Tokenomics, Memory Shortage, GPU Economics, and the Rise of System-Level Software Engineering
How Infrastructure Scarcity Is Forcing the Largest Transformation in Software Engineering Since the Cloud
Software engineering is undergoing a massive generational discontinuity. As agentic AI multiplies token consumption and infrastructure scarcity strains budgets, organizations can no longer ignore the economics of compute. Download the white paper to discover how to navigate the memory bandwidth bottleneck, leverage the CPU resurgence, and restructure your engineering organization for an AI-native future.
GPU scarcity, token inflation, and the architectural imperative that your engineering team cannot afford to ignore.
Something fundamental shifted in enterprise AI over the past eighteen months, and most engineering organizations have not yet registered what happened or what it means for how they build software.
The shift is this: the cost of AI inference — measured in GPU-hours, memory bandwidth, and tokens consumed — has moved from an afterthought to a primary architectural constraint. Not a secondary one. Not a concern for the FinOps team to worry about after deployment. A first-class constraint that belongs in the same conversation as latency, reliability, and security.
This post is a teaser for a comprehensive white paper NStarX is releasing on the confluence of forces driving this transformation: GPU market economics, CPU resurgence, tokenomics, context engineering, and the organizational redesign that AI-native software development demands. What follows are the sharpest edges of that argument — the parts that should make any CTO, VP of Engineering, or platform architect pause and reconsider some assumptions.
1. The GPU is not your bottleneck. Memory is.
The conventional narrative about enterprise AI infrastructure focuses on GPU availability and FLOPS. This is the wrong frame. The actual binding constraint in 2026 is memory — VRAM capacity, memory bandwidth, and the economics of moving data between compute and storage.
A 70B-parameter model in BF16 requires approximately 140 GB of VRAM for weights alone, before activations or key-value cache. An H100 has 80 GB. A single H200 has 141 GB. Running frontier models at scale requires either multi-GPU configurations with NVLink coordination overhead, or aggressive quantization with accuracy tradeoffs that must be validated per use case. Neither option is free.
Meanwhile, the Blackwell B200 and the GB200 NVL72 rack configurations are raising the stakes further — 192 GB HBM3e per GPU, 1.8 TB/s NVLink bandwidth, and cooling requirements that effectively concentrate frontier AI infrastructure inside hyperscalers and sovereign AI programs. For the enterprise buyer, this means the GPU capacity equation is getting harder, not easier, even as model performance improves.
The engineers who understand memory hierarchy, quantization tradeoffs, and inference routing will command premium compensation for the next decade. These are systems skills — not AI skills.
The practical implication: engineering teams need to stop asking ‘which model should we use?’ in isolation and start asking ‘what is the memory footprint, bandwidth requirement, and per-token cost of this model at our expected request volume?’ These are not the same question.
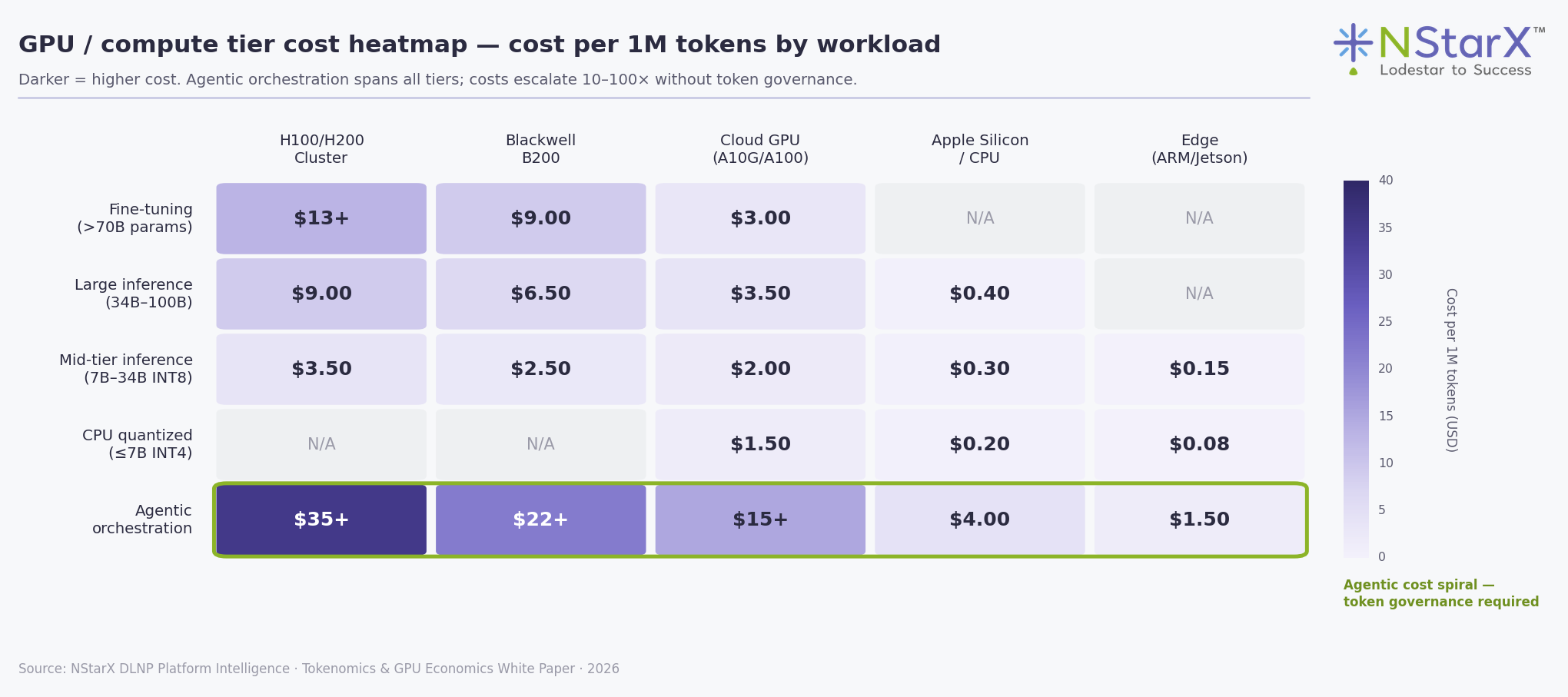 Figure 1: GPU / compute tier cost heatmap — cost per 1M tokens by workload type. Agentic orchestration (bottom row) spans all tiers and escalates rapidly without token governance.
Figure 1: GPU / compute tier cost heatmap — cost per 1M tokens by workload type. Agentic orchestration (bottom row) spans all tiers and escalates rapidly without token governance.
| Workload | H100/H200 Cluster | Blackwell B200 | Cloud GPU (A10G/A100) | Apple Silicon / CPU | Edge (ARM/Jetson) |
|---|---|---|---|---|---|
| Fine-tuning (>70B params) | $13+ | $9.00 | $3.00 | N/A | N/A |
| Large inference (34B–100B) | $9.00 | $6.50 | $3.50 | $0.40 | N/A |
| Mid-tier inference (7B–34B INT8) | $3.50 | $2.50 | $2.00 | $0.30 | $0.15 |
| CPU quantized (≤7B INT4) | N/A | N/A | $1.50 | $0.20 | $0.08 |
| Agentic orchestration | $35+ | $22+ | $15+ | $4.00 | $1.50 |
Source: NStarX DLNP Platform Intelligence · Tokenomics & GPU Economics White Paper · 2026
2. The CPU is back, and it is more important than you think.
For two years, the AI industry operated on an unexamined assumption: GPUs handle AI workloads, CPUs handle everything else. That assumption has been quietly demolished by quantization algorithms, inference optimization frameworks, and the economics of what ‘everything else’ actually means at enterprise scale.
Modern CPUs — AMD EPYC Genoa, Intel Xeon Sapphire Rapids, Apple M3 and M4 — deliver extraordinary memory bandwidth for their cost. The Apple M3 Ultra’s unified memory architecture provides 192 GB of memory accessible at 800 GB/s bandwidth, eliminating the CPU-GPU transfer bottleneck entirely. Running a quantized 70B model locally on a single Mac Studio is not theoretical anymore. It is in production at organizations that have figured out where GPU inference is economically justified and where it is not.
The business case is stark: CPU inference for a 7B quantized model costs 10–20× less than equivalent GPU inference. For the enormous category of enterprise AI tasks that do not require frontier-model capability — document summarization, classification, routine code generation, embedding generation, context preprocessing — the correct compute tier is frequently CPU, not GPU.
This is not a downgrade. It is a routing decision. The organizations that are building intelligent inference routing — matching request characteristics to the most cost-efficient compute tier in real time — are compounding a cost advantage that will be very difficult for late movers to close.
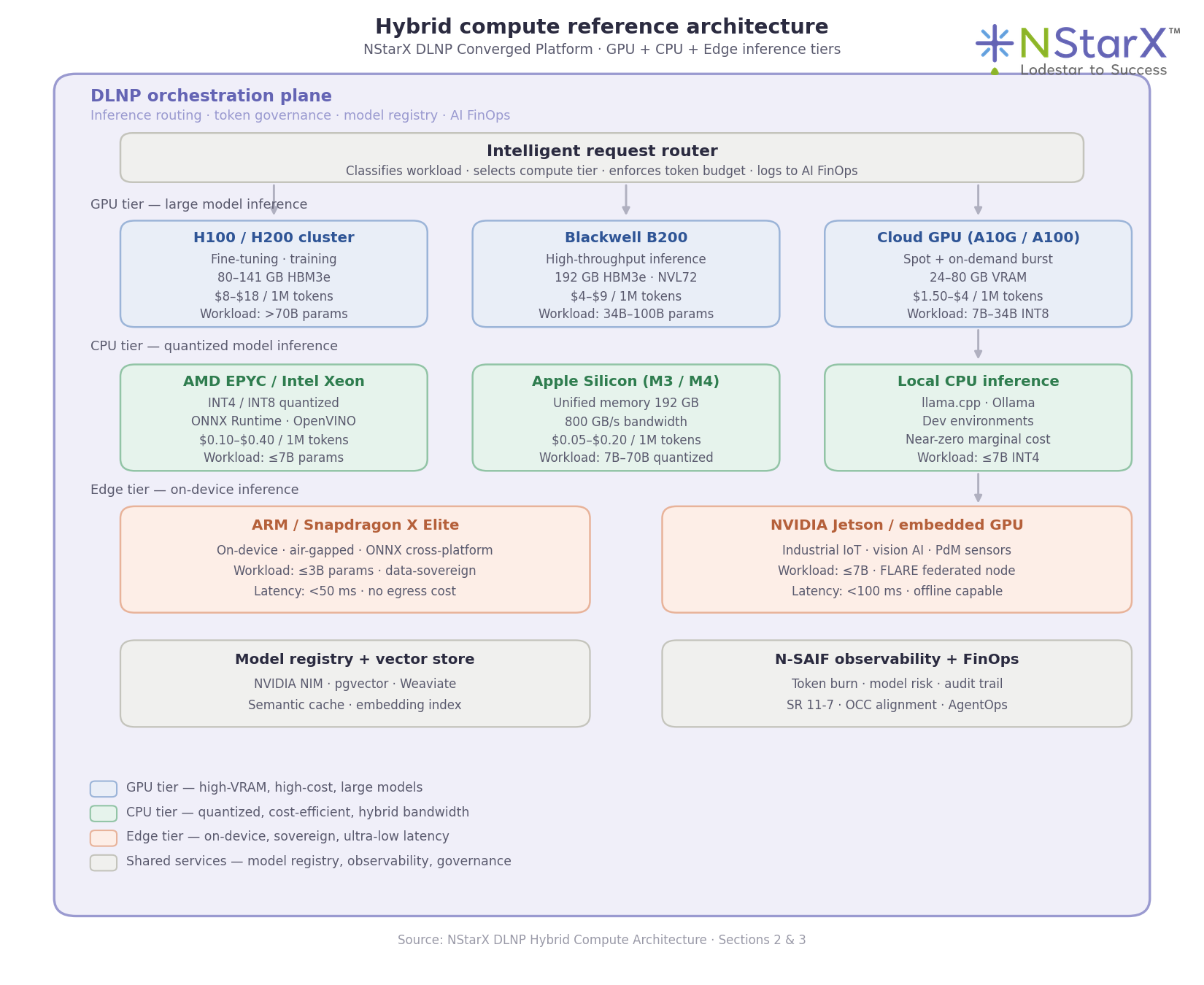 Figure 2: NStarX hybrid compute reference architecture — intelligent request routing across GPU, CPU, and edge inference tiers, governed by the DLNP orchestration plane and N-SAIF observability.
Figure 2: NStarX hybrid compute reference architecture — intelligent request routing across GPU, CPU, and edge inference tiers, governed by the DLNP orchestration plane and N-SAIF observability.
3. Token costs are becoming a board-level line item. Most organizations are not ready.
Here is a number that stops conversations: a 500-person enterprise knowledge workforce using multi-agent AI workflows without token governance is plausibly spending $150,000 to $500,000 per month on inference costs alone. Not cloud compute broadly. Not software licenses. Specifically inference tokens.
This is not a worst-case scenario. It is what happens when agentic AI systems are deployed without understanding how token consumption compounds through agent chains. A single user query to a standard LLM might consume 1,000–2,000 tokens. The same query routed through a planner agent that decomposes the task, delegates to three specialist agents, each of which retrieves context from a vector store and reasons across retrieved chunks, then synthesizes and reviews a response — that same query might consume 100,000–400,000 tokens. This is the architecture that most AI platform vendors are selling. Almost none of them lead with token economics.
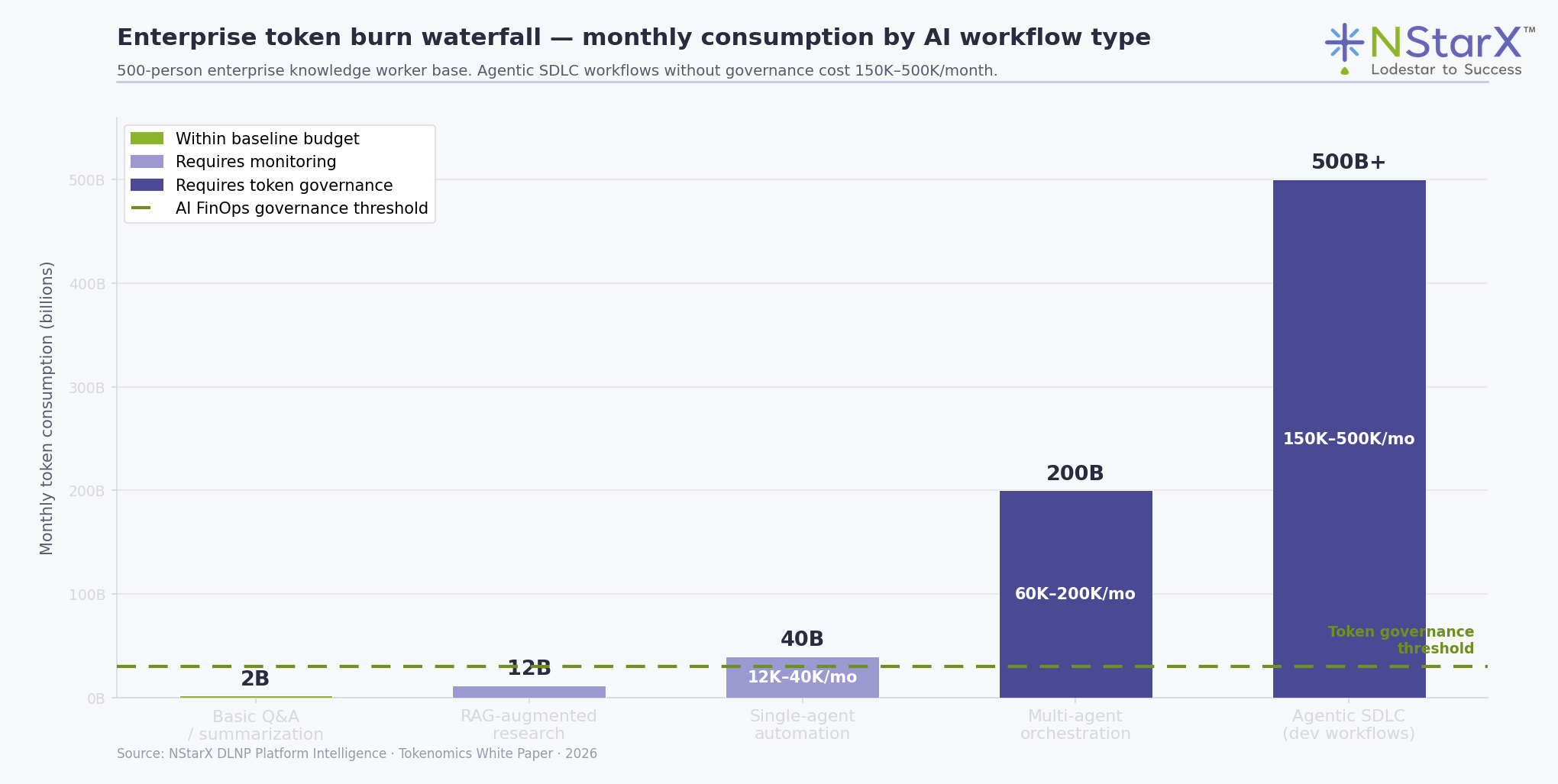 Figure 3: Enterprise token burn waterfall — monthly consumption by AI workflow type for a 500-person enterprise. Agentic SDLC workflows without governance cross the $150K/month threshold.
Figure 3: Enterprise token burn waterfall — monthly consumption by AI workflow type for a 500-person enterprise. Agentic SDLC workflows without governance cross the $150K/month threshold.
The compounding factors are well understood once you know what to look for. Agent chain depth multiplies token usage 2–5× per reasoning hop. RAG retrieval adds 3,000–8,000 tokens of context per call. System prompts and tool descriptions, repeated on every agent invocation, silently consume 500–2,000 tokens before any reasoning begins. Multi-agent consensus patterns multiply base cost by the number of participating agents.
Five drivers of agentic token cost escalation
- Agent chain depth: each additional reasoning hop multiplies consumption 2–5×
- RAG overhead: retrieved context adds 3,000–8,000 tokens per retrieval call
- Context duplication: system prompts paid on every agent invocation, not just once
- Reflection loops: chain-of-thought and self-review add 15–40% overhead per step
- Multi-agent consensus: voting or review patterns multiply by number of agents
The solution is AI FinOps — a discipline borrowed from cloud cost management and applied to token consumption. Token budgets per workflow. Per-module context caps enforced at the routing layer. Semantic deduplication to eliminate redundant retrievals. Model tier routing that automatically selects the least expensive model capable of handling a given request class. These are not exotic techniques. They are standard engineering practices applied to a new resource class. The organizations that implement them now will have a structural cost advantage over those that wait.
| Maturity level | Monthly cost vs baseline |
|---|---|
| L1 — Ad hoc (no governance) | +300–500% over budget |
| L2 — Aware (monitoring only) | +100–200% over budget |
| L3 — Managed (prompt optimization, tiering) | Within 30% of budget |
| L4 — Optimized (caching, routing, dedup) | Within budget |
| L5 — AI-Native (FinOps embedded in SDLC) | Below budget — savings reinvested |
4. Your monolith is the most expensive thing in your AI budget.
This is the argument that tends to land hardest with engineering leaders, because it reframes a technical architecture decision as a financial one.
When an AI agent needs to modify, review, or test code in a monolithic application, it must load the relevant context before it can reason about anything. In a well-structured monolith, that might mean loading a file of 2,000–5,000 lines. In the kind of production monoliths that exist in most enterprises — with global state, implicit dependencies, cross-cutting concerns scattered across the codebase, and 10,000-line files that have accreted over a decade — an agent may need 50,000–100,000 tokens of context just to orient itself before doing any useful work. At current inference prices, that context load alone costs more per session than the same task performed on a well-decomposed modular system.
The modular architecture does more than reduce context cost. It creates the conditions for reliable agentic reasoning. An agent operating on a bounded module with a typed interface, single responsibility, and explicit state management has a dramatically higher success rate than an agent trying to navigate implicit dependencies and global mutable state. The quality improvement is not incidental — it is architectural.
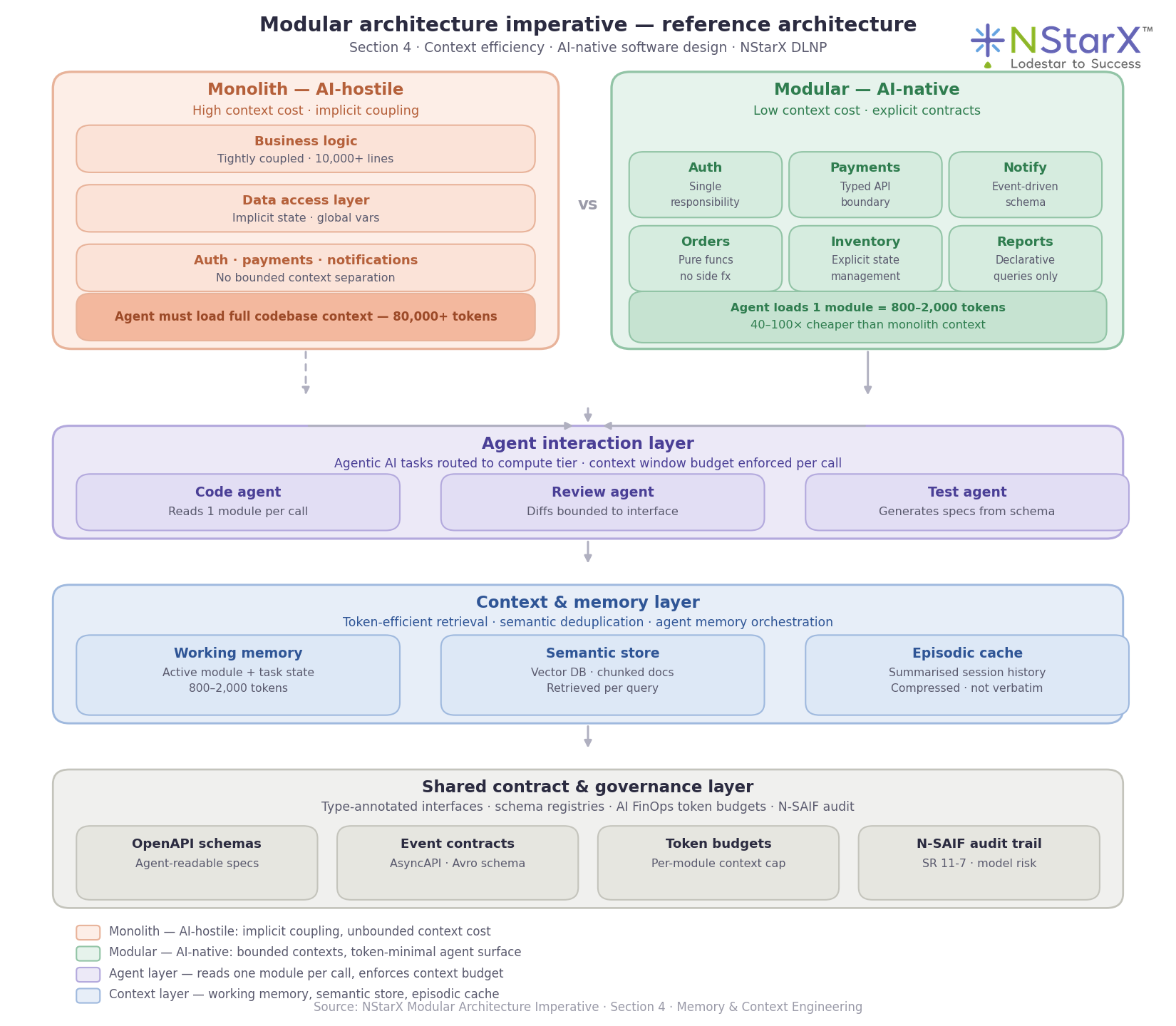 Figure 4: Modular architecture imperative — AI-hostile monolith (left) vs AI-native bounded-context modules (right), with agent interaction and context memory layers. Agent loads one module at 800–2,000 tokens vs 80,000+ for the monolith.
Figure 4: Modular architecture imperative — AI-hostile monolith (left) vs AI-native bounded-context modules (right), with agent interaction and context memory layers. Agent loads one module at 800–2,000 tokens vs 80,000+ for the monolith.
The monolith is not just a technical liability. It is a recurring inference cost that compounds every time an agent touches your codebase. Modular architecture is an economic decision.
The practical path forward is not a big-bang rewrite. It is an Engineering Maturity Arc: identify the highest-traffic agent interaction surfaces in your codebase, decompose those surfaces into bounded modules with explicit interfaces first, establish the context engineering standards and schema registries that make those modules agent-readable, and build outward from there. NStarX’s 12-week MVP motion operationalizes exactly this sequence — delivering a modular AI-native baseline within an existing enterprise engineering organization without disrupting production systems.
5. The skills that are disappearing and the ones that become premium.
The most important conversation engineering leaders are not having with their teams is about which skills are becoming obsolete and which are becoming scarce. This is not a comfortable conversation, but the organizations that have it now will be in a vastly better position in 2027 than those that avoid it.
| Skills declining in value (2026–2030) | Skills becoming premium (2026–2035) |
|---|---|
| Manual boilerplate code generation | Context engineering and prompt architecture |
| Hand-written unit tests for standard patterns | Agent orchestration and multi-agent system design |
| Documentation written from scratch | Inference economics and token governance (AI FinOps) |
| Manual code review of syntax/style issues | AI observability and AgentOps |
| Basic debugging of deterministic systems | Failure domain engineering for agentic systems |
| SQL query construction for standard patterns | Model risk governance and AI audit trail design |
| API integration scaffolding | Human-agent workflow design and collaboration patterns |
The developer who thinks at the function level — writing code that does one thing correctly — is doing necessary but increasingly automated work. The developer who thinks at the system level — reasoning about memory hierarchies, inference economics, agent coordination, failure domains, and the organizational implications of autonomous systems — is doing work that will be in demand for the next decade and is not yet well-supplied.
This is not a prediction that developers will be replaced. It is a prediction that the nature of high-value engineering work is changing faster than engineering education and organizational culture can absorb, and that the gap between teams that adapt and teams that do not will manifest as compounding capability and cost differentials.
What this means for your organization — and where NStarX fits.
NStarX is the AI-native platform engineering company built specifically for the transformation described in this post. Our DLNP Converged Platform operationalizes intelligent inference routing, token governance, federated learning, and agentic delivery across financial services, pharma, manufacturing, media, and PE-backed enterprise portfolios.
We built N-SAIF — our AI control framework aligned to SR 11-7 and OCC guidance — because regulated enterprises cannot adopt agentic AI without a governance layer that satisfies model risk requirements. We partnered with NVIDIA at the SVAR level because the GPU economics argument above is not theoretical — it requires access to the infrastructure and technical resources that move inference costs from the top of the P&L toward the optimized column. And we deliver inside a 12-week MVP motion because the organizations that are compounding advantage right now are the ones that are already in production, not still in proof-of-concept.
NStarX DLNP capabilities directly addressing this post’s imperatives
| NStarX DLNP capabilities directly addressing this post’s imperatives |
|---|
| Intelligent inference routing: GPU → CPU → Edge based on real-time workload economics |
| Token FinOps: per-module context caps, semantic dedup, token burn dashboards |
| N-SAIF governance: model risk framework aligned to SR 11-7, OCC, and enterprise audit requirements |
| NVIDIA FLARE federated learning: cross-border model training without data centralization |
| Engineering Maturity Arc: modular architecture baseline delivered in 12-week sprints |
| Agentic SDLC: multi-agent code, review, test, and deploy workflows with human governance gates |
Download Whitepaper
Tokenomics, Memory Shortage, GPU Economics, and the Rise of System-Level Software Engineering
How Infrastructure Scarcity Is Forcing the Largest Transformation in Software Engineering Since the Cloud
Software engineering is undergoing a massive generational discontinuity. As agentic AI multiplies token consumption and infrastructure scarcity strains budgets, organizations can no longer ignore the economics of compute. Download the white paper to discover how to navigate the memory bandwidth bottleneck, leverage the CPU resurgence, and restructure your engineering organization for an AI-native future.
If the arguments in this post resonated — if you recognized your own infrastructure costs, your own monolith, your own gap between where your engineering culture is and where the AI-native baseline demands it to be — the conversation starts at nstarxinc.com.