Part 1: Scala with Spark Legacy Code Conversion
Part 2: Running within a Kubeflow Pipeline (KFP)
Part 3: Platform Engineering for Scala with Spark
Scala with Spark Legacy Code Conversion
Written by: Alessandro, Data Engineer NStarX
Contributor: Yassir, Data Scientist NStarX
Preface
Many companies today are looking to migrate away from managed cloud platforms like Databricks, in favour of more customizable, cost effective options like Kubeflow. One of the main challenges that arise from a move of this kind, is how to deal with legacy code that has been written within Databricks. Do companies incur the time and cost burden of completely rewriting their legacy code to fit into the new platform? Do they find ways of updating legacy code? These are some of the most common questions companies will face when taking this decision.
In this three part series, we will be answering these questions by exploring the challenges and solutions associated with converting legacy code written in Scala, leveraging Spark, from Databricks to Kubeflow. This series will include converting legacy code to run outside of Databricks, running the code within a Kubeflow pipeline and the necessary platform engineering required to provide a stable and scalable environment. This first part will outline the best practices for the code itself and how to ensure existing ML pipelines will not be affected by changes in the feature engineering process. The second part will outline how to package these scripts into a Kubeflow pipeline. The third will describe the platform engineering required for a self managed environment like Kubeflow.
Introduction
Many companies have decided to move from a managed cloud computing platform like Databricks, to an open source one like Kubeflow. The benefit of a low cost, highly customizable platform like Kubeflow proves to be a greater benefit than the user support a platform like Databricks provides.
Companies tend to initially prefer Databricks, because it is an extremely user-friendly platform, designed to give data engineers and data scientists the ability to create and execute machine learning pipelines, without the need for optimization. The platform allows workflows to run, seldom without failures caused by inefficiency. While this might be a great feature for initially creating workflows, the lack of optimization can lead to code which is unnecessarily compute intensive; thus exacerbating compute costs. Unless a user is extremely familiar with Scala and Spark outside of Databricks, optimization can be a daunting task, as scripts will run without failure, regardless of inefficiencies.
Databricks Architecture
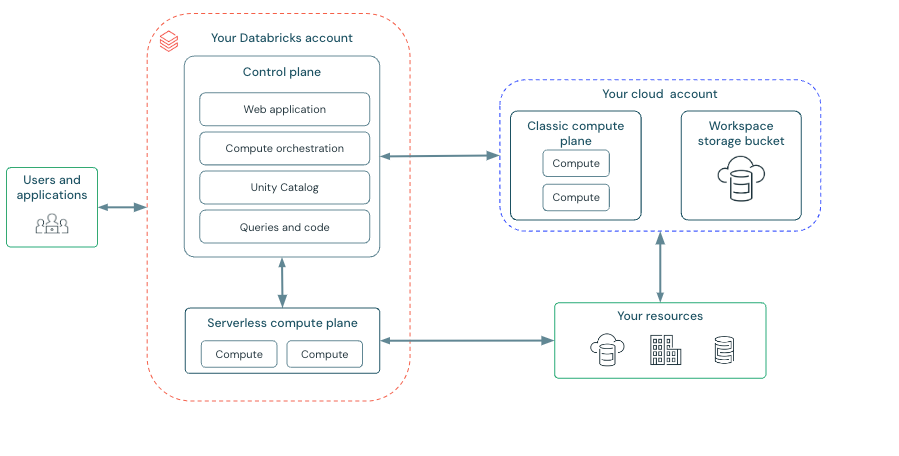
Source: https://docs.databricks.com/aws/en/getting-started/overview
In contrast, Kubeflow is not as user friendly, but demands efficiency. Where Databricks is a turn-key, fuel injected, worry free vessel; Kubeflow is an analog, carborated, complex environment, demanding users be well versed in the concepts they are working with. That being said, Kubeflow requires code optimization, thus forcing cost efficiency that would otherwise be lost in Databricks. While kubeflow might not be turn-key, over the lifecycle of a compute intensive pipeline, it will force engineers to create code which is more efficient than that created in Databricks, saving both time and money in the long run.
Kubeflow Components & ML Lifecycle

Source: https://www.kubeflow.org/docs/started/architecture/
When companies take the decision to migrate from Databricks to Kubeflow, they are left with the challenge of how to handle their existing code base. They might be tempted to completely rewrite legacy code, but this comes at a high financial cost and time commitment. Furthermore, data engineers want to ensure that when deciding to convert or rewrite legacy code, existing engineered features are not altered, thus affecting the data science models.
Furthermore, conversion and optimization of existing legacy code, rather than a complete rewrite, can save both time and resources. Even with the leveraging of new AI coding assistants to convert Scala 2.XX to Scala 3.XX, or Scala to Python, feature outputs must be meticulously tested to ensure that production models are not compromised. The decision to update, rather than to completely rewrite, can oftentimes be up to five times faster in migrating a legacy code base to Kubeflow.
Real-World Example
One use case, which encompasses these challenges, was to convert existing legacy code, written in Databricks, to run within a kubeflow environment. The reason that this is a three part series is that there were three different vertices in which we had to tackle this problem. Initially we had to take these existing Scala scripts, which leveraged Spark, and convert them to run outside of Databricks. Databricks itself has a lot of features and functions which are Databricks specific, holding no relevance to Scala or Spark. Additionally, before we would be able to run this code within a pipeline, we would have to convert and optimize it to run outside of Databricks itself, one script at a time. Inefficiency in this case can be associated with an overutilization of Spark executors, causing them to fail.
Challenges of Real World Example: Scala with Spark for Feature Engineering
Databricks has many of its own features. For example dbutils.widgets.getAll() does not have a direct replacement outside of Databricks. Depending how variables are declared, re-use of previously defined variable names (something possible in Databricks) is not native to Scala. Additionally, optimization is a necessity for legacy code to run efficiently outside of Databricks. The end goal of Databricks is to sell compute, so even when executors are being throttled, the jobs will not fail, but will reach bottlenecks causing an excess in execution time and computational costs. Complex feature engineering will have a tough time running outside of Databricks if some time has not been dedicated to optimization.
Furthermore, Spark sessions have to be specifically defined with node tagging, executor scaling, size, number of cores and any other intricacies with which a user wants to define their session. Environment restrictions, such as types of nodes used, must be taken into consideration when defining drivers and executors. A docker image containing all necessary dependencies must be properly defined.
Any existing movement of data across the wire within a script, such as across nodes, executors or storage systems, should be minimized. This is where a lot of latency can be created. Network bottlenecks from these sorts of operations will further add to executor failures from overutilization of resources.
Best Practices
Through our own personal experiences in this process, these are the best practices we have found to ensure that legacy code will run smoothly and reliably in Kubeflow.
Variables defined as dbutils (Databricks Wigets) can often be replaced as environment variables, e.x. sys.env.get. This sort of definition will be useful further down the line when integrating these scripts into a Kubeflow pipeline. Additionally, best practice for Scala is to ensure variable names are unique, especially when redefining an existing variable. While in Databricks, variable declaring operates in the way Python would, standard Scala does not have this sort of support, so be mindful when redefining variable names to avoid failures.
When it comes to transferring and transforming data, avoid operations across the wire as much as possible. These operations can include data writing, shuffle operations, transfers between nodes and transfers between executors. Primary concern when writing is to keep data all in a single region, meaning the region where data is read from, data should be written to. Spark in general engages in a lazy execution; therefore, bottlenecks may not be apparent as transformations will only take place when an operation is necessary, such as showing a table or writing the data back to a database.
Another key in optimization is repartitioning data prior to writing and dynamically determining the maximum size of each file partition being written, according to executor size and number of cores per executor. Writing to an external database is one of the most compute intensive operations within Spark, so to optimize a script, ensure data is only being written when absolutely necessary. Keep the number of files written down to a minimum as well. Many small files are going to take exponentially longer than a few large files, especially if repartitioning is happening at the time of writing. Once data is repartitioned, if a user wishes to write data into a sub-directory, ensure the data is partitioned by the same variable which was used at the time of repartitioning.
Unlike Databricks, to run Scala with distributed Spark in Kubeflow, a user must define the parameters of their Spark session. The primary consideration of a data engineer should be what this Spark session will be used for. As such, one of the biggest considerations should be the size of executors, number of executors required and number of cores per executor. When determining these metrics as well, a user must know which nodes are being used within the cluster and factor in the overhead of a node before determining the optimal size of executors, in order to optimize node usage and computation expense. Furthermore, if autoscaling is employed, it is worth noting that scaling down happens after 60 seconds of executor inactivity, but scaling up happens after only 1 second of task backloging. As such, Spark’s default setting can cause operations to scale up to maximum Spark resource restriction, even if the resources are not required to complete the operation. This is due to the fact that while executors are provisioning to complete backlogged tasks, there may not be nodes available for these executors to associate with because nodes typically take 2-3 minutes to initiate. As such, Spark will request more executors, as backlogged tasks status’ have remained stagnant, until all executors, up to a maximum number of specified executors, have been provisioned.
When it comes to the executors themselves, it is recommended to set the storage level to memory and disk, ex. **StorageLevel.**MEMORY_AND_DISK and avoid the default cache setting. When the memory of an executor is full, spark will split this memory into disk, thus avoiding unnecessary recomputation, leading to longer execution times and further compute expenses. Additionally, executors will not run into out of memory OOM issues, causing executor failure. These out of memory errors will be more prevalent outside of Databricks, but as such, are much easier to rectify.
All of these solutions are ones which do not affect data quality and output, but rather computational performance. This is key when optimizing, to ensure that existing models are not negatively affected by adverse changes in existing feature engineering scripts.
Conclusion
When moving from a managed cloud platform like Databricks, to a customizable one like Kubeflow, it is always better to update existing code, rather than take on the daunting task of rewriting an entire existing code base. Updating rather than rewriting can be up to five times faster for developers and save companies from unnecessary expenditure. In the end, part of the motivation to move to Kubeflow is the cost savings associated with such a platform. Updating legacy code can also save from potentially compromising existing production models, which would be an additional burden placed upon data scientists.
While code optimization might seem like a given in a turn-key platform like Databricks, developers oftentimes can confuse lack of code failure with optimal performance. Even when optimization is attempted, it is harder to determine the major benefits as failures are not as present. This leads developers, who might not be as familiar with Scala and/or Spark, outside of Databricks, to create code which is inefficient.
Be mindful of moving data across the wire. Keep this to a minimum. Understand writing operations are taxing and will cause bottlenecks if executed inefficiently. Make sure when converting to look for potential areas of optimization. For example, keep repartitions separate from write operations. Remember that executors are also used for caching data, thus overutilizing executors can lead to executor failures, increased execution time and increases in computational costs.
For companies considering a switch from Databricks to Kubeflow, be mindful that this is akin to switching from MacOS to Ubuntu built on Linux. While MacOS is very user friendly, it is also costly, immutable and can be difficult for users to move away from once locked in. On the other hand, Ubuntu might initially seem complex, but is much more cost efficient, customizable and flexible. Ubuntu users are never locked into a specific tool or vendor, allowing them to readily change their platform to suit their needs.
Databricks and Kubeflow are much the same. Companies who are deciding which platform they prefer must ask themselves, do they need a user friendly, supported platform that is immutable and comes at a high cost, or do they rather a cost efficient, flexible, highly customizable platform that will require a steeper learning curve. There is no correct answer which will suit all companies as this will depend on specific needs, but we hope the insights provided in this blog will help those who have been previously locked into Databricks, transition easily to Kubeflow.
Part 1: Scala with Spark Legacy Code Conversion
Part 2: Running within a Kubeflow Pipeline (KFP)
Part 3: Platform Engineering for Scala with Spark