The Architecture of Trust: Why Federated Query Is the Missing
Infrastructure Primitive for Agentic AIHow the query-travels-to-data paradigm unlocks safe, governed, compliant AI agents
Discover why Federated Query is the missing infrastructure primitive for safe, compliant agentic AI. Learn how NStarX’s Converged Platform and 12-week MVP motion bring governed AI deployment to regulated industries.
Why Federated Query is the infrastructure primitive every regulated enterprise needs before they deploy another AI agent.
Let me start with a question that most enterprise AI programs have not honestly answered yet.
When your AI agent retrieves data to answer a question — where does that data actually go?
If you are running a centralised AI architecture — and the majority of enterprises are — the answer is uncomfortable. The data moved. It was ingested into a central store before your agent ever touched it. Your data controllers changed. The consent framework under which that data was originally collected may no longer fully cover what your agent is doing with it today.
In healthcare, financial services, and regulated manufacturing, this is not a theoretical concern. It is the compliance failure waiting to happen. And as enterprises scale up their agentic AI deployments — agents that retrieve, reason, and act autonomously across dozens of data sources — the exposure grows with every new agent you spin up.
There is an architectural answer. It is called Federated Query. And understanding it might be the most important decision your organisation makes about AI infrastructure this year.
The Moment Agentic AI Breaks the Old Rules
There was a time — not long ago — when enterprise AI was essentially an analytical tool. A data scientist would query a warehouse. A dashboard would pull from a reporting layer. The data had already been centralised, cleaned, and governed long before any AI system touched it.
That world is gone.
Agentic AI systems do not wait for pre-prepared datasets. They retrieve context dynamically, at inference time, across multiple systems simultaneously. An agent handling a clinical decision support workflow might, in a single reasoning step, retrieve a patient’s medication history from one system, cross-reference a clinical protocol database, query a drug interaction model, and check a compliance policy — all without a human in the loop.
This is fast. This is powerful. And in a centralised architecture, every one of those retrievals touches data that has already left its original home. Data controllers have changed. Consent frameworks have been silently invoked. And nobody paused to notice.
The diagram below shows exactly what I mean. On the left, the centralised model. On the right, the alternative.
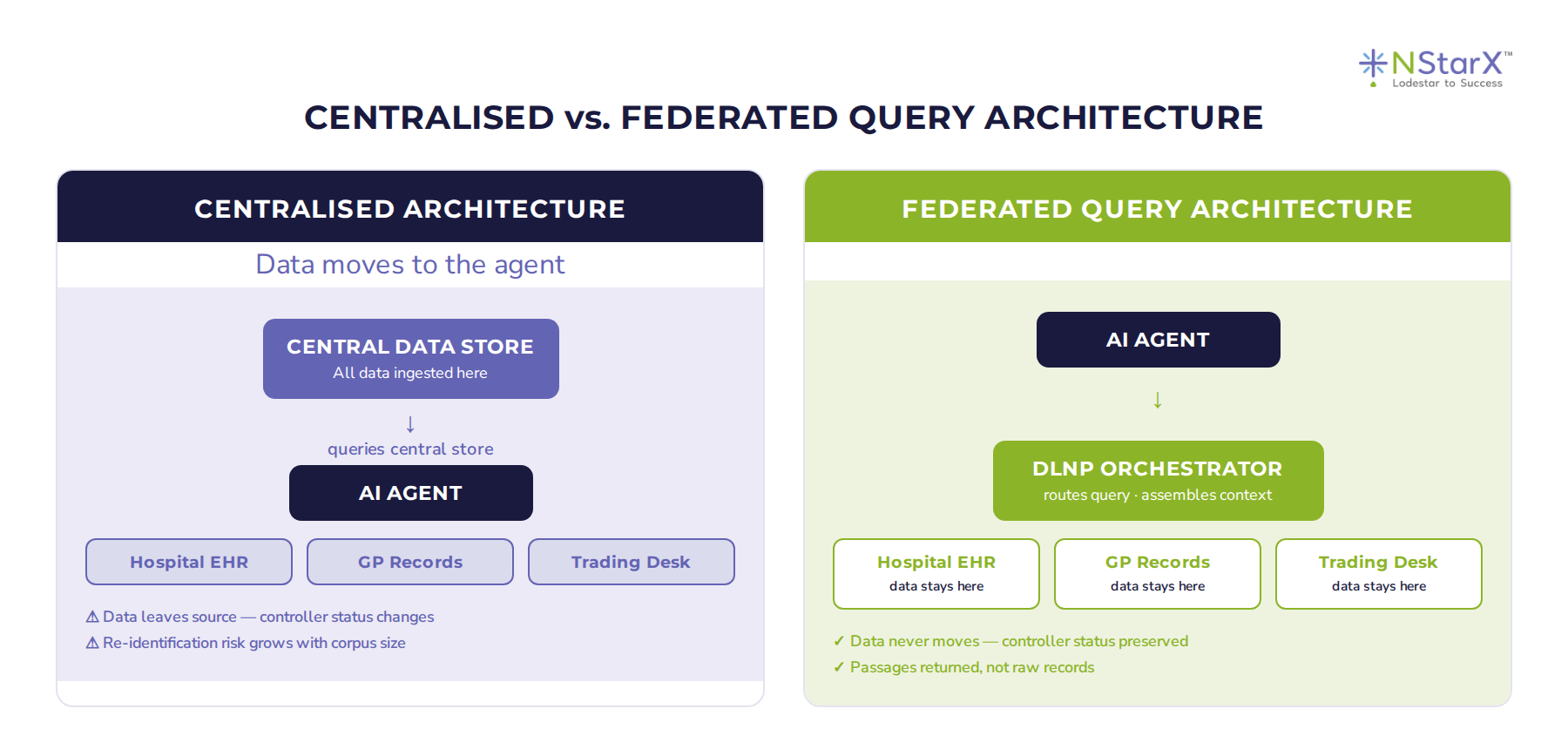
Figure 1: Centralised vs. Federated Query architecture — the fundamental governance difference
The difference is not cosmetic. In a federated architecture, the query travels to the data. In a centralised architecture, the data travels to the query. That single architectural choice determines your entire data governance posture.
The NHS Taught Us Something Important
If you want to understand why this matters, look at what is happening in the UK National Health Service right now. We were recently studying this and we found it to be a very important event.
The NHS has been publicly debating two competing approaches to patient data architecture for the past two years. Option one is the Federated Data Platform, built on Palantir’s Foundry software, which centralises anonymised patient data from hospital trusts into a shared analytical workspace. Option two is federated query architecture, which leaves data exactly where it originated and sends queries out to retrieve results — without any data ever moving.
The NHS is not just choosing a technology. It is deciding who controls patient data for the next decade. That is the same decision every regulated enterprise is implicitly making with every AI deployment.
What makes the NHS case so instructive is the General Practitioners (GP) data problem. GP records in the UK sit entirely outside the hospital trust data model. GPs are the data controllers for those records. Any centralisation approach — even of anonymised data — requires GPs to cede that control.
Federated query solves this cleanly. Because nothing moves, GPs retain their data controller status. Their records can be included in a unified patient view without any change to the governance relationship. The architectural feature that makes federated query attractive in healthcare is exactly the same feature that makes it attractive in financial services, pharma, and manufacturing: the data owner never stops being the data owner.
NHS England’s deployment of federated query architecture for the National Imaging Registry — widely expected to be the first component of the Single Patient Record — is the clearest signal yet that regulated-data infrastructure is moving in this direction.
How Federated Query Actually Works
Let me walk through the mechanics, because the concept is simple once you see it clearly.
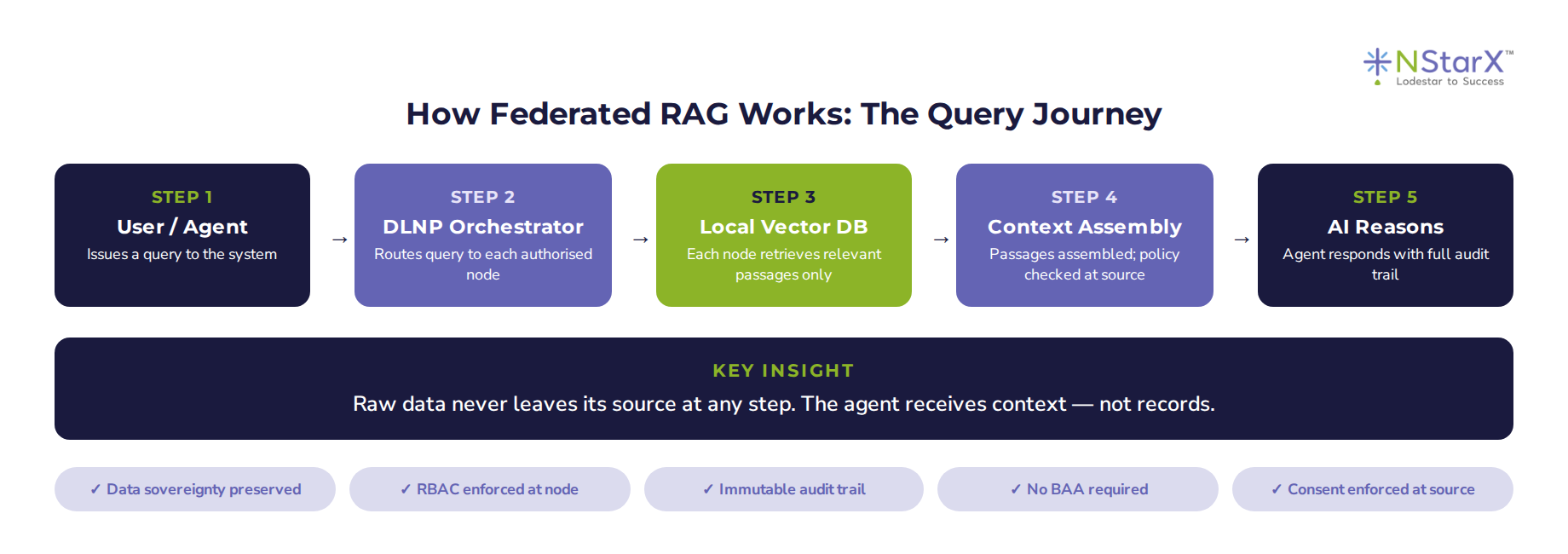
Figure 2: The five-step journey of a federated query — from agent request to assembled context
The agent issues a query. The DLNP orchestrator routes that query to each authorised data node. Each node’s local vector database retrieves only the relevant passages — not raw records. Those passages are assembled into a context object by the orchestration layer, with policy enforcement verified at source. The agent reasons over that assembled context and produces a response.
At no point in that process did any raw data leave its source. The agent received context, not records. The audit trail was written at the node level, not in a central store. And every access decision was governed by the policy that the data owner — the hospital trust, the GP practice, the trading desk — configured for their own data.
Here is what that looks like when you compare it directly to a centralised architecture across the dimensions that matter most to a CTO or CISO:
| Dimension | Centralised Architecture | Federated Query Architecture |
|---|---|---|
| Data controller after AI access | May transfer to platform operator | Always retained by originating org |
| Re-identification risk | Grows with central corpus size | Eliminated — no corpus assembled |
| Consent operationalisation | At ingestion (may not cover agent use) | At source, at query time |
| Failure mode | Central outage = all agents affected | Node outage = only that node affected |
| GP / partner data inclusion | Requires data transfer | Included on equal terms, no transfer |
| Audit trail location | Central store | At source — most defensible for regulators |
| BAA required with AI vendor? | Yes, in most healthcare deployments | No — data never leaves covered entity |
The Compliance Heatmap: Which Industries Need This Most
Federated query is not equally urgent for every enterprise. But for regulated industries, the urgency is high — and it is not decreasing. The heatmap below shows how the major regulatory frameworks map to each vertical, and where the pressure to adopt a federated architecture is most acute.
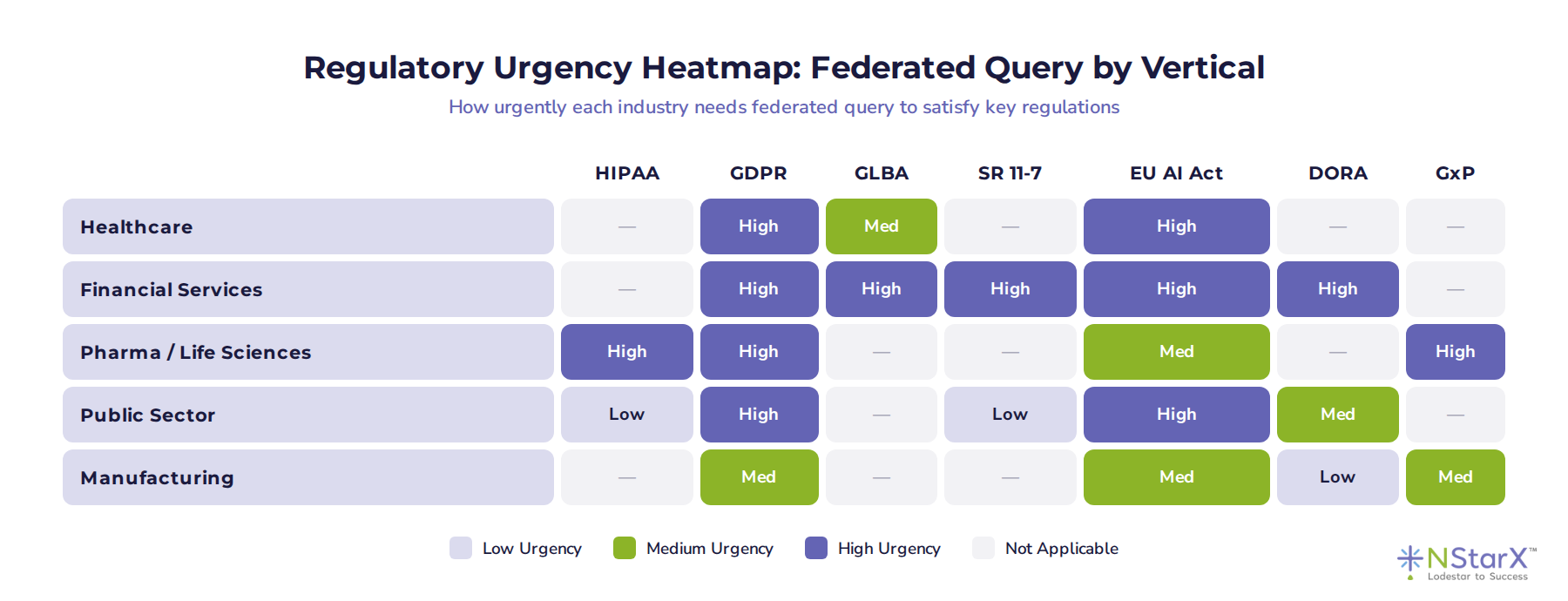
Figure 3: Regulatory urgency heatmap — where federated query is a compliance imperative, not just a preference
A few things jump out:
- Financial services is the highest-urgency vertical overall. SR 11-7, GLBA, GDPR, EU AI Act, and DORA all apply simultaneously — and each creates its own data sovereignty requirement. A single centralised AI platform serving a global bank almost certainly touches data that no single governance framework can fully cover.
- Healthcare urgency is concentrated but intense. HIPAA and GDPR are near-absolute requirements for data architecture in US and EU health systems. The lack of a required BAA when deploying within a covered entity’s own perimeter is a significant commercial and compliance advantage.
- Pharma carries an underappreciated burden. GxP compliance for manufacturing data, GDPR for clinical trial participants across EU member states, and HIPAA for US-facing clinical operations create a multi-framework compliance environment where centralisation becomes genuinely difficult to defend.
Federated Query + Federated Learning: The Complete Stack
Here is where it gets strategically interesting.
Federated Query solves the inference-time problem: how do agents retrieve regulated data without moving it? But there is a parallel problem at training time: how do models improve on regulated data without centralising it?
The answer to that second question is Federated Learning — and the two approaches are direct architectural complements.
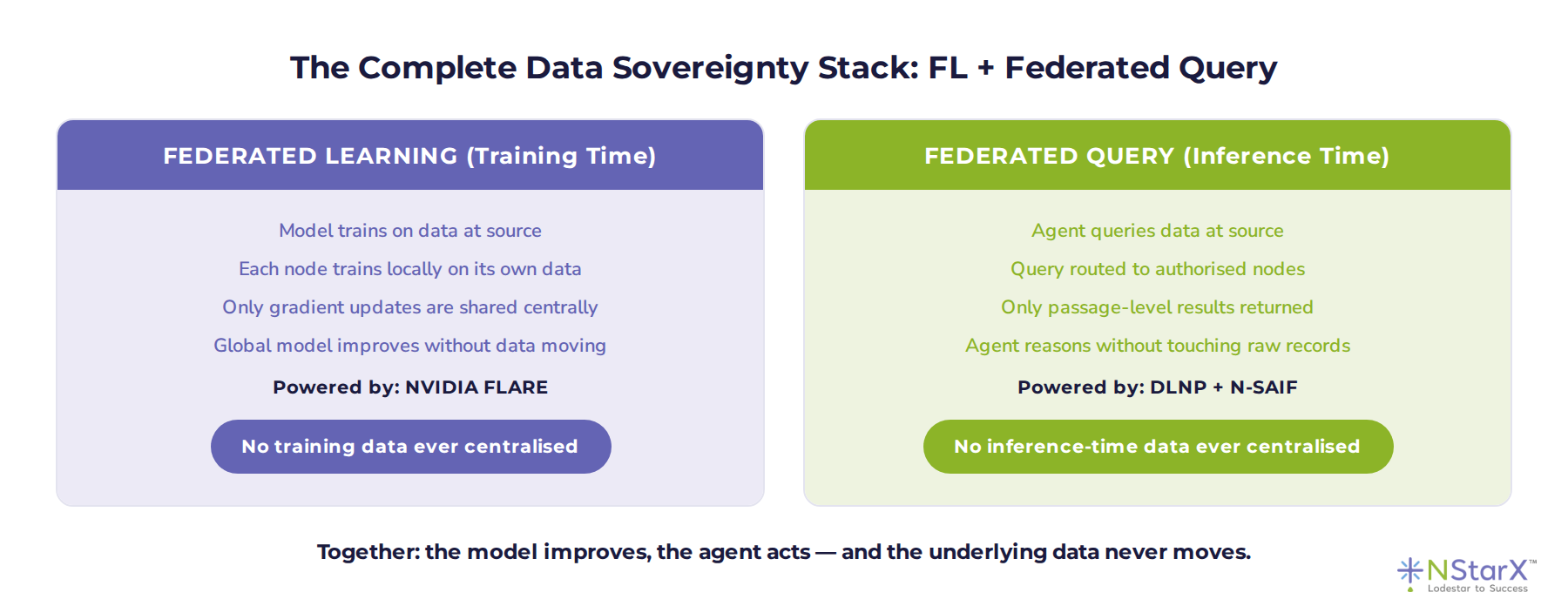
Figure 4: The complete data sovereignty stack — Federated Learning for training, Federated Query for inference
At NStarX, we run Federated Learning via NVIDIA FLARE — the same platform NHS England, Novartis, and major financial institutions have evaluated for privacy-preserving AI. Combined with the DLNP Converged Platform’s federated query orchestration, this gives enterprises a complete answer to the data sovereignty question:
- No training data ever centralised.
- No inference-time data ever centralised.
- The model improves continuously. The agent acts accurately. The underlying data never moves.
Four Questions to Ask Your AI Platform Vendor Today
If you are evaluating AI infrastructure for a regulated industry environment — or already deploying agentic AI and wondering whether your data governance is actually sound — here are the four questions that cut through the noise:
| Question | Why It Matters | Red Flag Answer |
|---|---|---|
| Does data move to the AI system, or does the query move to the data? | Determines whether data controller relationships change | “We ingest data into our platform for optimal performance” |
| Who is the data controller after the platform ingests my data? | Centralised platforms often become data processors — or controllers — of your regulated data | “You retain ownership” (without confirming controller status) |
| How is patient / customer consent operationalised at inference time? | Consent at ingestion may not cover agentic use at inference | “We applied consent policies at the data warehouse layer” |
| What does your audit trail cover, and where is it stored? | Regulators want source-level traceability — not just central log entries | “All queries are logged in our central audit database” |
What NStarX Does Differently
NStarX does not build AI systems that require your data to move. We build AI systems that move to your data. That is not a marketing position. It is an architectural commitment with compliance consequences.
Our Converged Platform provides the enterprise orchestration layer that federated query requires to work reliably at scale — handling the hard parts: query routing across heterogeneous systems, context assembly with source-level policy enforcement, hybrid retrieval (BM25 + vector), and an immutable audit trail written at each node.
The N-SAIF governance framework aligns this with NIST AI RMF, the EU AI Act, HIPAA, SR 11-7, and GDPR — not as a post-hoc compliance overlay, but as architectural properties baked into how the system works.
The 12-Week Path from Zero to Production
We have proven a 12-week MVP motion that delivers a working Federated RAG system — plus a full compliance attestation package — to a CDO within one quarter. The deliverable is not a proof of concept. It is a production-grade system that your CISO can present to a regulator.
| Phase | What Gets Built | What You Walk Away With |
|---|---|---|
| Weeks 1–2: Foundation | DLNP orchestrator deployed; SSO integrated; 2–3 data domains prioritised | Technical environment live; query test cases documented |
| Weeks 3–4: Node Build | Local vector databases at each node; corpus ingested and embedded | Per-node RAG retrieval operational; retrieval quality baselined |
| Weeks 5–6: Cross-Node | Cross-node routing; context assembly; export policies configured | First end-to-end federated query — spans all nodes |
| Weeks 7–8: Optimisation | Hybrid retrieval tuned; pilot users testing | Query quality at baseline; CISO reviews sovereignty audit trail |
| Weeks 9–10: Compliance | Data flow map; GDPR/HIPAA attestation; audit trail packaged | Compliance documentation package; CDO briefing delivered |
| Weeks 11–12: Expansion | Performance optimised; expansion scope scoped and priced | MVP report + expansion business case for board |
The Architecture Decision Is Happening Right Now
The NHS is making this choice in public, with parliamentary scrutiny. Financial services firms are making it under SR 11-7 examination. Pharma companies are making it under GxP and GDPR audit. Every regulated enterprise is making it, implicitly, with every agentic AI deployment — whether they realise it or not.
Most organisations have defaulted to centralisation not because it is the right answer for regulated data, but because centralised tools came first and compliance questions came second. The cost of that default will become apparent as regulators begin scrutinising AI data flows in earnest — and 2026 is the year that scrutiny is arriving.
Federated Query is the architectural foundation that makes it possible to move fast with AI without leaving your data governance behind. It is available now. The 12-week MVP makes it accessible within a single budget cycle.
If you want to understand what this looks like for your organisation specifically — reach out to NStarX Inc at info@nstarxinc.com. The conversation starts with four questions. You already have them.
Download Whitepaper
The Architecture of Trust: Why Federated Query Is the Missing
Infrastructure Primitive for Agentic AI
How the query-travels-to-data paradigm unlocks safe, governed, compliant AI agents
Discover why Federated Query is the missing infrastructure primitive for safe, compliant agentic AI. Learn how NStarX’s Converged Platform and 12-week MVP motion bring governed AI deployment to regulated industries.