Part 1: Scala with Spark Legacy Code Conversion
Part 2: Running within a Kubeflow Pipeline (KFP)
Part 3: Platform Engineering for Scala with Spark
Platform Engineering for Scala with Spark
Written by: Alessandro – Data Engineer NStarX
Contributor: Saishiva – Lead Technical Architect NStarX
Contributor: Yassir – Data Scientist NStarX
Preface
Many companies today are looking to move away from managed platforms like DataBricks, in favour of open source ones like Kubeflow, for their cost-effectiveness and customizability. In the first 2 parts of this 3 part series, we covered topics relating to this migration. In part 1, we explored the challenges we faced and solutions we came up with when handling a legacy code base. Specifically, we focused on how to deal with existing feature engineering scripts written in Scala which leverage Spark. In part 2, we delved deeper into the technical aspects of packaging these scripts into reliable, repeatable and scalable Kubeflow pipelines.
In the third and final part of our series, we will explore and expand on the platform specific challenges and solutions we came across, which made the execution of these scripts and pipelines possible. The platform engineering was an integral part of this journey. Our platform engineers created the environment in which we operated and in this paper, we will highlight the underlying infrastructure requirements they used to create a stable and scalable platform for our workloads.
Introduction
As highlighted in the previous 2 articles, when companies move from Databricks to Kubeflow, they do so so that they are no longer tied into a specific vendor, which in turn provides them with flexibility and customizability. Additionally, the move to open source can prove to be much more cost effective than operating within a managed solution like Databricks.
That being said, when shifting to an open source platform, the responsibility of managing the platform’s infrastructure falls onto the user. Where DataBricks is completely managed by a large external organization, KubeFlow requires the user to explicitly engineer the entire platform to ensure it is stable and scalable. A deep understanding of the requirements a developer needs to run their workflows is required for the platform engineer to ensure they are providing the optimal platform design, which can support the workloads without issue.
Migrating Scala with Spark workflows from Databricks to Kubeflow can create a few challenges ranging from configuring appropriate node groups and storage solutions, to optimizing Spark parameters for stable distributed executions and implementing effective monitoring solutions. By addressing these challenges, we were able to create a platform that matched the reliability and performance of Databricks while delivering significant cost savings and increased flexibility.
Real-World Example
As previously mentioned, in part 1 & 2 of this series, we highlighted the best practices for decoupling Scala scripts leveraging Spark from DataBricks and how to then package these scripts into KubeFlow pipelines. In this final part, we will cover how to configure the platform infrastructure to support these workflows in production.
In our use case, we had to create a KubeFlow platform which was able to run the existing Scala with Spark feature engineering jobs from Databricks, with the same resource restrictions, computational times and stability. These pipelines processed large batches of data periodically and required large amounts of computational resources, which could be scaled dynamically, based on demand. Furthermore, we had the additional goals of creating a platform which was cost-effective, observable and cloud agnostic.
Challenges of Real-World Example: Platform Engineering for Scala with Spark
Of all the challenges we faced in this use case, there are 6 specific ones we will highlight, as we believe these are the most relevant. The 5 main topics we will cover are integration with existing storage solutions, configuring spark, docker images, runtime environments, and scaling.
Integrating Existing Storage
When migrating from DataBricks to KubeFlow, an organization might prefer to keep their existing storage solution, as to avoid the need to move the entirety of their data to a new storage provider. As such, we had to provide secure and seamless access to S3, from the new Kubeflow environment. This means we had to configure IAM roles and service accounts for which users and accounts could securely access data in relative S3 buckets.
Configuring Spark
As mentioned in the previous parts of this series, within DataBricks, Spark configuration happens automatically; but in KubeFlow, developers have to overtly configure parameters for executor memory, CPU allocation, dynamic allocation, and shuffle services to ensure stable and efficient execution. For the platform itself, we had to ensure that we provided a stable environment for the Spark jobs to execute and terminate without affecting or being affected by other deployments on the cluster.
Docker Images
In part 2 of this series, we discussed how Docker images were used as a means to ensure production data was immutable. Similarly, we had to create Docker images with the correct Scala versions, Spark runtimes, and Kubernetes specific configurations and dependencies so that Scala and Spark would be able to run properly. Additionally, we had to keep these images as lightweight as possible to avoid unnecessary overhead.
Runtime Environments
We needed to create a runtime environment where Scala would be able to execute as a Kubernetes pod. As such, we had to be mindful of how to launch Scala applications, manage their lifecycle, and interact properly with Spark services running in the cluster.
Scaling
Our use case required resource scaling as data size was variable, meaning a client could upload a small portion of data, or a large chunk of data at a single instant, and in that instant, data had to be processed efficiently and effectively. The infrastructure we designed had to be able to efficiently scale to accommodate these varying workloads, without over-provisioning resources which would lead to unnecessary expenditures.
Best Practices
Internal Existing Storage
Integrating the existing storage solution which was used with DataBricks was an integral part of our use case. As with an existing code base, we found leveraging the existing storage solution, in this case S3, in our KubeFlow deployment to be the best course of action. In order to ensure the connection between our platform and storage was secure, we implemented IAM roles for service accounts (IRSA), which allowed Spark to access specific S3 buckets securely. Additionally, network policies were configured to control traffic between Spark components. An example of this implementation can be seen below.

Another caveat for our use case was that S3 buckets within a specific region, should not be accessible outside of that region. Meaning any Kubeflow deployment should only be able to access their specific S3 bucket, even if all buckets were under the same AWS account. As such, we established security groups and appropriate VPC configurations for cluster isolation.
In addition to the existing storage solution, we did explore alternative fast storage solutions for workloads requiring higher I/O performance. Specifically, we experimented with FSx for Lustre, and did find it to be a good alternative for data which needs to be quickly and readily accessible; but FSx does come at a much higher cost than S3. For that reason, we did use S3 for the majority of our processing needs. Oftentimes, it is much more cost-effective to spend time optimising Spark jobs to work well with S3, rather than using a fast storage solution like FSx.
Furthermore, for Spark executors specifically, we implemented appropriate storage class configurations for their persistent volumes. This ensured that Spark executors had consistent and reliable local storage for intermediate data. Data shuffle is a very taxing process, and these persistent volumes help to reduce shuffle inefficiencies, thus improving job stability. In the below example, you can see an example of how we defined these persistent volumes. By including a StorageClass with optimized IOPS (Input/Output Operators per Second) and throughput settings, we were able to balance performance with cost, ensuring that the relative Spark jobs had the necessary disk performance without over-provisioning expensive resources.

Configuring Spark
The primary configuration which we found provided the best performance as well as a stable environment was designating a dedicated node group for Spark. We wanted to ensure that no other applications or deployments would affect our pipelines by killing the nodes or taking up resources; therefore, tagging a dedicated node group for Spark jobs was the best way to ensure pipeline stability.
The below example is a script for node pool provisioning where we specified m5.8xlarge machines, a local storage for shuffle operations, and a node auto-scaler to dynamically spin up and terminate nodes based on workload demands. By applying taints and labels, we ensured that only Spark executors could run on these nodes, preserving resource isolation. We also limited the total CPU and memory capacity available to this pool, and set a short TTL to quickly release unused nodes, helping to reduce cost without sacrificing performance. In our actual deployment, we completed this configuration directly within AWS, but the below example in YAML form, can help illustrate this deployment more clearly.

Docker Images
In part 2, we mentioned how Docker images were a crucial tool to learn when dealing with Kubeflow pipelines. In this part, we will reiterate this sentiment, but focus on the platform aspect of Docker images. To start, when creating a Docker image for our Spark containers, we had to choose the right base image. We began with a minimal Debian-based image to the overall size of the image. From here, we included all necessary dependencies, which were Java, Scala 2.12 and Spark 3.5. Furthermore, prior to building, we verified the compatibility between our Scala version, Spark version and Kubernetes integration. This step was critical, as even a minor version mismatch between Spark and Kubernetes dependencies can lead to runtime errors or connectivity issues during executor startup. By starting with a minimal base image and layering only essential components, we also reduced attack surface and build time.
When Docker images are in a working state, it is essential to take time to optimize Docker containers, to improve deployment efficiency. Primarily, ensure only necessary files are included in the build. Oftentimes during development, unnecessary files or dependencies, such as temporary tools, unused libraries or language runtimes, can accidentally be left behind in the image. These remnants will cause an increase in image size and can introduce security vulnerabilities, which slow down container distribution.
Below is an example of a Docker image which can be used to run Scala jobs. This Dockerfile can be used as a reference to build a lean, production-ready Spark container image, using a multi-stage build approach. To start, the image leverages an openjdk:11-jdk-slim base to reduce size, and installs Coursier and Ammonite, which are essential tools for managing Scala dependencies and interactive execution. The final image installs only basic tools, such as python, pip and curl, followed by Spark dependencies like Pyspark, Boto3 and Kubernetes. Again, this is an example, so both Spark with Scala and Spark with Python examples are included in this Dockerfile.
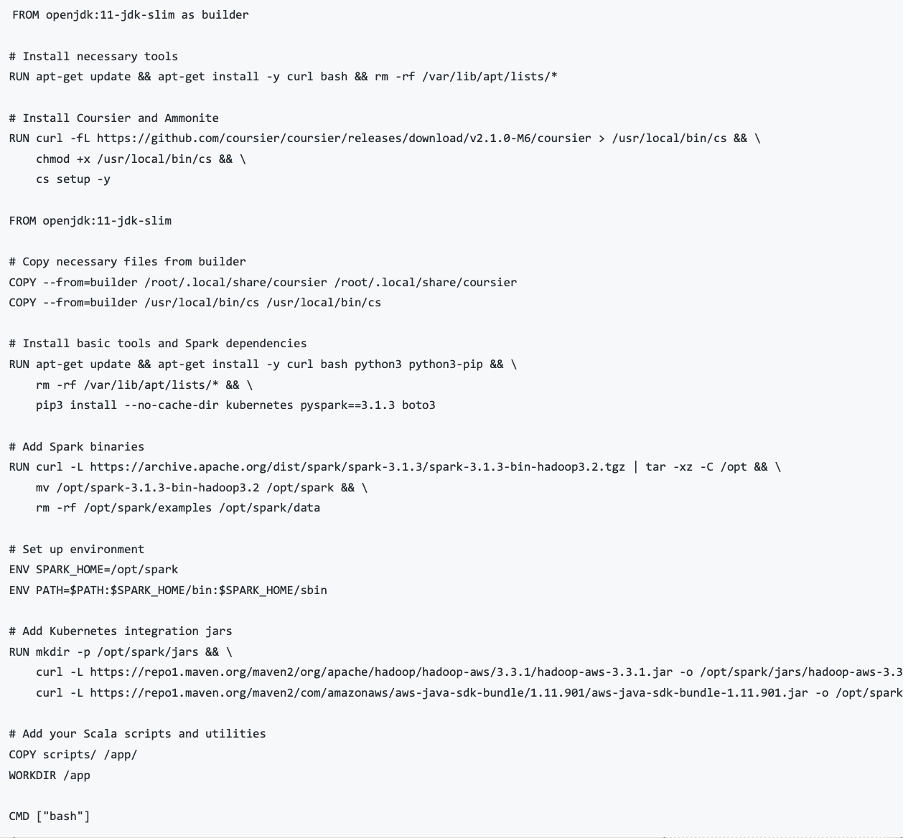
The Spark runtime itself is added manually from the official Apache archive, with non-essential example files and datasets removed to minimize container size. Environment variables are configured for Spark execution, and AWS integration jars are downloaded to support interaction with S3 via Hadoop. Finally, project-specific Scala scripts and utilities are copied into the image, and the working directory is set to /app, ensuring the container is lightweight, functional, and tailored specifically for Spark workloads within Kubernetes environments.
Runtime Environments
In order to ensure seamless execution of Scala-based Spark jobs within Kubeflow Pipelines, we had to develop a reliable and flexible runtime environment that could integrate tightly with both Kubernetes and Spark. After evaluating multiple approaches, we chose to use Coursier CLI as our core tool for executing Scala applications inside Kubernetes pods. This decision gave us a lightweight mechanism for launching Scala scripts without relying on heavier build tools like SBT, which would have increased complexity and image size.
To ensure our Spark jobs had the correct permissions and communication channels within the Kubernetes environment, we created dedicated service accounts for each pipeline component. These accounts were configured with access to manage driver and executor pods, configure networking, mount persistent volumes, and interact with cloud services like S3. This setup allowed each pipeline step to run with the necessary privileges while maintaining a secure and isolated environment. Additionally, we introduced a standardized mechanism for passing data between pipeline steps using shared persistent volumes. By leveraging a file-based interface and lightweight metadata tracking, we ensured downstream components could access the output of previous jobs reliably, with minimal I/O overhead. This combination of runtime control, service account isolation, and persistent data sharing formed the foundation for a scalable and maintainable integration between Spark, Scala, and Kubeflow Pipelines.
Scaling
To optimise cost and cluster performance, we implemented autoscaling, which allowed Nodes to scale up quickly when they were needed for Spark jobs and scale down when jobs were completed. We leveraged Karpenter as our autoscaling solution, as it offered faster and more responsive node provisioning compared to the default Cluster Autoscaler. This responsiveness was particularly important for our use case, where Spark jobs could be submitted at irregular intervals and required immediate access to compute resources. To ensure that the autoscaler behaved predictably under varying workloads, we configured scaling thresholds based on both CPU and memory utilisation, enabling the cluster to react proportionally to demand.
In addition, we introduced pod disruption budgets to maintain pipeline stability during scale-down events. These budgets prevented Karpenter from evicting critical pods too aggressively, allowing running jobs to complete without interruption. We also applied a short time-to-live (TTL) for idle nodes, typically 30 seconds, which allowed the cluster to quickly reclaim unused resources once jobs finished executing. This TTL setting, combined with our resource-aware scaling thresholds, helped us strike a balance between cost savings and job readiness, ensuring that our infrastructure remained both efficient and responsive to workload demands.
Further optimization came in the form of infrastructure sizing. When developing our pipelines and determining resource requirements, we analyzed Spark job metrics to determine optimal node size. We wanted to maintain a threshold where the executors were being used to their maximum capacity, without running into Out Of Memory (OOM) errors. As such, we implemented appropriate instance types based on whatever the requirements were from a given workload.
Additional Suggestions
Once the platform itself was built and deployed, we had to further explore optimization strategies to ensure resources were not overutilized. One such optimization involved refining our storage usage. While Spark jobs often rely on temporary storage for shuffle operations and intermediate files, persistent storage can quickly become costly if left unmanaged. To address this, we used Amazon S3 as our primary storage solution due to its scalability and low cost, and implemented S3 lifecycle policies to automatically transition older data to lower-cost storage tiers. For temporary files, intermediate processing and execution logging, we leveraged ephemeral storage, avoiding unnecessary persistent volume claims and reducing overall storage costs. The logs from this ephemeral storage could be visible directly in the Kubeflow pipeline application.
In parallel with storage optimizations, we implemented a robust quota management system to ensure fair resource allocation across teams and workloads. Using Kubernetes namespace-level resource quotas, we enforced upper limits on CPU, memory, and pod usage, which prevented any single pipeline or user from monopolizing shared infrastructure. To maintain balance within the cluster, we also defined limit ranges to guide the default resource requests and limits for containers.
In the below example, we define a ResourceQuota in the kubeflow namespace to enforce limits on how much compute each workload can consume. This configuration sets hard caps on both resource requests and limits, ensuring that no single job or component can overwhelm the cluster. Specifically, workloads in this namespace can collectively request up to 256 CPUs and 512Gi of memory, but must not exceed 512 CPUs and 1024Gi of memory in total usage. Additionally, a cap of 100 pods helps prevent runaway scheduling that could saturate the cluster. This quota was a key part of our strategy to maintain fair resource allocation, improve stability, and safeguard critical workloads running within our Kubeflow environment.

Conclusion
Migrating from a managed platform like Databricks to an open-source alternative such as Kubeflow can seem like a daunting endeavour. While the appeal of flexibility, control, and long-term cost reduction is evident, the path to achieving those benefits requires a deliberate investment in platform engineering. As we’ve outlined throughout this 3 part series, success hinges not just on converting code or creating pipelines, but on building a robust, scalable, and maintainable environment that supports the full lifecycle of Spark-based workloads. From configuring storage and tuning Spark, to managing Docker images, designing runtime environments, and setting up autoscaling, each layer of the stack must be intentionally crafted to meet the specific needs of the workloads it supports.
This level of customization introduces challenges, particularly for teams accustomed to the conveniences of Databricks; however, it also opens the door to a more deeply optimized infrastructure, one that is shaped around the actual workflows and usage patterns of an organization. By adopting the best practices we outlined in this series and aligning development with platform constraints, teams can unlock new levels of efficiency, transparency, and scalability. Kubeflow may not offer the same out-of-the-box simplicity as Databricks, but it empowers engineering teams to take full ownership of their data pipelines. For organizations that value this control and are willing to invest in the learning curve, Kubeflow offers a powerful foundation for building resilient, cost-effective Spark platforms at scale.
As mentioned in previous instalments, this series is not meant to quantify the superiority of either platform. The decision to switch from Databricks to Kubeflow is one which is particular to each individual organization; but we hope that this series can shed some light on the challenges which may be faced as well as the solutions which could be employed to overcome them. Whether you’re evaluating the feasibility of converting to Kubeflow, deep within a converting already, or are just curious as to the alternatives to Databricks, we hope this series has served as a valuable overview, offering clarity on the trade-offs involved, context for key architectural decisions, and practical insights to better understand what a transition to Kubeflow might entail.
Part 1: Scala with Spark Legacy Code Conversion
Part 2: Running within a Kubeflow Pipeline (KFP)
Part 3: Platform Engineering for Scala with Spark