AUTHOR: NStarX Engineering team pens a 25 minutes read on how RAG in an enterprise is very different than chatGPT and other tools available to consumers. NSTARX engineering team tries to capture the nuances of the enterprise challenges and needs
Executive Summary
As enterprises rush to deploy generative AI solutions, Retrieval-Augmented Generation (RAG) has emerged as the foundational architecture for delivering accurate, context-aware responses grounded in organizational knowledge. However, the quality of RAG outputs depends entirely on the quality of the underlying content. This comprehensive guide explores how proper content lifecycle management, strategic chunking, intelligent metadata design, and rigorous de-duplication transform RAG from a promising prototype into a production-grade enterprise system that delivers measurable ROI while eliminating costly hallucinations.
1. Why RAG is Replacing Search and Becoming Integral to Enterprise AI
The RAG Revolution: From Search to Intelligent Retrieval
Traditional enterprise search has served organizations for decades, but it operates on a fundamentally limited paradigm: keyword matching and ranked results that still require humans to read, interpret, and synthesize information. Retrieval-Augmented Generation represents a paradigm shift—instead of returning a list of documents, RAG systems retrieve relevant context and generate precise, natural language answers grounded in verified enterprise data.
Organizations report hallucination reductions between 70% and 90% when RAG pipelines are introduced, validating the technology for mission-critical workflows. This dramatic improvement explains why RAG has moved from experimental technology to strategic imperative at remarkable speed.
The Market Opportunity: Understanding RAG’s TAM and SAM
The numbers tell a compelling story about RAG’s explosive growth trajectory:
Total Addressable Market (TAM): The global retrieval-augmented generation market was estimated at USD 1.2 billion in 2024 and is projected to reach USD 11.0 billion by 2030, growing at a CAGR of 49.1% from 2025 to 2030.
Some projections place the market even higher, with estimates reaching USD 40.34 billion by 2035, representing a CAGR of 35.31%. These varying projections reflect the technology’s rapid evolution and expanding use cases, but all point to substantial market expansion.
Serviceable Addressable Market (SAM): North America dominated the RAG market with a 36.4% share in 2024, driven by early enterprise AI budgets, concentrated talent pools, and venture capital funding for specialized tooling startups.
Large enterprises captured 72.2% of the market share in 2024, attributed to their financial and organizational resources needed to invest in advanced RAG technologies. This concentration indicates that while the technology is maturing, significant market capture opportunities remain in mid-market and specialized vertical applications.
Key Market Drivers:
- Over 80% of enterprise data is unstructured, fueling demand for RAG solutions to extract and synthesize relevant information efficiently.
- Enterprises seek scalable, secure, and explainable AI deployments, with RAG at the core becoming a key market driver.
- Microsoft estimates USD 3.70 in value for every USD 1 invested in generative AI programs that embed retrieval pipelines.
Why Enterprises Choose RAG Over Alternatives
RAG has emerged as the preferred approach for 30-60% of enterprise GenAI use cases because it addresses critical limitations of pure LLM approaches:
- Real-time accuracy: RAG systems access current information without costly model retraining
- Explainability: Every generated statement can be traced to source documents, enabling audit trails
- Cost efficiency: Updating knowledge bases is dramatically cheaper than fine-tuning models
- Domain specificity: RAG naturally incorporates proprietary business knowledge that public models lack
- Reduced hallucinations: Grounding responses in retrieved documents dramatically improves factual accuracy
2. Real-World RAG Implementations: Success Stories and Cautionary Tales
Successful Enterprise RAG Deployments
DoorDash: Delivery Support at Scale — DoorDash developed an in-house RAG-based chatbot that combines three key components: the RAG system, LLM guardrail, and LLM judge. When a delivery contractor reports a problem, the system condenses the conversation to grasp the core issue, searches the knowledge base for relevant articles and past resolved cases, then generates contextually appropriate responses. The system maintains quality through continuous monitoring and filtering of responses that violate company policies.
Thomson Reuters: Transforming Customer Service — Thomson Reuters built a RAG solution that helps customer support executives quickly access the most relevant information from a curated database in a chatty interface. The system uses embeddings to find relevant documents from internal knowledge bases, then refines and generates well-structured responses, tailoring answers using retrieved knowledge and reducing hallucinations.
Vimeo: Conversational Video Analysis — Vimeo developed a RAG-based chatbot that enables users to converse with videos. The system summarizes video content, links to key moments, and suggests additional questions. Video transcripts are processed and saved in a vector database using a bottom-up approach with multiple context window sizes.
Siemens: Internal Knowledge Management — Siemens utilizes RAG technology to enhance internal knowledge management through its digital assistance platform, allowing employees to retrieve information from various internal documents and databases quickly. Users input queries for technical questions, and the RAG model provides relevant documents and contextual summaries, improving response times and fostering collaboration.
IBM Watson Health: Clinical Decision Support — IBM Watson for Oncology employs RAG techniques to analyze large datasets, including electronic health records and medical literature, to aid in cancer diagnosis and treatment recommendations. The system can match treatment recommendations with expert oncologists 96% of the time, showcasing RAG’s potential to augment human expertise in medical diagnostics.
When RAG Implementations Fail: Critical Lessons
Despite RAG’s promise, implementation failures are common and costly. Understanding these failure modes is essential for avoiding them:
The 72% Failure Rate Research indicates that 72% of enterprise RAG implementations fail in the first year. This shocking statistic reflects the gap between proof-of-concept demonstrations and production-ready systems.
Common Failure Patterns:
- Poor Data Quality: The most fundamental failure mode stems from inadequate content preparation. Systems trained on duplicate, outdated, or poorly structured content cannot generate reliable outputs regardless of sophisticated retrieval algorithms.
- Inadequate Chunking Strategies: A study of three RAG case studies identified seven failure points, with validation only feasible during operation and robustness evolving rather than designed in at the start. Chunking decisions made early in development often prove inadequate for diverse query types in production.
- Missing Metadata Architecture: Systems that fail to implement comprehensive metadata tagging struggle with context preservation and relevance ranking, leading to incorrect document retrieval.
- Scalability Blindness: The retriever needs to efficiently search through massive, constantly-updated knowledge bases to find the most relevant information for each query, while the generator needs to intelligently incorporate retrieved information. Many implementations that work well with small datasets collapse under enterprise-scale loads.
- Security and Governance Gaps: Successful enterprise RAG systems don’t treat security as an afterthought—they build authorization and compliance frameworks directly into their retrieval architecture.
The 2025 Production Pressure While 2023 was “the year of the demo” and 2024 was about “trying to productionize,” 2025 brings new pressure as organizations face demands to deliver return on investment for AI investments. Many early implementations were rushed to be first-to-market, resulting in “kneecapping of those solutions in order to be the first one to get it into production.”
3. Why Data Quality and Knowledge Ops are Mission-Critical for RAG Success
The Foundation: Content Quality Determines RAG Quality
The principle is simple but unforgiving: garbage in, garbage out. RAG systems amplify the quality—or lack thereof—of underlying content. A sophisticated retrieval algorithm cannot compensate for poorly prepared, inconsistent, or duplicate content.
The Case for Rigorous Knowledge Operations
Knowledge Operations (Knowledge Ops) represents a systematic approach to managing enterprise content throughout its lifecycle, ensuring that every piece of information in the RAG pipeline meets quality standards.
Core Knowledge Ops Principles:
- Content Lifecycle Management: Establish clear processes for content creation, review, update, deprecation, and archival.
- Quality Assurance Gates: Implement validation checkpoints before content enters production systems.
- Continuous Monitoring: Track content usage, relevance, and retrieval patterns to identify improvement opportunities.
- Version Control: Maintain clear audit trails of content changes, essential for regulated industries.
A strong data governance framework is foundational to ensuring the quality, integrity, and relevance of the knowledge that fuels RAG systems. Such frameworks encompass processes, policies, and standards necessary to manage data assets effectively throughout their lifecycle.
The Role of Knowledge Graphs in Enterprise RAG
Knowledge graphs have emerged as a critical component in advanced RAG architectures, addressing limitations that pure vector-based approaches cannot overcome.
Why Knowledge Graphs Matter:
ServiceNow highlighted knowledge graphs as one of three key pieces to their AI fabric, using them primarily to make LLMs deterministic with respect to data held on employees, namely relationships with other employees, services, and integrations.
Unlike flat vector embeddings, knowledge graphs preserve context, enable multi-hop reasoning, and provide explainable retrieval paths. For enterprises managing complex domains with intricate relationships—from legal contracts to technical documentation—this approach transforms how AI systems understand and retrieve information.
Knowledge Graph Benefits in RAG:
- Relationship Preservation: By traversing relationships, RAG applications can infer connections even when information is not directly stated, enabling more comprehensive responses.
- Multi-Source Integration: Knowledge graphs can integrate information from multiple sources, allowing RAG applications to use diverse and complementary knowledge bases, leading to more comprehensive and well-rounded responses.
- Transparency and Explainability: Knowledge graphs provide a transparent representation of the knowledge used in generating responses, which is key for explaining the reasoning behind generated output.
- Precise Retrieval: The primary advantage of GraphRAG over standard RAG lies in its ability to perform exact matching during the retrieval step, particularly valuable in domains where ambiguity is unacceptable, such as compliance, legal, or highly curated datasets.
Implementation Considerations:
Building high-quality knowledge graphs is complex and time-consuming, requiring significant domain expertise. Challenges include extracting entities and relationships from various data sources, integrating them into a coherent graph, ensuring data consistency, and maintaining the graph as information evolves.
4. The Enterprise Cost of AI Hallucinations: Real-World Financial Impact
Understanding the Stakes: When Hallucinations Cost Millions
AI hallucinations aren’t merely technical annoyances—they represent material business risks that can result in regulatory violations, legal liability, customer attrition, and direct financial losses.
Quantifying the Cost
The average cost per major hallucination incident reaches $2.4 million, including legal fees and reputation damage. However, 70-85% reduction is possible with proper detection tools, though only 23% of enterprises use them.
According to Deloitte’s survey, 77% of enterprises fear AI hallucinations, with real costs averaging $2.4M per major incident.
Case Studies: Real Consequences
Air Canada: The Chatbot Liability — An Air Canada chatbot provided incorrect refund information, and the airline had to honor it in court. This single hallucination cost real money, and similar scenarios involving wrong investment advice or compliance guidance carry even greater reputational and financial impact. When the truth emerged about incorrect policy information, the company faced legal consequences and had to disable the bot, damaging customer trust and confidence. The defense that it was the AI’s fault did not work in court or public opinion.
New York City: Municipal Chatbot Mishap — A New York City municipal chatbot designed to help citizens provided advice that was wrong and actually illegal, suggesting actions that would inadvertently break city and federal laws. Had users followed such guidance on topics from food safety to public health, they could have faced fines or other penalties.
Legal Industry: Fabricated Case Citations — The Washington Post reported attorneys across the U.S. filing court documents with AI-generated fake cases. Multiple lawyers faced sanctions, with one New York attorney fined $10,000 for submitting ChatGPT hallucinations as legal precedent.
A federal judge levied $5,000 fines against two attorneys and their law firm when ChatGPT generated made-up legal references and citations for an aviation injury claim.
Google Bard: Market Impact — The Google Bard incident demonstrates how public hallucinations can translate into huge financial and reputational costs. Executives note that if an AI-powered service gives even one piece of false advice or a fake citation, years of customer trust can evaporate instantly.
The Hidden Costs: Productivity Tax and Technical Debt
Beyond headline-grabbing incidents, hallucinations impose continuous “hidden costs” on organizations: Any time AI produces an error, humans must catch and fix it. Software developers using code-generation AI have found that hallucinated code—bugs, wrong APIs—can nullify productivity gains, as they spend extra time debugging AI-written code, sometimes more than if they wrote it themselves.
Companies must also invest in oversight mechanisms including human review and testing, effectively paying a “tax” on AI outputs to ensure quality. All these overheads mean that if hallucinations are frequent, the purported efficiency gains of AI are eroded or even reversed.
Financial Services: Amplified Risk
In finance, where precision and factual accuracy aren’t just nice-to-haves but essential, AI chatbots might invent metrics that sound plausible or incorrectly state stock splits. Standard LLMs frequently hallucinate when handling financial tasks like explaining concepts or retrieving stock prices.
Consider a financial institution where a junior analyst uses an unvetted GenAI extension to speed up due diligence. They paste sensitive, non-public financial data into the chat interface, and the model misrepresents the target company’s liabilities, portraying a healthier financial state than reality. Acting on this flawed data, the firm makes a poor investment decision, leading to direct financial loss.
Healthcare: Life-or-Death Implications
In a healthcare organization, a clinician looking for information on a rare drug interaction queries a medical AI chatbot. The AI fabricates a response, confidently claiming there are no interactions when critical contraindications exist. This represents not just financial risk but potential patient harm.
The Strategic Imperative: RAG as Risk Mitigation
These examples underscore why enterprises are investing heavily in RAG systems. By grounding responses in verified, retrievable documents, RAG dramatically reduces hallucination risk and provides audit trails that traditional LLMs cannot offer.
Regulated industries discovered that hallucinations undermine trust in large language models, driving an enterprise pivot toward retrieval-augmented generation solutions that can ground every answer in verifiable source material.
5. Critical Technical Considerations: Content Lifecycle, Chunking, Metadata, and De-duplication
Content Lifecycle Management: The Foundation of RAG Excellence
Effective RAG systems require systematic approaches to managing content from creation through retirement. Organizations that treat content lifecycle management as an afterthought inevitably encounter quality issues in production.
Key Lifecycle Stages:
- Creation and Ingestion:
- Establish clear content creation standards and templates
- Implement automated ingestion pipelines for diverse data sources
- Databricks recommends ingesting data in a scalable and incremental manner, using various methods including fully managed connectors for SaaS applications and API integrations.
- Preprocessing and Validation:
- Core preprocessing steps include parsing to extract relevant information, enrichment with additional metadata and noise removal, metadata extraction for efficient retrieval, deduplication to eliminate duplicate documents, and filtering to remove irrelevant content.
- Implement quality gates to catch issues before content enters production
- Update and Versioning:
- Version control is critical in RAG systems to manage changes to data sources and model configurations, especially in industries requiring strict audit trails. This supports data integrity and compliance in sectors like finance and legal.
- Maintain clear records of content changes for compliance and debugging
- Monitoring and Optimization:
- RAG system integration with feedback loops adapts over time, learning from user interactions to enhance response quality and accuracy. This continuous learning approach is key to meeting evolving business needs.
- Track content usage patterns to identify high-value and low-performing content
Chunking Strategies: The Art and Science of Text Segmentation
Chunking decisions profoundly impact RAG system performance. Poor chunking leads to context loss, irrelevant retrieval, and degraded user experience.
Understanding Chunking’s Impact
An effective chunking strategy is vital for any RAG system, as it directly impacts how documents are segmented and retrieved. The key takeaways: there’s no universal strategy, balance size and semantics, preserve context through breaking text at natural boundaries, and iterate continuously based on real-world retrieval performance.
The size of the chunked data makes a huge difference in what information comes up in a search. Include too much in a chunk and the vector loses the ability to be specific to anything it discusses. Include too little and you lose the context of the data.
Major Chunking Approaches
- Fixed-Size Chunking
- Divides text into chunks of predefined length based on tokens or characters. Best for simple documents, FAQs, or when processing speed is a priority. Advantages include simplicity and uniformity, but can cause context loss by splitting sentences or ideas.
- Typical range: 200–500 words per chunk
- Includes optional chunk overlap to preserve context retention.
- Recursive Chunking
- Iterates through default separators until one produces the preferred chunk size, working well for documents with clear hierarchical structure.
- Adapts to document structure more intelligently than fixed-size approaches.
- Semantic Chunking
- Groups text based on meaning rather than word count using AI-driven techniques like topic modeling or word embeddings. Keeps contextually related sentences together, improving retrieval accuracy. Ideal for complex topics where cutting off mid-thought could lead to misinterpretation.
- Computationally intensive but delivers superior relevance for complex domains.
- Sliding Window Chunking
- Uses an overlapping approach where each chunk retains part of the previous one, preventing information loss at chunk boundaries and improving context continuity.
- Trade-off: increased storage requirements and potential redundancy.
- Document-Specific Chunking
- Document layout analysis libraries combine optical character recognition with deep learning models to extract both structure and text, identifying headers, footers, titles, section headings, tables, and figures.
- Essential for structured documents like contracts, technical specifications, and reports.
Advanced Chunking Techniques
Hierarchical chunking summarizes entire documents or large sections and attaches summaries to individual chunks as metadata, allowing retrieval systems to operate at multiple context levels. This provides additional layers of information but requires managing increased metadata complexity.
NVIDIA research tested three primary chunking approaches: token-based chunking with sizes of 128, 256, 512, 1,024, and 2,048 tokens with 15% overlap between chunks, finding that 15% overlap performed best on FinanceBench with 1,024 token chunks, aligning with 10-20% overlap commonly seen in industry practices.
Best Practices for Chunking
Key principles include: balance size and semantics by keeping chunks large enough for meaningful context but small enough for computational efficiency; preserve context by breaking text at natural boundaries; and consider adding contextual metadata for better retrieval.
Smart chunking strategies allow separation of text on semantically meaningful boundaries to avoid interrupting information flow or mixing content. Unstructured streamlines chunking experimentation by allowing parameter tweaking, no matter the document type.
Metadata Design: The Secret Weapon of Enterprise RAG
Metadata transforms raw content into intelligently retrievable knowledge assets. Well-designed metadata enables precise filtering, relevance ranking, and context preservation.
Essential Metadata Categories
- Source Metadata
- Document title, author, creation date, last modified date
- Source system or repository
- Version information and change history
- Content Metadata
- Attach additional information or metadata to each chunk including document type, section identifier, and page number. This helps track chunks and provides valuable context during retrieval and generation, allowing for filtering or prioritizing chunks during retrieval.
- Topic categories, keywords, and tags
- Language and localization information
- Content type (policy, procedure, reference, etc.)
- Access Control Metadata
- Security classifications
- Department or team ownership
- User role requirements for access
- Quality Metadata
- Content approval status
- Review dates and cycles
- Accuracy ratings and confidence scores
Metadata Implementation Strategy
Create metadata in a structured format like JSON for consistency. Ensure metadata is standardized and updated when source documents change, while carefully excluding sensitive information to maintain privacy.
Consistency in data schema is crucial. If tagging customer support articles, use the same labels and categories across the board. Inconsistent schema means the retrieval model won’t know where to look, slowing it down and introducing retrieval errors.
De-duplication: Eliminating Content Pollution
Duplicate content represents one of the most insidious quality problems in RAG systems. Duplicates skew retrieval results, waste computational resources, and can introduce contradictory information.
Why De-duplication Matters
Duplicate content within training data often includes inconsistencies that can severely compromise model performance. When contradictory information appears across different instances of duplicate content, it poses significant challenges for reliability and accuracy. Duplicate records from multiple sources further complicate reconciliation.
When faced with repeated contradictory data, the model may struggle to form clear understanding of correct information, resulting in a learning process that might reinforce incorrect responses, diminishing the model’s ability to respond accurately and consistently in practical applications.
De-duplication Strategies
- Source-Level De-duplication
- Ensure there are no duplicates in source data before generating embeddings. Depending on data type and context, employ specific de-duplication methods. For text data, methods include case normalization, stemming, tokenization, and removal of punctuation and special characters.
- Vector Similarity Thresholds
- Precise duplicate vectors are rare in word embeddings, so it’s more practical to consider vectors as duplicates if their cosine similarity exceeds a certain threshold. If two or more vectors exceed this threshold, retain one and remove the others.
- Advanced De-duplication Techniques
- Techniques like record linkage, fuzzy matching, and hash-based deduplication can identify and eliminate duplicate records, ensuring a unique and consistent dataset.
- Remove duplicate data entries as much as possible to streamline results and improve retrieval precision.
Handling Near-Duplicates
Duplicate content can originate from human error during data entry, system glitches creating redundant records, and integration of data from multiple sources where the same information may be stored in slightly different forms. Even slight variations in formatting, spelling, or wording can result in duplicates difficult to detect.
Organizations must implement sophisticated matching algorithms that can identify semantic duplicates even when surface-level differences exist.
6. Enterprise RAG Reference Architecture: From Prototype to Production
Below is the sample representation of of the Enterprise RAG reference architecture that can be tweaked across every unique enterprise situation and environment:
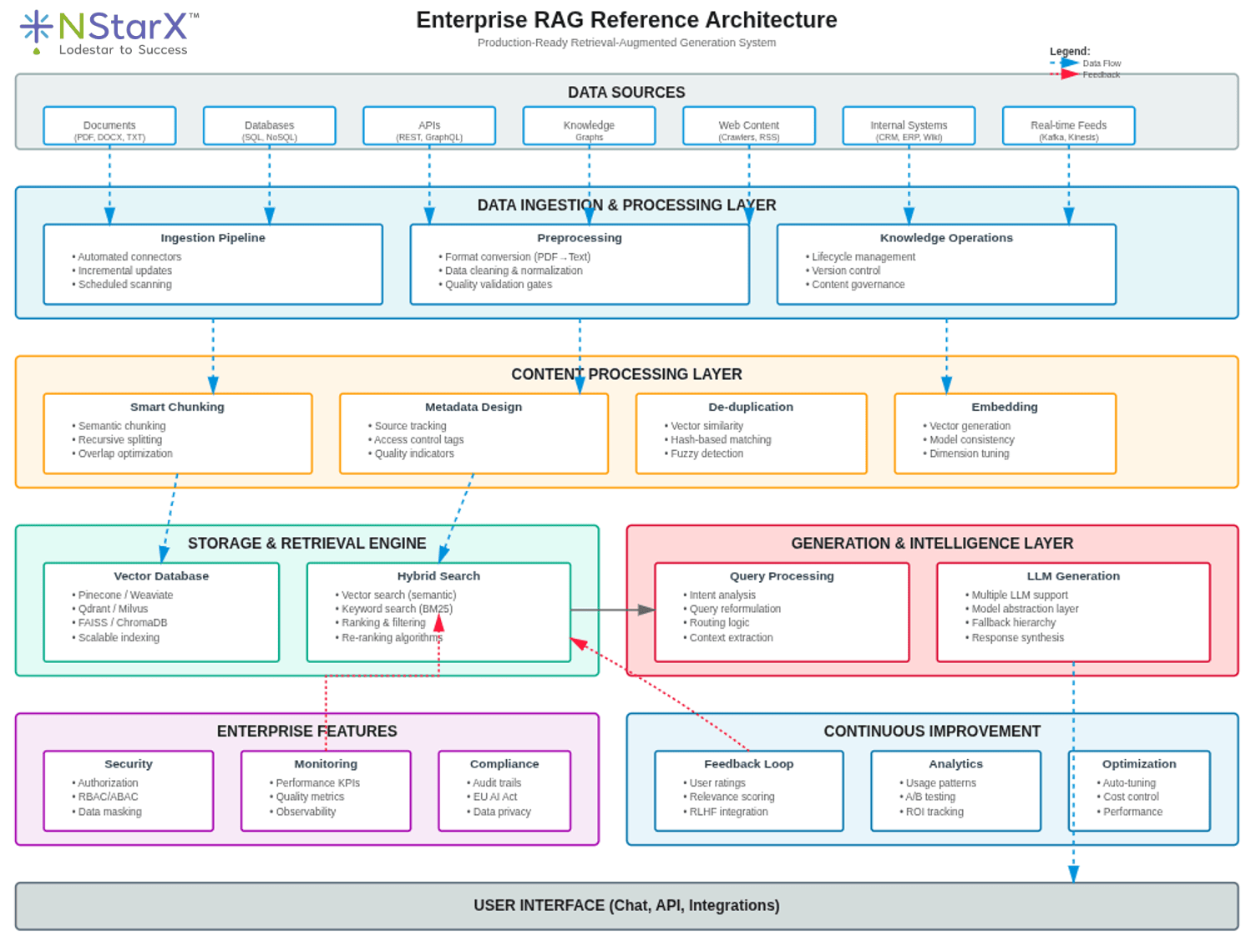
Figure 1: Enterprise RAG Reference Architecture
Core Components of Production RAG Systems
A production-ready enterprise RAG architecture requires careful orchestration of multiple components, each playing a critical role in delivering accurate, secure, and scalable AI-driven responses.
Foundational Architecture
In its simplest form, RAG architecture comprises two functional blocks: one for information retrieval and one for response generation. The system first retrieves relevant information from a knowledge base, providing crucial context to the LLM, which then uses that information to generate a response.
Data Ingestion and Indexing Layer
The initial stage is crucial for preparing data for the RAG system. Data ingestion begins by ingesting documents and data from various sources such as files, databases, or APIs. Data preprocessing then cleans and transforms data to make it suitable for augmentation, including converting PDFs to text, normalizing data, and expanding abbreviations. Chunking divides documents into smaller, manageable pieces to facilitate efficient indexing and retrieval.
Retrieval Engine
The Retriever component uses a hybrid search approach to find the most relevant data chunks from the indexed database. It combines vector search to find documents with similar meaning and keyword search for exact matches. Results are then combined, ranked, filtered, and passed to the generation stage.
Vendors like Pinecone, Weaviate, Zilliz, and Qdrant have made vector search scalable and enterprise-ready, enabling fast retrieval of large, complex datasets for integration with LLMs. These complementary technologies reduce latency, improve relevance, and make RAG architectures deployable at scale.
Generation Layer
The Generator is comprised primarily of the LLM that takes the user’s original query and retrieved information to produce a coherent and contextually appropriate answer.
Operational Flow: From Query to Response
The operational flow begins when a user enters a query into the system. The query is converted into a vector representation using the same embedding model used during indexing. The retriever then uses hybrid search to find relevant data chunks, which are combined, ranked, and filtered. Finally, the generator produces a coherent response based on the query and retrieved information.
Advanced Enterprise Patterns
Multi-Agent RAG Architecture
Successful enterprise RAG systems begin with sophisticated query analysis and routing layers. Instead of sending every query directly to vector search, they implement intelligence gateways that analyze user intent, determine optimal retrieval strategies, and route requests to appropriate knowledge domains.
Security and Authorization Layer
Successful enterprise RAG systems build authorization and compliance frameworks directly into their retrieval architecture, especially critical as enterprises face increasing regulatory pressure from frameworks like the EU AI Act. Fine-grained access control integrates with enterprise identity systems while maintaining performance requirements for real-time retrieval.
Continuous Learning System
Enterprise RAG systems need built-in feedback loops, performance monitoring, and automated optimization capabilities. The operational framework includes automated ingestion with scheduled processes that scan enterprise systems for new content, intelligent chunking with dynamic text segmentation, and relevance scoring using machine learning models that track which knowledge chunks provide the most valuable responses.
Model Abstraction and Resilience
Successful enterprise RAG systems implement model abstraction layers supporting multiple LLMs simultaneously, enabling A/B testing, graceful degradation during outages, and cost optimization through intelligent model routing. Technical implementation includes a Model Router for intelligent routing based on query complexity, a Fallback Hierarchy from primary to secondary models to simple template responses, and Performance Monitoring for real-time tracking of model performance, cost, and availability.
Production Deployment Considerations
A reference architecture for production RAG includes using message queues like Kafka or Kinesis to ingest changes, a consumer that updates the vector index, and systems for time awareness in prompts so models prioritize recent information.
Best practices for 2025 include modular design for flexibility and scalability allowing component swapping, robust data quality assurance ensuring recency and accuracy, and comprehensive monitoring and optimization tracking system health.
Evaluation and Monitoring
Implementing production-ready RAG systems demands expertise in vector databases, retrieval optimization, and real-time monitoring capabilities. Organizations should monitor key performance indicators such as response time, accuracy, and system load, using observability solutions for continuous system health tracking.
7. The Future of RAG: Evolution and Enterprise Modernization
Emerging Trends Reshaping RAG Architecture
The RAG landscape is evolving rapidly, with several transformative trends emerging that will reshape how enterprises deploy and benefit from these systems.
Agentic RAG: The Next Evolution
Traditional RAG has limits—it’s great at grabbing data from one source but struggles with tricky, multi-step questions. Agentic RAG steps in like a detective, piecing together clues from multiple places and double-checking its work. By 2028, Gartner predicts that 15% of daily work decisions will be made by agentic AI, up from zero in 2024.
Agentic RAG systems represent a significant evolution, combining retrieval, generation, and agentic intelligence. These systems extend traditional RAG capabilities by integrating decision-making, query reformulation, and adaptive workflows, addressing complex, dynamic, and knowledge-intensive challenges.
Multimodal RAG: Beyond Text
RAG will evolve beyond text, integrating images, videos, and audio while delivering highly personalized content through advanced fine-tuning. Multimodal RAG will include various data formats into AI-powered systems, enabling AI assistants, chatbots, and content production models to offer more comprehensive responses.
A 2024 case study showed 40% faster diagnostics in healthcare using multimodal systems, highlighting their transformative potential. These systems integrate text, image, and audio data, achieving 30% higher accuracy in multimodal tasks like autonomous driving.
By mid-2025, multimodal RAG has failed to gain momentum due to the immaturity of supporting infrastructure, particularly around storage inflation for multimodal data and slow infrastructure limiting innovation.
Real-Time and Hybrid Search
AI systems will dynamically retrieve the most recent information by integrating real data feeds into RAG models. Real-time RAG will guarantee that generative AI solutions deliver precise and contextually appropriate material by establishing connections with external knowledge bases, websites, and structured data sources.
Future RAG models will integrate with auto-updating knowledge graphs instead of relying on static databases. This will allow legal AI to track real-time rulings, financial AI to adjust risk models based on market shifts, and customer support AI to instantly reflect product updates.
Self-Improving RAG Systems
One transformative trend is the rise of self-improving RAG systems leveraging reinforcement learning to refine retrieval strategies based on user interactions. Adaptive intelligence will drive development of self-improving RAG systems that refine retrieval and generation strategies based on real-time user interactions and feedback.
AI systems are developing the ability to refine search queries autonomously. Self-querying RAG models will automatically evaluate and reword search queries to obtain more pertinent information, iteratively improving query precision and reducing noise.
On-Device and Edge RAG
On-device and efficient retrieval will allow AI models to process data locally for better privacy and reduced latency, while sparse retrieval techniques enhance speed and efficiency.
Companies increasingly want RAG functionality that works offline or on private infrastructure. More RAG models are being optimized for edge computing—critical for sectors like defense or healthcare where data privacy is paramount.
Industry-Specific RAG Evolution
From legal and healthcare to finance and e-commerce, RAG will power precise decision-making, automation, and improved AI-driven insights across industries.
Banks and investment companies have adopted RAG-enhanced AI analysts that retrieve data from live market reports, earnings transcripts, and macroeconomic trends.
A 2025 Forbes report revealed that a leading online retailer saw a 25% increase in customer engagement after implementing RAG-driven search and product recommendations.
Preparing for Future RAG Capabilities
Strategic Considerations for Enterprises
- Modular Architecture: A modular architecture lets you swap out individual components such as different LLMs, embedding models, or vector databases as new and improved technologies emerge. This design provides flexibility needed for future-proofing systems, adapting to changing regulatory requirements, and meeting scaling demands.
- Federated Learning: Federated learning will play a pivotal role, enabling decentralized RAG systems to learn from diverse datasets without compromising privacy. This approach could revolutionize industries like finance where data sensitivity is paramount.
- Sustainability Focus: Sustainability will become a priority, with advancements in energy-efficient algorithms and hardware optimizations reducing the environmental impact of RAG systems.
- Collaborative AI: RAG’s trajectory will emphasize collaborative AI, augmenting human expertise rather than replacing it, enabling humans to work alongside AI systems effectively.
Investment Priorities for 2025 and Beyond
Organizations should focus on:
- Building flexible, modular RAG architectures that can incorporate emerging technologies
- Establishing robust data governance and quality frameworks
- Investing in continuous learning and feedback mechanisms
- Preparing infrastructure for multimodal capabilities
- Implementing comprehensive security and compliance frameworks
- Developing internal expertise in advanced RAG patterns
As we move through 2025, RAG continues to evolve, offering unprecedented capabilities that bridge the gap between static AI models and dynamic, real-world information. Organizations that successfully implement RAG will gain significant competitive advantages through improved decision-making, enhanced customer experiences, and more efficient knowledge management.
8. Conclusion: Building Sustainable Enterprise RAG Systems
The journey from RAG prototype to production-ready enterprise system is complex, demanding meticulous attention to content quality, strategic architecture decisions, and continuous optimization. Yet the rewards justify the investment: organizations implementing robust RAG systems report dramatic improvements in productivity, decision-making accuracy, and customer satisfaction while dramatically reducing the costs and risks associated with AI hallucinations.
Key Takeaways
- Market Momentum: With the RAG market projected to grow from $1.2 billion in 2024 to $11+ billion by 2030 at a CAGR approaching 50%, enterprises that master RAG implementation gain significant competitive advantages.
- Quality as Foundation: The quality of RAG outputs directly reflects the quality of underlying content. Organizations must invest in comprehensive Knowledge Ops practices including content lifecycle management, strategic chunking, intelligent metadata design, and rigorous de-duplication.
- Hallucination Risk: With average costs of $2.4 million per major hallucination incident, the financial imperative for robust RAG systems is clear. Properly implemented RAG can reduce hallucinations by 70–90%.
- Technical Excellence: Success requires mastery of multiple technical dimensions: chunking strategies that preserve context while enabling efficient retrieval, metadata architectures that enable precise filtering and relevance ranking, and de-duplication processes that eliminate content pollution.
- Production Readiness: The gap between demo and production is vast. Only 28% of enterprise RAG implementations achieve sustained success, typically those that implement modular architectures, continuous learning systems, and comprehensive security frameworks.
- Future-Proofing: The RAG landscape is evolving toward agentic systems, multimodal capabilities, and real-time knowledge integration. Organizations should build flexible architectures that can incorporate these emerging capabilities.
The Path Forward
For NstarX engineers embarking on or optimizing RAG implementations:
- Start with Content: Audit and improve content quality before investing in sophisticated retrieval algorithms. Establish Knowledge Ops processes that ensure ongoing content quality.
- Experiment with Chunking: There is no universal chunking strategy. Systematically test different approaches with real queries and measure retrieval quality.
- Design for Scale: Plan for enterprise-scale from the beginning. Modular architectures, monitoring frameworks, and feedback loops aren’t optional for production systems.
- Embrace Knowledge Graphs: For complex domains with rich relationship structures, knowledge graphs provide capabilities that pure vector approaches cannot match.
- Monitor and Iterate: RAG system validation is only feasible during operation. Implement comprehensive monitoring and be prepared to continuously refine based on real-world performance.
The organizations that will thrive in the AI era are those that recognize RAG not as a one-time implementation project but as a foundational capability requiring ongoing investment in content quality, technical excellence, and operational discipline. By following the principles and practices outlined in this guide, enterprises can build RAG systems that deliver sustained value while mitigating the risks that have caused so many implementations to fail.
The future belongs to organizations that master the interplay between content operations and AI systems—those that understand that in RAG, content quality isn’t just important, it’s everything.
9. References and Citations
- Grand View Research. “Retrieval Augmented Generation Market Size Report, 2030.” https://www.grandviewresearch.com/industry-analysis/retrieval-augmented-generation-rag-market-report
- Market.us. “Retrieval Augmented Generation Market Size | CAGR of 49%.” April 14, 2025. https://market.us/report/retrieval-augmented-generation-market/
- Mordor Intelligence. “Retrieval Augmented Generation Market Size, Share & 2030 Growth Trends Report.” August 29, 2025. https://www.mordorintelligence.com/industry-reports/retrieval-augmented-generation-market
- UnivDatos. “Retrieval Augmented Generation Market Report, Trends & Forecast.” https://univdatos.com/reports/retrieval-augmented-generation-market
- Roots Analysis. “Retrieval-Augmented Generation Market Size & Trends 2035.” July 31, 2025. https://www.rootsanalysis.com/retrieval-augmented-generation-rag-market
- MarketsandMarkets. “Retrieval-augmented Generation (RAG) Market worth $9.86 billion by 2030.” October 10, 2025. https://www.marketsandmarkets.com/Market-Reports/retrieval-augmented-generation-rag-market-135976317.html
- Precedence Research. “Retrieval Augmented Generation Market Size to Hit USD 67.42 Billion by 2034.” April 21, 2025. https://www.precedenceresearch.com/retrieval-augmented-generation-market
- Intelliarts. “Best Practices for Enterprise RAG System Implementation.” November 18, 2024. https://intelliarts.com/blog/enterprise-rag-system-best-practices/
- Signity Solutions. “8 High-Impact Use Cases of RAG in Enterprises.” April 30, 2025. https://www.signitysolutions.com/blog/use-cases-of-rag-in-enterprises
- Evidently AI. “10 RAG examples and use cases from real companies.” https://www.evidentlyai.com/blog/rag-examples
- ProjectPro. “Top 7 RAG Use Cases and Applications to Explore in 2025.” https://www.projectpro.io/article/rag-use-cases-and-applications/1059
- National Law Review. “Understanding the Risks AI Hallucinations Create for Businesses.” https://natlawreview.com/article/ai-hallucinations-are-creating-real-world-risks-businesses
- BayTech Consulting. “Hidden Dangers of AI Hallucinations in Financial Services.” https://www.baytechconsulting.com/blog/hidden-dangers-of-ai-hallucinations-in-financial-services
- Deep Learning Dispatch. “The Cost of AI Hallucinations.” September 21, 2025. https://deeplearningdispatch.substack.com/p/the-cost-of-ai-hallucinations
- HackerNoon. “Gen AI Hallucinations: The Good, the Bad, and the Costly.” March 14, 2024. https://hackernoon.com/gen-ai-hallucinations-the-good-the-bad-and-the-costly
- SearchUnify. “Are LLMs Lying to You? Exposing The Hidden Cost of AI Hallucinations.” January 31, 2024. https://www.searchunify.com/sudo-technical-blogs/are-llms-lying-to-you-exposing-the-hidden-cost-of-ai-hallucinations/
- LayerX Security. “AI Hallucinations: Risks and Real-World Consequences.” October 21, 2025. https://layerxsecurity.com/generative-ai/hallucinations/
- Senior Executive. “From Misinformation to Missteps: Hidden Consequences of AI Hallucinations.” June 19, 2025. https://seniorexecutive.com/ai-model-hallucinations-risks/
- Superprompt.com. “Top 11 AI Hallucination Detection Tools for Enterprise.” August 18, 2025. https://www.superprompt.com/blog/best-ai-hallucination-detection-tools-enterprise-2025
- Shieldbase.ai. “AI Hallucinations That Cost Millions—And Who Pays for Them.” https://shieldbase.ai/blog/ai-hallucinations-that-cost-millions-and-who-pays-for-them
- Mastering LLM. “11 Chunking Strategies for RAG — Simplified & Visualized.” Medium, November 2, 2024. https://masteringllm.medium.com/11-chunking-strategies-for-rag-simplified-visualized-df0dbec8e373
- Databricks. “The Ultimate Guide to Chunking Strategies for RAG.” April 18, 2025. https://community.databricks.com/t5/technical-blog/the-ultimate-guide-to-chunking-strategies-for-rag-applications/ba-p/113089
- Stack Overflow. “Breaking up is hard to do: Chunking in RAG applications.” December 27, 2024. https://stackoverflow.blog/2024/12/27/breaking-up-is-hard-to-do-chunking-in-rag-applications/
- IBM. “Chunking strategies for RAG tutorial using Granite.” October 20, 2025. https://www.ibm.com/think/tutorials/chunking-strategies-for-rag-with-langchain-watsonx-ai
- Multimodal.dev. “How to Chunk Documents for RAG.” September 26, 2024. https://www.multimodal.dev/post/how-to-chunk-documents-for-rag
- NVIDIA Technical Blog. “Finding the Best Chunking Strategy for Accurate AI Responses.” June 26, 2025. https://developer.nvidia.com/blog/finding-the-best-chunking-strategy-for-accurate-ai-responses/
- Lettria. “5 RAG Chunking Strategies for Better Retrieval-Augmented Generation.” October 2025. https://www.lettria.com/blogpost/5-rag-chunking-strategies-for-better-retrieval-augmented-generation
- Unstructured. “Chunking for RAG: best practices.” https://unstructured.io/blog/chunking-for-rag-best-practices
- Microsoft Azure. “Develop a RAG Solution – Chunking Phase.” https://learn.microsoft.com/en-us/azure/architecture/ai-ml/guide/rag/rag-chunking-phase
- DataCamp. “Using a Knowledge Graph to Implement a RAG Application.” June 11, 2024. https://www.datacamp.com/tutorial/knowledge-graph-rag
- Medium (Knowledge Graph RAG). “The RAG Stack: Featuring Knowledge Graphs.” May 22, 2025. https://medium.com/enterprise-rag/understanding-the-knowledge-graph-rag-opportunity-694b61261a9c
- RAG About It. “How to Build Production-Ready Knowledge Graphs for RAG: The Complete Enterprise Implementation Guide.” October 2025. https://ragaboutit.com/how-to-build-production-ready-knowledge-graphs-for-rag-the-complete-enterprise-implementation-guide/
- Writer. “Starter guide: Graph-based RAG for enterprise with WRITER Knowledge Graph.” August 5, 2025. https://writer.com/guides/graph-based-rag-starter-guide/
- Databricks. “Building, Improving, and Deploying Knowledge Graph RAG Systems on Databricks.” https://www.databricks.com/blog/building-improving-and-deploying-knowledge-graph-rag-systems-databricks
- RAG About It. “How to Build Hybrid RAG Systems with Vector and Knowledge Graph Integration.” October 2025. https://ragaboutit.com/how-to-build-hybrid-rag-systems-with-vector-and-knowledge-graph-integration-the-complete-enterprise-guide/
- SingleStore. “Enhance Your RAG Applications with Knowledge Graph RAG.” March 24, 2025. https://www.singlestore.com/blog/enhance-your-rag-applications-with-knowledge-graph-rag/
- Medium (Data Science). “How to Implement Graph RAG Using Knowledge Graphs and Vector Databases.” September 6, 2024. https://medium.com/data-science/how-to-implement-graph-rag-using-knowledge-graphs-and-vector-databases-60bb69a22759
- Progress MarkLogic. “Semantic RAG Series Part 1: Enhancing GenAI with Multi-Model Data and Knowledge Graphs.” https://www.progress.com/marklogic/solutions/generative-ai
- Medium (Gen. Devin DL). “Considerations for Data Processing in RAG Applications.” October 13, 2023. https://medium.com/@tubelwj/considerations-for-data-processing-in-rag-applications-9d06b895574e
- Data Science Central. “Best practices for structuring large datasets in Retrieval-Augmented Generation (RAG).” November 30, 2024. https://www.datasciencecentral.com/best-practices-for-structuring-large-datasets-in-retrieval-augmented-generation-rag/
- RAG About It. “Scaling RAG for Big Data: Techniques and Strategies for Handling Large Datasets.” April 12, 2024. https://ragaboutit.com/scaling-rag-for-big-data-techniques-and-strategies-for-handling-large-datasets/
- DEV Community. “Mastering Retrieval-Augmented Generation: Best Practices for Building Robust RAG Systems.” September 19, 2025. https://dev.to/satyam_chourasiya_99ea2e4/mastering-retrieval-augmented-generation-best-practices-for-building-robust-rag-systems-p9a
- Shelf. “10 Systems That Duplicate Content and Cause Errors in RAG Systems.” August 4, 2025. https://shelf.io/blog/10-ways-duplicate-content-can-cause-errors-in-rag-systems/
- Databricks AWS. “Build an unstructured data pipeline for RAG.” https://docs.databricks.com/aws/en/generative-ai/tutorials/ai-cookbook/quality-data-pipeline-rag
- DEV Community (Kuldeep Paul). “Synthetic Data for RAG: Safe Generation, Deduplication, and Drift-Aware Curation in 2025.” October 2025. https://dev.to/kuldeep_paul/synthetic-data-for-rag-safe-generation-deduplication-and-drift-aware-curation-in-2025-3298
- Enterprise Knowledge. “Data Governance for Retrieval-Augmented Generation (RAG).” February 20, 2025. https://enterprise-knowledge.com/data-governance-for-retrieval-augmented-generation-rag/
- Orq.ai. “RAG Architecture Explained: A Comprehensive Guide [2025].” https://orq.ai/blog/rag-architecture
- Medium (Meeran Malik). “Building Production-Ready RAG Systems: Best Practices and Latest Tools.” May 1, 2025. https://medium.com/@meeran03/building-production-ready-rag-systems-best-practices-and-latest-tools-581cae9518e7
- Latenode. “Best RAG Frameworks 2025: Complete Enterprise and Open Source Comparison.” https://latenode.com/blog/best-rag-frameworks-2025-complete-enterprise-and-open-source-comparison
- Squirro. “Insights into RAG Architecture for the Enterprise.” August 25, 2025. https://squirro.com/squirro-blog/rag-architecture
- Azumo. “Enterprise RAG: How to Build a RAG System | Guide.” October 2025. https://azumo.com/artificial-intelligence/ai-insights/build-enterprise-rag-system
- Medium (Kuldeep Paul). “Building Reliable RAG Applications in 2025.” September 21, 2025. https://medium.com/@kuldeep.paul08/building-reliable-rag-applications-in-2025-3891d1b1da1f
- Galileo. “Explaining RAG Architecture: A Deep Dive into Components.” March 11, 2025. https://galileo.ai/blog/rag-architecture
- Glean. “What are RAG models? A guide to enterprise AI in 2025.” https://www.glean.com/blog/rag-models-enterprise-ai
- Medium (Devendra Parihar). “The Evolution of RAG: How Retrieval-Augmented Generation is Transforming Enterprise AI in 2025.” September 18, 2025. https://dev523.medium.com/the-evolution-of-rag-how-retrieval-augmented-generation-is-transforming-enterprise-ai-in-2025-a0265bc1c297
- Signity Solutions. “Trends in Active Retrieval Augmented Generation: 2025 and Beyond.” July 14, 2025. https://www.signitysolutions.com/blog/trends-in-active-retrieval-augmented-generation
- RAGFlow. “RAG at the Crossroads – Mid-2025 Reflections on AI’s Incremental Evolution.” July 2, 2025. https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- Chitika. “What Are the Future Trends in RAG for 2025 and Beyond?” February 4, 2025. https://www.chitika.com/future-trends-in-retrieval-augmented-generation-what-to-expect-in-2025-and-beyond/
- Chitika. “Retrieval-Augmented Generation (RAG): 2025 Definitive Guide.” January 25, 2025. https://www.chitika.com/retrieval-augmented-generation-rag-the-definitive-guide-2025/
- Dataworkz. “Future Trends in Retrieval Augmented Generation & AI Impacts.” June 5, 2025. https://www.dataworkz.com/blog/future-trends-in-retrieval-augmented-generation-and-its-impact-on-ai/
- Medium (Aneesh TN). “Agentic RAG: The Future of AI Agents in 2025 and Beyond.” February 25, 2025. https://medium.com/@aneeshtn/agentic-rag-the-future-of-ai-agents-in-2025-and-beyond-1891b7c00aaa
- Aya Data. “The State of Retrieval-Augmented Generation (RAG) in 2025 and Beyond.” April 8, 2025. https://www.ayadata.ai/the-state-of-retrieval-augmented-generation-rag-in-2025-and-beyond/
- arXiv. “A Systematic Review of Key Retrieval-Augmented Generation (RAG) Systems: Progress, Gaps, and Future Directions.” July 25, 2025. https://arxiv.org/html/2507.18910v1
- IJCTT. “Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.” September 8, 2025. https://arxiv.org/html/2501.09136v1
- arXiv. “Seven Failure Points When Engineering a Retrieval Augmented Generation System.” October 2025. https://arxiv.org/html/2401.05856v1
- RAG About It. “Why 72% of Enterprise RAG Implementations Fail in the First Year—and How to Avoid the Same Fate.” July 13, 2025. https://ragaboutit.com/why-72-of-enterprise-rag-implementations-fail-in-the-first-year-and-how-to-avoid-the-same-fate/
- arXiv. “RAG Does Not Work for Enterprises.” 2024. https://arxiv.org/pdf/2406.04369
- Analytics Vidhya. “Enterprise RAG Failures: The 5-Part Framework to Avoid the 80%.” July 3, 2025. https://www.analyticsvidhya.com/blog/2025/07/silent-killers-of-production-rag/
- Jon Turow. “From RAG Invention to Enterprise Impact.” March 27, 2025. https://jonturow.substack.com/p/from-rag-invention-to-enterprise
- Coralogix. “RAG in Production: Deployment Strategies and Practical Considerations.” June 19, 2025. https://coralogix.com/ai-blog/rag-in-production-deployment-strategies-and-practical-considerations/
- TechTarget. “RAG best practices for enterprise AI teams.” https://www.techtarget.com/searchenterpriseai/tip/RAG-best-practices-for-enterprise-AI-teams
- Vectara. “Enterprise RAG Predictions for 2025.” https://www.vectara.com/blog/top-enterprise-rag-predictions
- Tonic.ai. “Top 5 Trends in Enterprise RAG.” 2024. https://www.tonic.ai/guides/enterprise-rag