The Uptime Illusion
For two decades, enterprise infrastructure teams competed on a single metric: uptime. The race to five nines — 99.999% availability — shaped procurement decisions, architecture blueprints, and SLA negotiations alike. Five nines means roughly five minutes of downtime per year. It sounds bulletproof. It is not.
On July 19, 2024, a faulty content update from CrowdStrike took down an estimated 8.5 million Windows systems globally. Airlines, hospitals, banks, and broadcasters went dark simultaneously. The incident had nothing to do with uptime. Every server was technically “up.” The operating systems booted. But the enterprise was unable to function. No SLA protected them.
“Uptime measures whether a system is running. Resilience measures whether a business can survive when the systems around it break.”
The CrowdStrike event was not an anomaly. It was a preview. As enterprises consolidate onto fewer cloud providers, rely on a shrinking set of SaaS platforms, and race to deploy AI infrastructure built on scarce GPU clusters, the conditions for systemic, civilization-scale failures are accelerating. The question for engineering leaders in 2026 is no longer “Will we go down?” It is: “Can we survive when the infrastructure ecosystem around us collapses?”
The Architecture of Fragility
Modern enterprise IT has traded operational complexity for consolidation efficiency. Three hyperscalers — AWS, Azure, and GCP — collectively host an estimated 65–70% of global enterprise workloads. Identity is concentrated at Microsoft Entra, Okta, and Google. AI inferencing runs through a handful of API providers built on scarce NVIDIA H100 and H200 clusters. This consolidation delivers genuine benefits: cost efficiency, global reach, and operational leverage. It also creates something engineers rarely model: correlated failure risk.When a single AWS us-east-1 region degrades, it does not just impact one application. It cascades across thousands of SaaS platforms, APIs, and dependent services simultaneously. When Okta experiences an authentication outage, every enterprise that delegated identity to it loses access in lockstep. This is systemic risk — the risk that failure in one node propagates across the entire connected graph.
| Concentration Vector | Example Failure | Blast Radius |
|---|---|---|
| Cloud Region | AWS us-east-1 (Dec 2021) | Thousands of SaaS platforms offline |
| Identity Provider | Okta (Oct 2023) | Millions of users locked out globally |
| CDN / DNS | Cloudflare (Jul 2023) | Major internet properties unreachable |
| Agent / Update | CrowdStrike (Jul 2024) | 8.5M Windows endpoints crashed |
| AI API Provider | OpenAI (Nov 2023) | Enterprise AI workflows halted globally |
| SaaS Platform | Salesforce (May 2023) | Sales pipelines frozen across sectors |
Chaos Sovereignty: A New Architectural Imperative
The discipline emerging in response to these systemic risks is what we at NStarX call Chaos Sovereignty. It is distinct from disaster recovery, business continuity, and high availability — though it encompasses all three.
Disaster recovery asks: How fast can we recover after a failure? Business continuity asks: Can we keep operating during a failure? Chaos Sovereignty asks a harder question: Can we continue to function as an independent enterprise even when the infrastructure ecosystem we depend on ceases to exist around us?
Chaos Sovereignty = The architectural posture of an enterprise that can sustain core operations through arbitrary systemic failures in its dependency graph.
Sovereign Resilience is the operational expression of Chaos Sovereignty. Where sovereignty implies independence — freedom from single-vendor control, regional lock-in, or AI provider dependency — resilience implies the ability to absorb shocks and continue. Together they describe an enterprise that is both independent and indestructible by design.
The Survivability Stack
We propose a four-tier maturity model for enterprise infrastructure:
- Tier 1 — Availability: Systems stay up under normal load. Measured by uptime SLAs.
- Tier 2 — Reliability: Systems recover from component failures. Measured by MTTR.
- Tier 3 — Resilience: Systems adapt to partial ecosystem failures. Measured by degraded mode capability.
- Tier 4 — Survivability: Systems operate independently through total ecosystem collapse. Measured by Mean Time to Survive (MTTS).
Most enterprises today operate at Tier 2. The target for 2026 and beyond is Tier 4.
The Architecture of Sovereign Resilience
1. Active-Active Multi-Region, by Default
Active-passive multi-region — where a primary region handles traffic and a secondary stands by — is insufficient for Chaos Sovereignty. When us-east-1 degrades, the failover itself often depends on us-east-1 control plane services. Active-active architecture, where every region handles live traffic and is independently capable of full-stack operation, eliminates this dependency. Traffic routing via Anycast or latency-based DNS (Route 53, Cloudflare), stateless compute layers, and asynchronous data replication across regions are the foundational primitives.
2. Control Plane vs. Data Plane Independence
One of the most dangerous architectural anti-patterns in modern cloud is co-locating the control plane and data plane in the same region. When the control plane fails — as it did during the AWS us-east-1 December 2021 event — data plane operations that should have continued were disrupted because orchestration, autoscaling, and health checks depended on the same degraded region. Sovereign resilience requires that the data plane can operate in island mode: processing transactions, serving requests, and persisting state without any external control plane dependency.
3. Blast Radius Management
Every dependency in an enterprise system is a potential blast radius amplifier. Identity, AI models, shared databases, global CDNs, third-party SaaS — each can propagate a failure horizontally. Blast radius management requires hard boundaries: circuit breakers, bulkhead patterns, asynchronous decoupling via message queues, and fallback paths that activate automatically without human intervention. The test of a well-designed blast radius strategy is whether a complete failure of any single external dependency results in degraded operation rather than total outage.
4. AI/LLM Resilience Architecture
AI systems introduce a new class of resilience challenge that enterprises are poorly prepared for. When a primary AI provider — say, OpenAI or Anthropic — experiences an outage, enterprises that have built AI-dependent workflows with no fallback lose those workflows entirely. Sovereign AI resilience requires multi-model architecture: primary provider plus fallback provider plus local inference capability. Models like Llama 3.3 and Mistral now enable on-premises inference on commodity GPU hardware, providing a local fallback when cloud AI APIs are unavailable.
The reference architecture below shows a complex ecosystem that needs to be thought through:
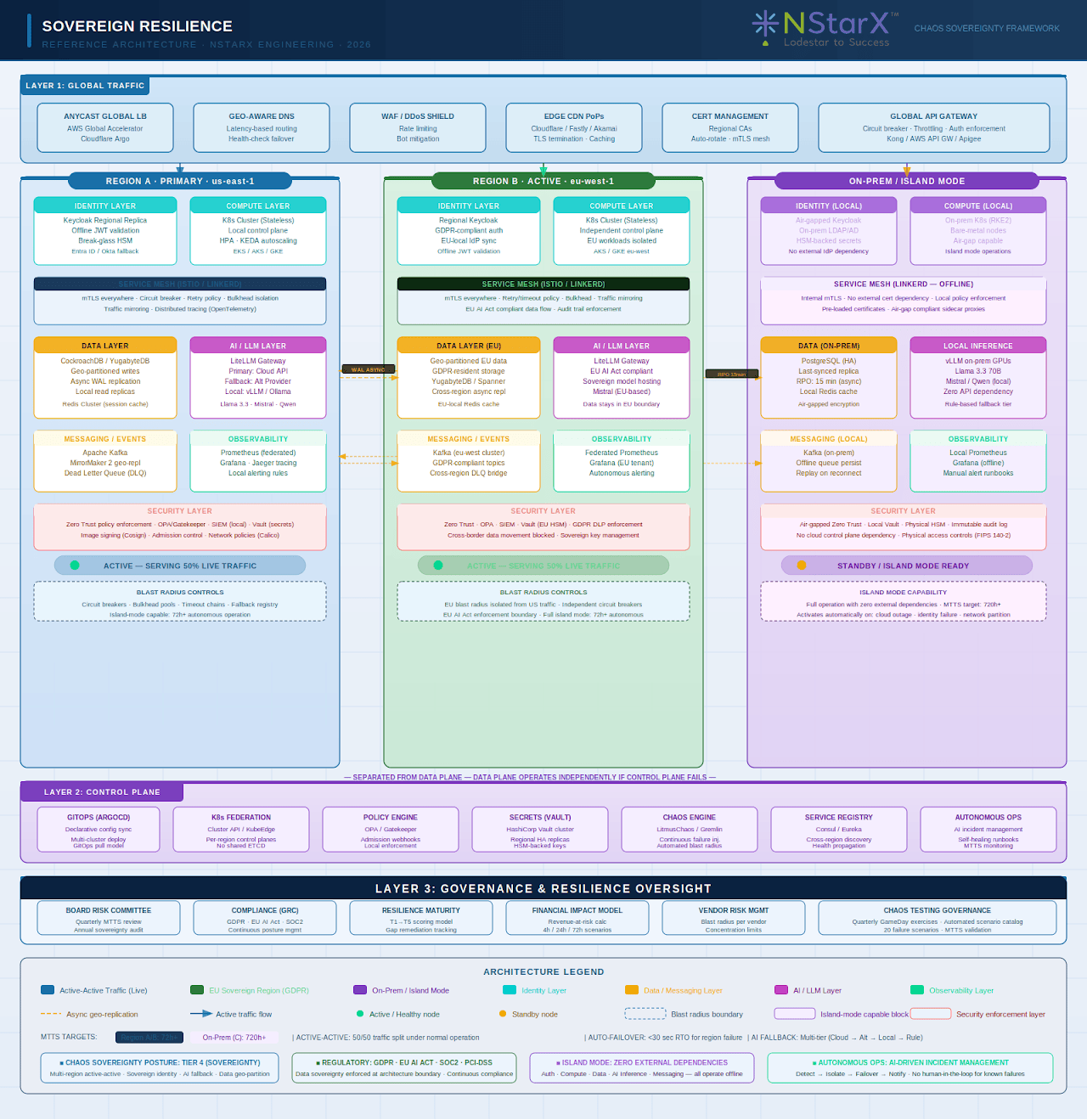
Figure 1: NStarX Sovereign Resilience Reference Architecture
A sovereign AI architecture routes requests dynamically: cloud AI for performance, alternative provider for fallback, local model for survivability.
5. Graceful Degradation
Not all features are equal. A sovereign resilience architecture explicitly defines degraded operating modes for each system layer. An e-commerce platform might degrade from real-time inventory to cached inventory, from personalized recommendations to static featured products, from instant payment processing to queued deferred payments. These degraded modes should be pre-built, pre-tested, and automatically activated. Graceful degradation is not failure. It is designed survival.
The Geopolitical Dimension
Chaos Sovereignty is not only an engineering problem. It is a geopolitical one. Three intersecting forces are reshaping enterprise infrastructure strategy at the nation-state level.
Data Sovereignty
GDPR, the EU AI Act, India’s DPDP Act, and emerging data localization laws in over 60 countries are requiring enterprises to hold specific data within specific borders. An architecture built on a single global cloud with centralized data lakes cannot comply without significant re-engineering. Geo-partitioned data architecture — where data is stored, processed, and replicated within its originating jurisdiction — is no longer optional for global enterprises.
AI Sovereignty
Governments including the EU, India, UAE, Saudi Arabia, and Japan are actively building or mandating sovereign AI infrastructure — LLMs trained on national data, hosted on national compute, operated under national governance. Enterprises operating in these jurisdictions must design for a world where AI models are not hosted on American hyperscaler APIs but on regionally controlled infrastructure with different capability profiles and latency characteristics.
Semiconductor and GPU Supply Chain Risk
The 2022 CHIPS Act, US export controls on advanced semiconductors to China, and NVIDIA’s constrained H100/H200 supply have demonstrated that enterprise AI strategy is vulnerable to geopolitical semiconductor policy. Enterprises building AI infrastructure on the assumption of unlimited GPU availability are operating on a fragile premise. Sovereign resilience planning must include GPU capacity strategy — including cloud GPU reservations, on-premises inference clusters, and model efficiency strategies that reduce GPU dependency.
The CIO Sovereign Resilience Checklist
For CIOs and CTOs evaluating their organization’s resilience posture, these are the questions that define the gap between an availability-optimized enterprise and a sovereign, survivable one:
- Can our core transaction systems operate for 72+ hours if every cloud provider we use goes offline simultaneously?
- Does our identity architecture have a fallback that does not depend on the same identity provider?
- Can our AI-powered workflows fail over to an alternative model or local inference automatically?
- Is our data replicated across jurisdictions in a way that meets our regulatory obligations in every region we operate?
- Have we simulated a complete us-east-1 failure in the past 90 days?
- Do we know the blast radius of our top 10 SaaS dependencies?
- Is our control plane separated from our data plane at a regional level?
- Do we have a defined degraded operating mode for every customer-facing system?
- Have we modeled the revenue impact of a 4-hour, 12-hour, and 72-hour regional outage?
- Does our board receive a quarterly infrastructure sovereignty briefing?
The Survivable Enterprise
The enterprises that will lead the next decade are not those with the highest uptime SLAs. They are those that have architected for independence, designed for degradation, and built the organizational muscle to operate through chaos.
Chaos Sovereignty is not paranoia. It is engineering discipline applied to the reality of a hyper-connected, geopolitically fragmented, AI-dependent world. The infrastructure ecosystem is more powerful than ever — and more brittle. The enterprises that understand this will build architectures that can survive anything. The ones that don’t will be headlines.
The question is not whether your infrastructure will face a systemic failure. It is whether your enterprise is designed to survive one.
NStarX Inc. provides AI-native product and platform engineering services under a Service-as-Software delivery model. This blog post is part of our Sovereign Resilience research series. A companion whitepaper with reference architectures, risk frameworks, and maturity models is available separately.