able to tell it was ever an email. After computing the hash, you can safely drop or encrypt the original email column from your datasets. This allows you to link records across extended time periods, because the hash is deterministic, without ever exposing the email itself.
If ever customer lookups were a necessary part of operations, the above hashing technique would not be the appropriate solution. Suppose your internal support apps need to recover a user’s email for auditing. The irreversible hash would prove ineffective in this scenario. Instead, you could tokenize user emails into surrogate keys stored in a data warehouse, while the real user emails reside in a secure data store. This way, unauthorized users would only see the user emails, or tokens, as a key, and only authorized users or jobs would be able to de-tokenize it. Data analysts could use something like AWS’s Athena tables for broad analysis, plus a secure lookup table for joins whenever a user/service is authorized to perform such an operation.
As mentioned in the previous section, data minimization might be the best solution as well. Some pipelines do not need PII at all, even if it is available from upstream data. For example, a reporting dataset might only need a user’s age bracket, not their exact birth date, to group users into age ranges. In this case, you might truncate the birth date to year-only or drop it entirely in the ETL script. Tools like AWS Glue DataBrew include predefined transforms to null out or remove entire fields. While this does forgo the ability to identify individuals, if their identity is not needed, you are on the right track to eliminating almost all privacy risk for your output data.
When considering each choice, you should weigh the privacy risk against the value it adds to your data. Deterministic hashing or tokenization is a common compromise as it prevents casual identification but still supports keys for necessary joins. Ensuring salts or encryption keys are stored securely and separately from the data is a necessity. If the PII is not needed downstream, best practice is to mask it or drop it entirely. Finally, always make sure to accurately document your choices so compliance teams can understand the limitations of the pseudonymization.
Designing for PII-Safe Schema Evolution
Data pipelines and business rules aren’t static. Over time you may discover new PII columns or face regulatory changes that force you to rethink how personal data is stored and protected. Because of this, designing pipelines with flexibility from day one is crucial. Schemas should tolerate incremental column changes, catalog metadata should update automatically as new fields appear, and both your warehouse and data lake should support reconciling different schema versions without breaking downstream jobs. Underneath all of this, your ETL code should be modular and configuration-driven, so adapting to a new sensitive field or a revised retention rule feels like changing a few settings, not rewriting the entire pipeline.
- Incremental Column Changes: If there is an existing column that you need to hash or tokenize, do not simply try and overwrite that existing column in place. Instead, create a new column with the hashed or tokenized data. Using the same email example as before, you would create a new column called email_hashed alongside the existing email column, then update all your downstream jobs to use the hashed column instead of the original. Once all downstream jobs are updated and everything is working as intended, the original email column can be dropped from the dataset. In Glue/Spark you can likewise add new transformed columns and deprecate the old ones in a backward-compatible way.
- Automated Catalog Updates: When pipelines create or alter tables, for example, when a daily Glue Crawler discovers new partitions or columns, it’s important to automate the catalog and permissions updates. One approach is to have Airflow trigger a Glue Crawler and then a CodePipeline (or similar) job on a schedule to discover new tables/columns and apply Lake Formation access control lists based on their tags. This ensures newly introduced sensitive fields are not left unprotected. You can similarly trigger Lambda functions or CI/CD jobs on S3 PUT events or Glue table creations to adjust schemas and permissions as the data evolves.
- Versioned Schema Reconciliation: Keep a clear record of each schema version, whether through the AWS Glue Data Catalog, a dedicated schema registry, or both, so compliance teams can see exactly when PII fields were added, removed, or transformed. In the example discussed earlier, CloudFormation diffs were used to show when new tables appeared and which permissions changed. By keeping both the catalog definitions and your IaC templates in version control, with comments that explicitly call out PII-related changes, you turn ad-hoc schema edits into an auditable change history rather than a series of opaque one-off updates.
- Flexible ETL Code: Write your Spark or Glue scripts so they tolerate schema drift instead of crashing on schema changes. If a PII field is removed, renamed, or not yet deployed in a given environment, the job should degrade gracefully, skipping the transformation for that column rather than breaking the entire data flow. In practice, this often means parameterizing column names in configuration instead of hard-coding them or leaning on Glue DynamicFrames and schema-lenient patterns so that adding a new customer_email column doesn’t immediately crash a pipeline that is supposed to hash it.
- Fixed Schema: A complementary approach is to define explicit schemas in Spark (with nullable PII fields) rather than inferring them. Older files will simply read with null values for any newly introduced columns, and you can add default values or fill them in downstream. This keeps the logical schema stable over time while still allowing the physical data to evolve. This pattern is especially useful when cleaning raw data that needs to be filtered and flattened, or when execution speed and predictable types are the highest priority.
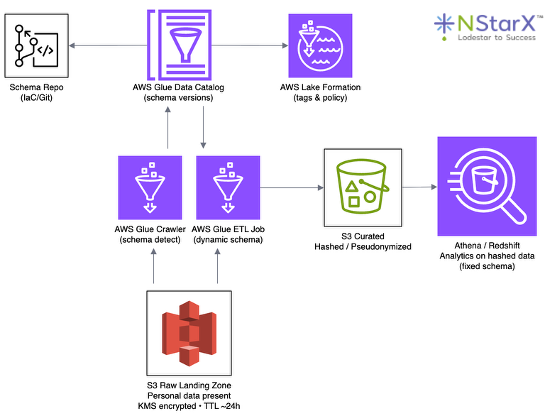
Figure: Example PII-safe schema evolution pipeline. Raw personal data lands in an encrypted S3 raw zone with short retention, where a Glue Crawler detects new columns and updates the Glue Data Catalog. Catalog changes flow into both Lake Formation (for tag-based access policies) and a schema repo in Git, creating an auditable history of PII-related changes. Glue ETL jobs read these schema definitions dynamically, adding hashed or pseudonymized columns and writing to a curated S3 layer. Downstream engines like Athena or Redshift then query the curated data through a fixed, nullable schema, so analytics can evolve safely without breaking when new PII fields appear.
A well-designed pipeline doesn’t fight change; it absorbs it. Taken together, these patterns turn schema evolution into a deliberate, low-risk process. New PII fields can be introduced as separate columns, while catalog tags and permissions keep pace automatically ensuring every change is captured in version control so auditors can see what happened when. Flexible ETL code and explicit schemas give engineers room to iterate without breaking downstream jobs or silently exposing sensitive data. The result is a platform that can evolve alongside your products and GDPR-style regulations, while keeping both analytics and privacy intact.
Auditability and Compliance Tracking
GDPR demands not just protection, but proof of it. It’s not enough to simply hash or tokenize PII data, you need to be able to show who accessed what, when a field was transformed, and how those decisions were approved. That means building visibility into your pipelines by capturing AWS CloudTrail and job logs, turning on Lake Formation access logging, and maintaining clear data lineage so you can trace a report back to its raw inputs. On top of that, transformation rules should be documented in a way non-engineers can understand, and changes to PII handling should go through an explicit review and approval process. Done well, this gives auditors and privacy teams a concrete trail to follow for validation.
A good starting point for auditability is getting your logging foundations right. Make sure to enable AWS CloudTrail for all the services that touch your data and control plane. For AWS, these are things like Glue, Athena, Redshift, Lambda, and any orchestration around them. CloudTrail will record who ran which job, who modified which table or function, and under which IAM role. For Glue ETL jobs, combining CloudTrail with CloudWatch Logs lets you see which script version executed, what parameters it used, and whether a particular KMS key or connection was involved. Those logs should go to a secure S3 bucket or a dedicated CloudWatch Logs log group with restricted access so that the audit trail itself is not tampered with.
On top of this, Lake Formation’s access logging gives you visibility into who actually accessed what sensitive data. Lake Formation logs, together with CloudTrail events, can show exactly which user or role accessed PII-tagged columns and when, because Lake Formation has column-level policies. If you retain these logs for long enough, they become a powerful source of evidence during compliance reviews. Every permission change and every query or job against sensitive data is traceable, giving your GDPR officer a concrete record of processing activity, rather than a best-effort reconstruction after the fact.
That being said, logging alone isn’t enough. You also need to understand how the data itself flows. Data lineage tools, such as lineage views in AWS Glue Data Catalog, can show which ETL jobs consume a table, which jobs produce a given column, and how sensitive fields propagate. Tagging columns as “sensitive” in the catalog means that when a downstream table is created, auditors can see that a particular field ultimately originated from PII. Glue job bookmarks and job run metrics published to CloudWatch also help you trace the path of a dataset through your pipeline, so users can better understand how values propagated at each stage of the data transformation journey.
The transformation rules themselves should be clearly documented and kept in version control, rather than relying on what individual engineers remember. Keep your masking and tokenization logic in source control alongside the rest of your code. Make it explicit, for example, that customer_address is always truncated to a ZIP or postal code, and record that rule as a best practice for your engineers. When an audit happens, you want to be able to point to the exact script or configuration that implemented each anonymization step. Automated tests that scan analytics tables to verify no unexpected cleartext PII remains can catch mistakes early, long before a regulator does.
Finally, wrap all of this in a lightweight approval and review process. Make sure to involve your privacy and compliance stakeholders when designing or changing data pipelines. In practice, this can be as simple as a pull request workflow where changes that touch sensitive schemas or transformations are tagged for review by a specific group. You can also automate notifications on schema changes, using things like Slack alerts, so that if a new PII column appears in a table, the right people are prompted to classify it and apply the appropriate protections before it quietly slips into production.
Key Takeaways
- Treat PII as a top priority: Embedding privacy into the design of your ETL, rather than treating it as an afterthought, is essential under GDPR. Where applicable, use Glue’s built-in transforms, Key Management Service (KMS), and Lake Formation to bake protection directly into your pipelines.
- Use multiple techniques: Salted hashes, tokens, encryption, and redaction each solve different needs but can be combined to protect sensitive data. For joinable identifiers such as emails and IDs, hashing with a secret salt preserves linkage while hiding the raw value. For data that must be reversible or format-preserving (e.g., credit card numbers used for fraud analysis), use tokenization with a secure vault. Default to encryption-at-rest on storage, encrypt in transit, and always mask or drop PII that is not needed downstream.
- Isolate and tag PII: Design your schema so PII lives in guarded columns or tables. Apply column-level access controls using tools like Lake Formation and tag sensitive data in the Glue Data Catalog. This way, analysts working on “safe” datasets never see hidden PII columns unless they are explicitly authorized to do so.
- Automate schema updates: Incorporate automated discovery and CI/CD into your data stack. Use Glue Crawlers or a schema registry and automate Lake Formation or IAM updates via scripts and pipelines. When schema stability is important, define your schemas explicitly so changes are deliberate and reviewable rather than implicit side effects.
- Log everything: Maintain an audit trail of all data transformations and access. Enable CloudTrail on Glue, Athena, Redshift, and related services, and log each masking or encryption step. Keep your PII processing scripts and job parameters in version control. This ensures you can answer “who did what to which PII and when,” which is at the heart of GDPR accountability.
Benefits
Technical: These patterns reduce the blast radius of sensitive fields by pushing pseudonymization and minimization earlier in the pipeline, so downstream tables are safer by default. They also improve operational consistency: schemas evolve in a controlled way, access controls remain enforceable (even at the column level), and audit trails are available through standard AWS logging and catalog metadata. The result is an ETL stack that stays performant while being easier to govern, troubleshoot, and certify.
Business: Privacy-first pipelines reduce compliance friction (fewer exceptions, faster audit responses, clearer ownership of PII) and lower breach impact by limiting where raw identifiers exist. They also accelerate delivery. Teams spend less time on retroactive data cleanups and can confidently reuse curated datasets across analytics, reporting, and modeling without renegotiating access every time. Ultimately, this strengthens customer trust and keeps data products shippable in regulated environments, without turning governance into a blocker.
By integrating these practices, data teams can stay agile, running daily Spark jobs and loading Redshift tables, without compromising privacy. A thoughtful pipeline design, using features from Glue, Lake Formation, Spark, and Redshift, lets you maintain high performance while automatically encrypting, tokenizing, or masking PII as needed. This balance keeps analysts productive and, more importantly, keeps you aligned with GDPR and similar regulatory expectations. In short: build privacy in from the start, automate it wherever you can, and never treat PII as an afterthought.
References
-
- Sathish Kumar Srinivasan. “PII Management in Data Pipelines: Architecting for Compliance, Security, and Scalability.” https://medium.com/@sathishdba/pii-management-in-data-pipelines-architecting-for-compliance-security-and-scalability-ed81c98919b3
- Airbyte. “Data Privacy and Compliance Guide for Data Engineers: GDPR, CCPA, and Emerging Regulations.” https://airbyte.com/data-engineering-resources/data-privacy-and-compliance
- AWS Glue Documentation. “Detect and process sensitive data.” https://docs.aws.amazon.com/glue/latest/dg/
- AWS Glue Documentation. “Logging and monitoring in AWS Glue.” https://docs.aws.amazon.com/glue/latest/dg/
- AWS Big Data Blog. “How MOIA built a fully automated GDPR compliant data lake using AWS Lake Formation, AWS Glue, and AWS CodePipeline.” https://aws.amazon.com/blogs/big-data/how-moia-built-a-fully-automated-gdpr-compliant-data-lake-using-aws-lake-formation-aws-glue-and-aws-codepipeline/
- Bruno Liberal de Araujo. “Masking Personally Identifiable Information with Salt using Cloud Data Fusion.” https://medium.com/@liberalaraujo/masking-personally-identifiable-information-with-salt-using-cloud-data-fusion-737a671bf5e3
- AWS Partner Network (APN) Blog. “How to Scale Data Tokenization with AWS Glue and Protegrity.” https://aws.amazon.com/blogs/apn/how-to-scale-data-tokenization-with-aws-glue-and-protegrity/
- Upsolver. “Protecting PII & Sensitive Data on S3 with Tokenization.” https://www.upsolver.com/blog/protecting-sensitive-data-s3-tokenization
- AWS Glue Documentation. “Encrypt class.”https://docs.aws.amazon.com/glue/latest/dg/aws-glue-api-pyspark-transforms-Encrypt.html
- AWS Big Data Blog. “Implement column-level encryption to protect sensitive data in Amazon Redshift with AWS Glue and AWS Lambda user-defined functions.”https://aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/
- AWS Lake Formation Documentation. “Data filtering and cell-level security in Lake Formation.”https://docs.aws.amazon.com/lake-formation/latest/dg/
- AWS Big Data Blog. “Implement tag-based access control for your data lake and Amazon Redshift data sharing with AWS Lake Formation.”https://aws.amazon.com/blogs/big-data/implement-tag-based-access-control-for-your-data-lake-and-amazon-redshift-data-sharing-with-aws-lake-formation/
- AWS Glue DataBrew Documentation. “Identifying and handling personally identifiable information (PII) data.”https://docs.aws.amazon.com/databrew/latest/dg/personal-information-protection.html
- AWS Big Data Blog. “Introducing PII data identification and handling using AWS Glue DataBrew.”https://aws.amazon.com/blogs/big-data/introducing-pii-data-identification-and-handling-using-aws-glue-databrew/
- AWS Big Data Blog. “Detect, mask, and redact PII data using AWS Glue before loading into Amazon OpenSearch Service.”https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- AWS Glue Documentation. “Logging AWS Glue API calls with AWS CloudTrail.”https://docs.aws.amazon.com/glue/latest/dg/monitor-cloudtrail.html
- Amazon Redshift Documentation. “Logging with CloudTrail.”https://docs.aws.amazon.com/redshift/latest/mgmt/logging-with-cloudtrail.html
- Amazon Athena Documentation. “Query AWS CloudTrail logs.”https://docs.aws.amazon.com/athena/latest/ug/cloudtrail-logs.html
- Cloudar. “Parse and query CloudTrail logs with AWS Glue, Amazon Redshift Spectrum and Athena.”https://cloudar.be/awsblog/parse-and-query-cloudtrail-logs-with-aws-glue-amazon-redshift-spectrum-and-athena/
- AWS Lake Formation Documentation. “What is AWS Lake Formation?”https://docs.aws.amazon.com/lake-formation/latest/dg/what-is-lake-formation.html
- AWS Lake Formation Documentation. “Cross-account CloudTrail logging.”https://docs.aws.amazon.com/lake-formation/latest/dg/cross-account-logging.html
- Agencia Española de Protección de Datos (AEPD). “Introduction to the hash function as a personal data pseudonymisation technique.”https://www.aepd.es/guides/introduction-to-hash-function-as-personal-data-pseudonymisation-technique.pdf
- Information Commissioner’s Office (ICO). “Pseudonymisation.”https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/data-sharing/anonymisation/pseudonymisation/
- PWC. “Anonymisation and pseudonymisation.”https://www.pwc.lu/en/general-data-protection/docs/pwc-anonymisation-and-pseudonymisation.pdf
- European Data Protection Board. “Guidelines 01/2025 on Pseudonymisation (Draft for public consultation).”https://www.edpb.europa.eu/our-work-tools/documents/public-consultations/2025/guidelines-012025-pseudonymisation_en
- IBM Developer. “GDPR – Minimizing application privacy risk.”https://developer.ibm.com/articles/s-gdpr3/
- K2View. “Pseudonymization vs Tokenization: Benefits and Differences.”https://www.k2view.com/blog/pseudonymization-vs-tokenization/
- AWS News Blog. “AWS Glue Data Catalog views are now GA for Amazon Athena and Amazon Redshift.”https://aws.amazon.com/about-aws/whats-new/2024/08/aws-glue-data-catalog-views-athena-redshift/