NStarX Point of View | Enterprise AI Strategy
Thesis
There is a pattern that enterprise technology leaders have lived through before — the kind where excitement outpaces architecture, and the bill arrives before the strategy does. It happened with cloud. It happened with data lakes. And right now, it is beginning to happen with AI agents. The difference this time is that the unit of consumption is invisible: a token. Unlike a virtual machine you can resize or a storage bucket you can audit, tokens flow silently through every agent interaction, every retrieval call, every reasoning loop — accumulating costs that no one budgeted for and few organizations are equipped to observe. At NStarX, we believe the enterprises that win with Agentic AI will not simply be those who deploy the most intelligent systems. They will be the ones who designed the economics first. Token efficiency is not a cost-cutting exercise. It is a design discipline — and it starts before the first line of agent code is written.
The Bill You Didn’t See Coming
Ask any VP of Engineering who lived through the first wave of cloud adoption about their first AWS invoice, and you will usually get a rueful smile. Not because the platform failed them — it didn’t — but because nobody had truly modeled what “elastic compute” meant at scale. Dev teams spun up environments and forgot to tear them down. Databases replicated across regions no one remembered configuring. Data transfer costs appeared like line items from a parallel universe. By the time FinOps became a discipline, many organizations had already spent years cleaning up architectural decisions made in the heat of “let’s just get it running.”
We are standing at a remarkably similar inflection point with AI.
The first generation of enterprise AI — chatbots, summarization tools, document Q&A — was relatively contained. A user asked a question, the model responded, the transaction closed. Token consumption was linear and mostly predictable. CIOs could look at usage dashboards and make reasonable projections.
Agentic AI is structurally different. When you deploy an AI agent, you are not sending a single question to a model. You are initiating a process: the agent plans,
retrieves context, calls tools, evaluates its own outputs, loops back, spawns sub-agents, and eventually delivers a result. Each of those steps is a model call. Each model call consumes tokens. A single user task that looks like “analyze this contract and flag risks” might quietly trigger eight to twelve model invocations before a response surfaces. Multiply that by five hundred concurrent enterprise users, running agent workflows across a business day, and the token economics stop being a footnote in your AI budget and start being the budget.
The enterprises that understand this now — before they are staring at a surprise invoice — will build AI systems that are not just capable, but economically sustainable.
Understanding Tokenomics: The Language of AI Cost
Before any enterprise leader can govern AI costs, they need to understand what they are actually paying for.
In large language models, a token is the fundamental unit of text the model reads and writes. Think of it less like a word and more like a syllable — roughly three to four characters on average. The sentence “The contract was executed on January 1st” contains approximately ten tokens. Longer documents, complex prompts, and multi-turn conversations can run into thousands of tokens before the model has even begun generating a response.
Every interaction with an LLM has two sides of the token ledger: what goes in, and what comes out.
Prompt tokens are everything sent to the model — instructions, context, user input, retrieved documents, tool outputs. Every character of input is metered. If your agent system prepends a 2,000-token system prompt to every call, that cost is baked into every single interaction across your deployment.
Completion tokens are what the model generates in return. These typically cost more per token than input tokens, depending on the provider. A verbose agent that writes long explanations when a short answer would suffice is burning your budget on every response.
Context tokens reflect the cumulative conversation or working memory the model holds during a session. In multi-turn agent workflows, context grows with every exchange. A planning agent that maintains a running log of its decisions and sub-task outputs can accumulate 10,000 or more context tokens before finishing a single workflow.
Retrieval tokens enter the picture when your agents use Retrieval-Augmented Generation (RAG). Documents pulled from a knowledge base, database records fetched by a tool call, or policy documents injected into the prompt — all of these add to the token count before the model has processed a single business question.
Reasoning tokens are newer to the conversation but increasingly significant. Models with extended chain-of-thought or internal reasoning capabilities consume tokens for the thinking process itself, which often isn’t surfaced to the user but shows up in your invoice.
Taken together, these five categories define what we at NStarX call the Tokenomics Stack — the full cost surface of any AI interaction. Enterprises that measure only completion costs are reading one line of a five-line receipt.
Why Agentic Systems Don’t Just Add Tokens — They Multiply Them
The leap from a simple LLM-powered chat interface to a true Agentic AI system is not incremental. It is architectural. And the token economics change accordingly.
To understand why, consider a relatively ordinary enterprise task: “Review this vendor proposal and summarize the key commercial risks, comparing them against our standard contract terms.”
In a basic LLM tool, a user pastes the document, sends the prompt, and reads the response. Two model calls at most. Clean and bounded.
Now deploy that same task through an agentic workflow and watch what actually happens:
The Orchestrator Agent receives the task and creates a plan — breaking it into sub-tasks: retrieve standard contract terms, analyze the proposal, compare the two, synthesize findings. That planning step alone is a model call consuming hundreds of tokens just to generate the task breakdown.
The Retrieval Agent queries your internal knowledge base for relevant contract templates and risk policies. Each retrieved document is chunked, scored, and injected into the next agent’s context — adding thousands of retrieval tokens to the growing ledger.
The Analysis Agent processes the vendor proposal with the retrieved context loaded. This is likely your most expensive call — potentially 6,000–10,000 tokens of input, with a detailed completion on the other side.
The Comparison Agent receives the analysis output as input, along with the original contract terms, and performs a structured comparison. Another large-context call.
The Reflection Loop — a design pattern where the agent reviews its own output before returning it — triggers yet another model call. The agent reads its own completion, checks it against the original task criteria, and either confirms or revises.
The Validation Agent, in more mature architectures, independently scores the quality or compliance of the final output. One more model call.
What started as a single user request has generated six distinct model invocations, accumulated anywhere from 25,000 to 60,000 tokens, and potentially used a mix of model tiers depending on your architecture.
Now imagine this is not one request — it is a legal team running forty vendor reviews simultaneously on a Tuesday afternoon. The math is not linear. It compounds. That is the fundamental economic reality of Agentic AI that enterprises must internalize before they scale.
When Scale Arrives, the Economics Become Existential
Abstract token math becomes very concrete when you map it against actual enterprise deployment scenarios.
Engineering Copilots — AI agents that assist developers with code review, documentation, pull request summarization, and debugging — might each process 15,000 to 30,000 tokens per engineering session. In an organization with 200 engineers using the copilot for four hours a day, you are looking at hundreds of millions of tokens consumed monthly. If that system wasn’t designed with model tiering and context trimming, it is almost certainly over-consuming on high-cost models for tasks that a lighter, cheaper model handles just as well.
Enterprise Knowledge Assistants — agents that answer employee questions by retrieving from internal wikis, policy libraries, and HR systems — carry a deceptive cost profile. The retrieval component alone can inject 4,000–8,000 tokens of context per query. Multiply that across 5,000 daily queries in a global enterprise and the retrieval layer is generating more token cost than the actual answers.
Financial Analysis Agents running multi-step reasoning on earnings data, variance reports, and forecasts are among the most token-intensive enterprise applications. Their reasoning loops are deep, their context windows are wide, and the expectation for accuracy is high — which typically means models are not being swapped for cheaper alternatives.
Customer Service Agents have high volumes but relatively shorter conversations. The risk here is not depth — it is breadth. Thousands of concurrent sessions, each loading product knowledge, customer history, and policy context, create a massive aggregate token footprint that scales directly with your customer base.
None of these scenarios are hypothetical. They are where enterprises are heading right now. And the organizations that arrive without a token budget framework will face the same moment of reckoning that happened with cloud — except faster, and at a cost structure that is far less visible along the way.
The NStarX Framework for Enterprise Tokenomics Design
At NStarX, we work with engineering teams building AI-first products and platforms. One of the most consistent gaps we see — even among technically sophisticated organizations — is the absence of a deliberate economic design layer in their agent architecture. The framework we have developed to address this is built around five pillars.
Pillar 1: Token Budgeting
Token budgeting means treating tokens as a finite resource — not philosophically, but architecturally. Before any agent workflow goes to production, your team should be able to answer: what is the expected token consumption per workflow invocation? What is the P95 ceiling? What is the monthly cost at our projected usage volume?
This is not about being conservative with AI capabilities. It is about making conscious tradeoffs. A workflow that consumes 80,000 tokens should deliver 80,000 tokens worth of business value. If it doesn’t, you don’t fix the cost — you fix the design.
Practically, this means establishing token usage benchmarks during development, not after deployment. It means building cost models as part of your architecture review, not as a post-launch surprise.
Pillar 2: Token Efficiency
Efficiency in token terms means generating equivalent intelligence with less input and output. This is a design skill, not a compression trick.
Prompt engineering is the most direct lever. A system prompt written at 3,000 tokens often carries the same intent as one written at 800 — but the difference in cost, compounded across millions of calls, is significant. Structured outputs over verbose prose, targeted retrieval over full-document injection, output length controls — each is an efficiency mechanism.
Context management is equally important. Not everything in a conversation history needs to persist. Well-designed agents summarize and trim their working memory rather than passing entire interaction histories forward on every call.
Pillar 3: Model Tiering
Not every task in an agent workflow deserves a frontier model. Planning steps, format validation, classification tasks, and simple lookups can often be handled by smaller, faster, and significantly cheaper models. Saving the large, reasoning-capable model for the steps that genuinely require it is one of the highest-leverage decisions in Agentic AI architecture.
Model tiering requires mapping your workflow to a task complexity taxonomy — understanding which steps are reasoning-intensive and which are coordination tasks — and routing accordingly. At NStarX, we design agent architectures with deliberate model routing from day one, treating it as a first-class architectural concern rather than an optimization afterthought.
Pillar 4: Agent Architecture Optimization
The structure of your multi-agent system has a direct and significant impact on token consumption. Unnecessary agent hops, redundant retrieval calls, poorly scoped sub-agents, and uncontrolled reflection loops are all architectural inefficiencies that compound at scale.
Good agent architecture minimizes the number of model calls required to complete a task while maintaining quality. This means designing clear handoff boundaries between agents, building in caching for frequently retrieved content, limiting reflection loops to high-stakes decision points, and avoiding the temptation to add agent complexity because it is technically interesting rather than operationally necessary.
Pillar 5: Token Governance
Governance is where the economics become sustainable. Token governance means establishing visibility, accountability, and policy around AI cost — across teams, use cases, and models.
This includes instrumenting every agent workflow with token consumption telemetry, creating cost attribution by team or product area, setting usage thresholds that trigger review, and building cost awareness into your AI engineering culture. Without governance, individual teams optimize for capability while the organization absorbs the cost. With governance, everyone has a stake in efficiency.
NStarX framework is pictorially represented in Figure 1:
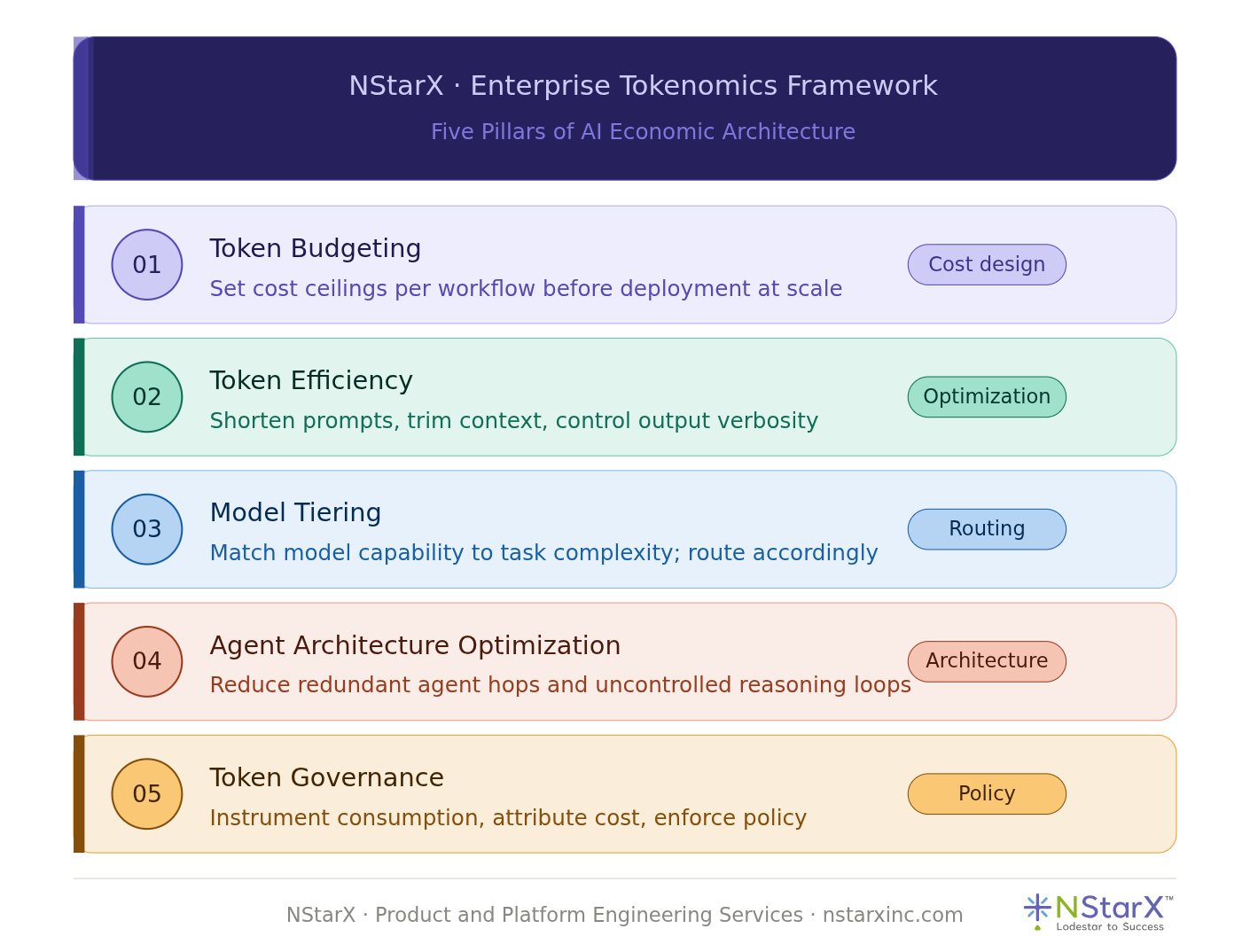
Figure 1: NStarX Enterprise Tokenomics Framework
The Rise of AI FinOps
Those who lived through the cloud maturation era will recognize what is coming. The same way cloud FinOps emerged to bring financial discipline to infrastructure spending — aligning engineering decisions with cost accountability — AI FinOps is becoming an organizational necessity for any enterprise running AI at scale.
The parallel is not cosmetic. In both cases, the underlying cost driver is invisible to the end user, consumption scales non-linearly with adoption, and the gap between engineering decisions and financial outcomes is wide enough to drive a budget overrun through.
AI FinOps starts with cost observability — the ability to see, in real time, what AI systems are consuming and at what cost. This means token-level telemetry integrated into your AI platform, not just aggregate API invoices from your model provider.
It extends into model routing intelligence — dynamically directing requests to the most cost-appropriate model based on task complexity, current load, and budget thresholds. This is where engineering architecture and financial policy need to speak the same language.
It requires cross-functional governance: finance teams need to understand that an AI agent is not a fixed-cost subscription but a consumption-based system that scales with usage. Engineering teams need to understand that their architectural choices have direct financial implications. The organizations that bridge this gap — early — will have a structural advantage as AI cost pressures intensify.
At NStarX, we build AI FinOps thinking into every engagement from the architecture phase (refer to Figure 2), because retrofitting cost governance onto a production AI system is significantly more expensive than designing for it from the start.
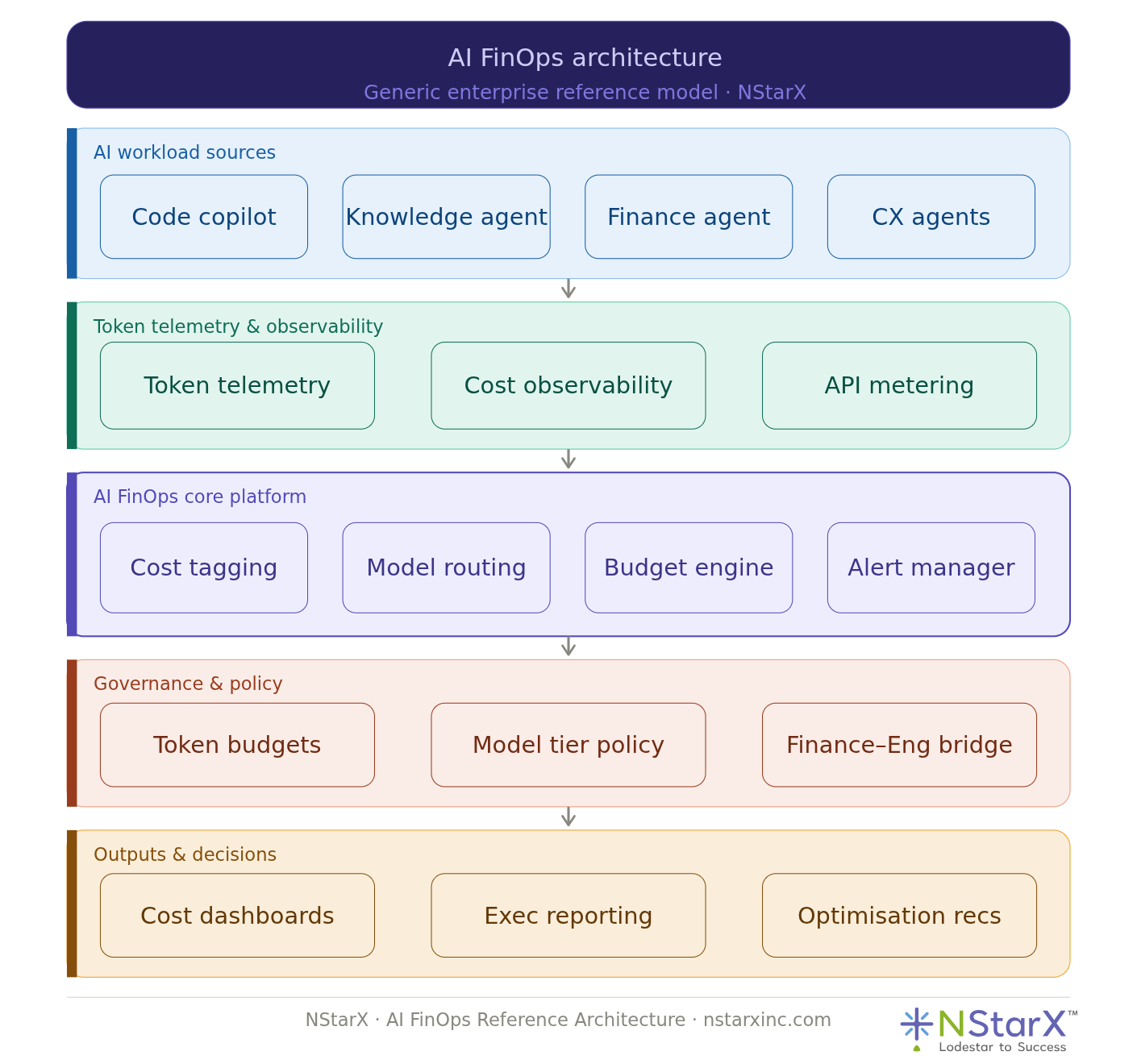
Figure 2: NStarX AI FinOps Architecture
The Mistakes That Are Already Being Made
Enterprise AI deployment is accelerating, and in that acceleration, some patterns of poor economic design are becoming clearly visible. They are worth naming plainly.
Defaulting to the most powerful model for every task. It is easy to benchmark a system using a frontier model and declare it production-ready. It is harder to go back and ask which steps genuinely need that capability and which are doing validation logic that a smaller model handles equally well. Most organizations skip that audit and pay for it monthly.
Building with no token observability. Many enterprise AI deployments have no mechanism to understand token consumption at the workflow or agent level. The bill arrives, the total is alarming, and no one knows which workflow or which team is responsible. You cannot manage what you cannot measure.
Designing agent workflows without cost modeling. Agent architectures are often designed for capability — how many agents can collaborate, how deeply can reasoning chains go — without any concurrent analysis of what each design decision costs at scale. By the time scale arrives, the architecture is entrenched.
Context windows treated as free storage. There is a persistent assumption that larger context windows simply mean “more capability.” They also mean more tokens on every call that uses them. Injecting a 20,000-token document into context for a task that needed three paragraphs is not caution — it is waste.
Reflection loops without termination design. Reflection and self-correction are valuable agent behaviors. Uncontrolled, they are infinite token loops. Without clear exit conditions and iteration caps, a single runaway reasoning chain can consume more tokens than a thousand routine queries.
Each of these mistakes is understandable — they happen because teams are focused on making the AI work, not on making the AI affordable. But the two goals are not in tension if they are addressed together from the beginning.
A Pre-Deployment Checklist for Enterprise AI Leaders
Before your organization deploys Agentic AI systems at scale, work through the following:
1. Estimate token consumption before you deploy. Map each workflow stage to expected token input and output. Build a cost model at your projected usage volume. Define your acceptable cost-per-task threshold.
2. Design agent workflows for efficiency, not just capability. Challenge every agent hop and every retrieval call. Ask whether the step justifies the model invocation. Eliminate redundancy before it reaches production.
3. Implement model tiering deliberately. Categorize workflow steps by reasoning complexity. Assign model tiers accordingly. Reserve frontier models for the minority of steps that genuinely require them.
4. Build token observability from day one. Instrument your agent system with per-agent, per-workflow token telemetry. Integrate it into your monitoring stack. Make cost as visible as latency and error rate.
5. Define token budgets per use case. Establish cost ceilings for each AI-powered workflow. Create alerting when consumption approaches thresholds. Build budget awareness into your engineering review process.
6. Align finance and engineering before launch. Ensure your finance team understands the consumption-based cost model. Ensure your engineering team understands the financial implications of architectural choices. Build a shared vocabulary for AI cost governance.
7. Design reflection loops with exit conditions. If your agents self-evaluate, define exactly how many iterations are permitted and under what conditions the loop terminates. Never leave a reasoning loop architecturally unbounded.
The Economic Discipline Behind Intelligent Systems
There is a version of the Agentic AI story that ends well for enterprises — and it does not sound like the pitch decks. It sounds like something more familiar: engineering rigor, economic discipline, and architectural decisions made with full awareness of their downstream consequences.
The intelligence in these systems is real. The value they can deliver is real. But intelligence without economic sustainability is a prototype, not a platform. We have watched enterprises build extraordinary AI capabilities on architectures that could not survive their own success — where the cost of operating at scale made the business case collapse exactly when adoption peaked.
Token economics will define the competitive landscape of enterprise AI the same way compute economics defined the cloud era. The organizations that treated cloud cost as an engineering concern — not just a finance concern — built platforms that scaled profitably. The ones that didn’t spent years in FinOps remediation.
The window to design this correctly is now, in the architecture phase, before the agents are deployed and the consumption is locked in.
At NStarX, we believe the most intelligent thing an enterprise can do with Agentic AI is think about the economics first. Build the intelligence second. Then let the two work together — sustainably, at scale, and with the kind of clarity that turns AI from an experiment into a lasting competitive advantage.
Conclusion: The Economic Imperative of Intelligent Systems
The promise of Agentic AI is real — and so is the bill that comes with it.
Enterprises are entering a new phase of AI adoption where the conversation must shift from “what can these systems do” to “what will these systems cost to operate sustainably at scale.” The two questions are not in competition. But historically, when technology teams have prioritized the first while ignoring the second, the results have been architectures that collapse under their own success.
Token economics is not a niche concern for AI engineers to solve quietly in the background. It is a strategic discipline — one that sits at the intersection of product architecture, engineering culture, and financial governance. The organizations that treat it as such, and build that discipline into their AI programs from the start, will not only run more cost-efficient systems. They will build AI platforms that can survive the transition from pilot to production to enterprise scale without a FinOps reckoning midway through.
At NStarX, we have seen both sides of this equation. We have seen what happens when Agentic AI architectures are designed with economic intentionality from day one — and we have seen the cost of retrofitting governance onto systems that were never designed for it. The gap between those two outcomes is significant. And the window to design it correctly is always now, never later.
Agentic AI is not just an engineering milestone. It is an economic commitment. Treat it accordingly.
References
The following resources informed the strategic context and technical framing of this article. Enterprise leaders building AI programs will find each valuable for deeper exploration.
- Anthropic — Model Pricing and API Documentation Details on token-based pricing for Claude models, including input/output token rates across model tiers. https://www.anthropic.com/pricing
- Anthropic — Claude API Documentation Technical reference for context windows, prompt construction, and model capabilities referenced throughout this article. https://docs.anthropic.com
- OpenAI — Tokenizer Tool An interactive reference for understanding how text is broken into tokens across large language models — useful for estimating token consumption in prompts and completions. https://platform.openai.com/tokenizer
- AWS — Cloud FinOps and Cost Optimization AWS’s own documentation on cloud cost governance and FinOps practices — the discipline that Agentic AI tokenomics mirrors. https://aws.amazon.com/aws-cost-management/
- FinOps Foundation — FinOps Framework The canonical reference for cloud financial operations — the organizational and cultural model that AI FinOps will increasingly follow. https://www.finops.org/framework/
- LangChain — LangGraph Documentation Reference for multi-agent orchestration patterns, including planning agents, tool-using agents, and reflection loops discussed in the agentic workflow section. https://langchain-ai.github.io/langgraph/
- Microsoft Azure — AI Cost Management for Azure OpenAI Enterprise guidance on monitoring and governing token consumption within Azure’s AI platform — a practical reference for organizations already in the Azure ecosystem. https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/cost-management
- Google Cloud — Vertex AI Pricing and Cost Controls Google’s documentation on token pricing and usage controls for Gemini models on Vertex AI — relevant for enterprises evaluating multi-cloud AI deployments. https://cloud.google.com/vertex-ai/pricing
- Retrieval-Augmented Generation (RAG) — Original Research Paper Lewis et al. (2020). The foundational academic paper introducing the RAG architecture referenced extensively in the retrieval tokens and agentic workflow sections. https://arxiv.org/abs/2005.11401
NStarX is a Product and Platform Engineering Services company helping enterprises design, build, and scale AI-first systems. Our Engineering Maturity Arc framework guides organizations from legacy modernization through cloud-native architecture to AI-Native product engineering.
To explore how NStarX approaches Agentic AI architecture and AI FinOps design, visit dev-wp.nstarxinc.com/