Introduction
Modern businesses are racing to integrate Large Language Models into their data platforms for more dynamic, conversational analytics. In the wake of this AI race, Retrieval-Augmented Generation (RAG) pipelines have quickly emerged as the key architecture for feeding LLMs with fresh, relevant knowledge. A survey of hundreds of AI engineers, conducted by Amplify, found that about 70% of these AI engineers are leveraging RAGs in one way or another. Despite the proven benefits of implementing RAGs, most companies have self-admitted to not being prepared for such a drastic transformation of their data infrastructure. As mentioned in a previous article, a study conducted by MIT Technology Review Insights and Snowflake found that 78% of businesses feel unprepared for generative AI due to poor data foundations. This leaves CTOs with a major problem: “how do you integrate cutting edge data technologies, without blowing your budget on development and cloud costs, even when a solid data foundation doesn’t currently exist in your organization?”
Building a production-grade “RAG factory” is easier said than done. A naïve approach might try to re-embed an entire corpus every time new data arrives, but that’s incredibly wasteful. This practice would be akin to reprinting an entire library just because someone dropped off a new book. This brute-force strategy burns your capital on cloud costs and still leaves gaps, as answers go stale between full index rebuilds. The real challenge lies in continuously feeding an LLM with fresh, trustworthy data without breaking the bank and bankrupting your organization in the process. In this blog, I’ll tackle exactly that: “what considerations you have to be mindful of when deciding to undertake a RAG pilot project and how to avoid blowing your budget when moving this pilot to production”.
This blog will frame RAG as a strategic platform decision and focus on the business problem for CTOs and other decision makers. From a business standpoint, how do you deliver LLM value when the data foundation isn’t ready, without letting embedding and indexing costs spiral out of control? I’ll explain why naïve “embed everything” pipelines cause runaway expenses and stale answers and introduce a stakeholder-friendly blueprint for an incremental RAG factory with cost controls built in from day one.
The outcome is a clear roadmap of what drives RAG spend, what to optimize first, and how an incremental approach delivers usable results early while keeping the budget predictable.
RAG as a Platform, Not an Experiment
LLMs change what is expected and required from a traditional data platform. Instead of only serving dashboards and reports, a modern platform must feed live knowledge to AI models, meaning current facts, documents, and context that an LLM can use when answering questions. Retrieval Augmented Generation, or RAG, makes this possible by bridging enterprise data to the model at query time. You can think of it as a guided lookup experience, similar to walking into a library and asking a librarian to locate the right source, confirm it is current, and point you to the exact passage you need.
This is why RAG is rapidly becoming a default production pattern. Menlo Ventures reports that 51% of enterprise AI implementations used RAG in 2024, up from 31% in 2023, based on a survey of 600 United States enterprise IT decision makers. This rapid adoption reflects a clear value add that IT decision makers are actively prioritizing; thus, they are moving quickly to leverage RAGs for production use.
However, many organizations lack the data infrastructure to support RAG at scale. If source data is messy, siloed, or difficult to access reliably, the model will not be able retrieve the facts it needs, thus making the results of a company’s RAG project appear lack-luster. A major reason as to why 78% of organizations are not very ready to support generative AI, is largely due to weak data strategies and poor data foundations.
In practice, early RAG work often starts as a pilot, for example a prototype with a small, curated dataset and a manually managed index. This approach is useful because it proves value and establishes an early cost baseline. It also acts as a data platform maturity benchmark. A pilot quickly exposes what is missing in the foundation, such as reliable ingestion, update frequency, document versioning, deletes, permissions, metadata quality, and operational ownership. If those gaps are not addressed, moving from pilot to production becomes slow, tedious, and expensive because every additional source increases both complexity and spend.
The mindset shift is to treat RAG as an enterprise platform capability. A RAG factory should be built with the same intentionality as any other production ready data pipeline, including deliberate data flow design, cost controls, monitoring, and governance. When CTOs frame RAG as a long-term platform decision, they can justify investment because it is tied to strategic outcomes, not a standalone experiment. Just as importantly, they can insist that pilots are used to validate value and reveal maturity gaps, then use those findings to define the roadmap that keeps accuracy high and costs predictable as adoption scales.
The Cost Challenge: Why Naive RAG Pipelines Melt Your Cloud Bill
Early RAG implementations often run into an unpleasant surprise for the bookkeepers: runaway costs. The main culprit is usually a naive pipeline that doesn’t account for scale. Imagine a manager who asks you to embed every document in your company on every update, “just to be on the safe side”. This might work for a pilot project, but at enterprise scale, it could financially cripple your cloud budget. To put this into perspective, consider a mid-to-large enterprise managing a knowledge base of 50 million documents, which is not uncommon for sectors like insurance, legal, and banking. Using an inexpensive embedding rate of $0.0001 per 1,000 tokens, a full re-embedding pass costs roughly $2,500. If you run this as a weekly process, your company would be burning $130,000 a year on embeddings alone.
Unfortunately, embedding is not the only cost which your company would incur. There are massive additional costs that accompany these runs, such as the compute hours required to parse and chunk terabytes of PDFs, the network egress fees for moving that data across cloud regions, and the high throughput “write units” charged by vector databases for re-indexing millions of vectors. In reality, the operational overhead can easily double the bill, adding another $3,000 to $5,000 per run in pure compute and I/O costs. When you tally the total spend, a brute-force approach isn’t just unsustainable in the long term, it’s extremely fiscally irresponsible.
Aside from cost, fully rebuilt pipelines also lead to stale answers. If you only refresh the index periodically because rebuilds are slow and expensive, new or updated information is not immediately available to the model. Users can therefore end up with outdated answers, even when the right data already exists, simply because the pipeline has not ingested, reprocessed, and reindexed it yet. That type of shortcoming undermines the whole point of RAG, which is to provide fresh and reliable context at query time.
Naive RAG designs are also fragile because they struggle with deletes and change propagation. In practice, a deleted document can linger in the index, or an older version can remain retrievable long after it should have been removed. The result is a system that behaves like a prototype, not a production pipeline.
To further illustrate these pitfalls, let’s look at a few major cost drivers in RAG that must be tamed:
- Re-embedding unchanged content: Recalculating embeddings for text that has not changed adds no real value, yet naive pipelines do it anyway. If 95% of your data is unchanged in a given week, then roughly 95% of that week’s embedding spend is spent on work you already paid for. This is why incremental change detection is the first place to target in any cost-efficient design. In the library analogy I presented previously, this would be like re-cataloguing every book because a single new book arrived at the library’s front desk. A cheaper and more scalable method is to catalogue only what is new or modified and leave the rest alone.
- Overly small chunks or heavy overlap: When it comes to embedding, how you chunk your documents can multiply costs as well. If you split text into tiny chunks or use large overlaps between chunks, you end up with many more embedding vectors which often contain redundant text, as a consequence. For example, splitting each document into 50 little pieces instead of 5 big pieces means 10 times more vectors to embed, store, and search. The amount of overlap, which is duplicated text in successive chunks, further balloons the index size and embedding count. That is the inherent trade off. Larger chunks may be cheaper, but small chunks can improve retrieval accuracy for a greater cost. Typically, there is no ideal answer here and each use case will need to find a balance in chunk sizing to control this, so this is something development teams will need to assess and test on a case-by-case basis.
- “Embed everything” mentality: As previously mentioned, some teams make the mistake of indexing their entire datalake indiscriminately, by dumping every log, every obsolete report, and every snippet of text into the RAG pipeline “just in case”. This not only inflates costs by embedding data nobody cares about or will ever use, but it can hurt quality, as the LLM might retrieve irrelevant or low-value information. Not all data is equally useful. For instance, a decades-old archive of policy documents might never be queried for a modern assistant. Embedding all of it upfront would be money down the drain and could lead to a “garbage-in garbage-out” data problem.
The bottom line is that without careful design, RAG costs can scale indefinitely as you move from a pilot to an enterprise deployment. Fortunately, we can do much better. Once you identify the core cost drivers, you can introduce controls and optimizations that materially reduce spend. That starts with understanding what data you have, what data actually needs to be automated, and building a reliable ingestion and refresh process. From there, you can ensure that only relevant, valuable, and current content is embedded, which is the first step toward a cost-efficient system.
Core Pipeline Zones for Efficiency
To build a cost-efficient RAG pipeline, it helps to break the process into logical pipeline zones. Each zone focuses on a stage of data preparation, with controls to avoid redundant work. This structured approach ensures new information flows from your data lake into the RAG system incrementally, only processing what’s changed or what truly needs to be processed. The typical pipeline zones include, but are not limited to:
- Raw Data Zone (Ingestion): This is the entry point where source data is ingested in its original form. The goal here is to capture new and updated data continuously, without reloading everything. For instance, rather than bulk-reading an entire database nightly, the raw zone would use change capture or event streams to pull in just the new or modified records. By detecting changes upfront, you immediately eliminate unnecessary downstream processing on unchanged, previously processed data or irrelevant data. This is the first base for cost control. If nothing changed, then nothing new should flow down the pipeline, saving you time and cloud spend. In the above library example, the raw zone makes sure your RAG factory only “catalogues new books” instead of re-cataloguing the whole library each day.
- Curated Zone (Refinement & Filtering): Once data lands in raw form, it moves to a curated layer for cleaning, normalization, and filtering. Think of this as your data prep workshop. Here the pipeline parses documents (PDFs, HTML, and so on), removes duplicates and irrelevant content, and enriches the data with metadata such as timestamps, source tags, and access permissions. For example, if the raw zone ingested a new policy document, the curated zone would strip away boilerplate text, extract the useful content, and tag it with version information. This stage enforces quality over quantity, so only valuable, ready-to-use information proceeds. By curating incrementally, you drop low-value content early, avoiding the cost of embedding and storing data that will never be useful, and ensuring that what you do embed is representative of high-quality business knowledge. This layer ties directly to return on investment because it reduces noise, improves retrieval precision, and keeps embedding spend focused on the sources that are most likely to be queried.
- Embedded Zone (Vector Creation): In this zone, curated text is converted into vector embeddings via an ML model of your choosing, like those offered by OpenAI or HuggingFace for example. Cost between models can vary significantly, so the trick for cost savings is to both pick the appropriate model for your use case and to embed only new or updated content. Not every use case requires the most capable and highest cost model. Furthermore, since the pipeline has already flagged which documents or sections changed, the embedding step can skip over everything previously seen. Additionally, careful chunking strategies can be applied at this stage to balance cost and accuracy. Instead of naively embedding every sentence or creating huge overlaps, the pipeline can use an optimal chunk size, splitting documents into a reasonable number of pieces, so that we can minimize the number of vectors while preserving search relevance. This is a major cost control point. If 95% of a document directory is unchanged, the embedding zone should be recomputing vectors for, at most, the 5% of documents that actually changed, assuming that this 5% is relevant content worth embedding. Modern data engineering practices might include tracking a content hash or version number for each chunk, so the system knows when to reuse an existing embedding. By doing so, the embedded zone prevents duplicate efforts and ensures you’re not paying multiple times for the same result. Every dollar spent here is for net-new or updated knowledge added to the system, which leads to a clear return on your AI investment.
- Indexed Zone (Vector Index & Serving): The final zone is where fresh embeddings are indexed into a vector search database and made queryable for your LLM applications. A robust design treats the index as an incrementally updateable service rather than a static artifact. New vectors are upserted into the index, and outdated ones are removed or tagged as deleted. Techniques like rolling index updates or even a blue/green index deployment can ensure updates happen continuously without taking the system offline. For decision-makers, this means your platform is always serving the latest information to the LLM, eliminating the stale answers that occur when indexes only refresh during infrequent big rebuilds. Equally as important, the indexed zone can be monitored and scaled selectively. For example, if one particular data source’s vector is queried heavily, you might be able to allocate more resources there without reprocessing everything else. In short, the indexed zone provides the live knowledge base for LLM retrieval, and by updating it incrementally, you achieve a stable, predictable cost of maintenance. The business wins because users get timely, accurate answers, driving higher satisfaction and trust in the AI you’ve invested in, all while infrastructure costs remain controlled and proportional to the actual rate of data change.
The Four-Layer RAG Data Pipeline Architecture
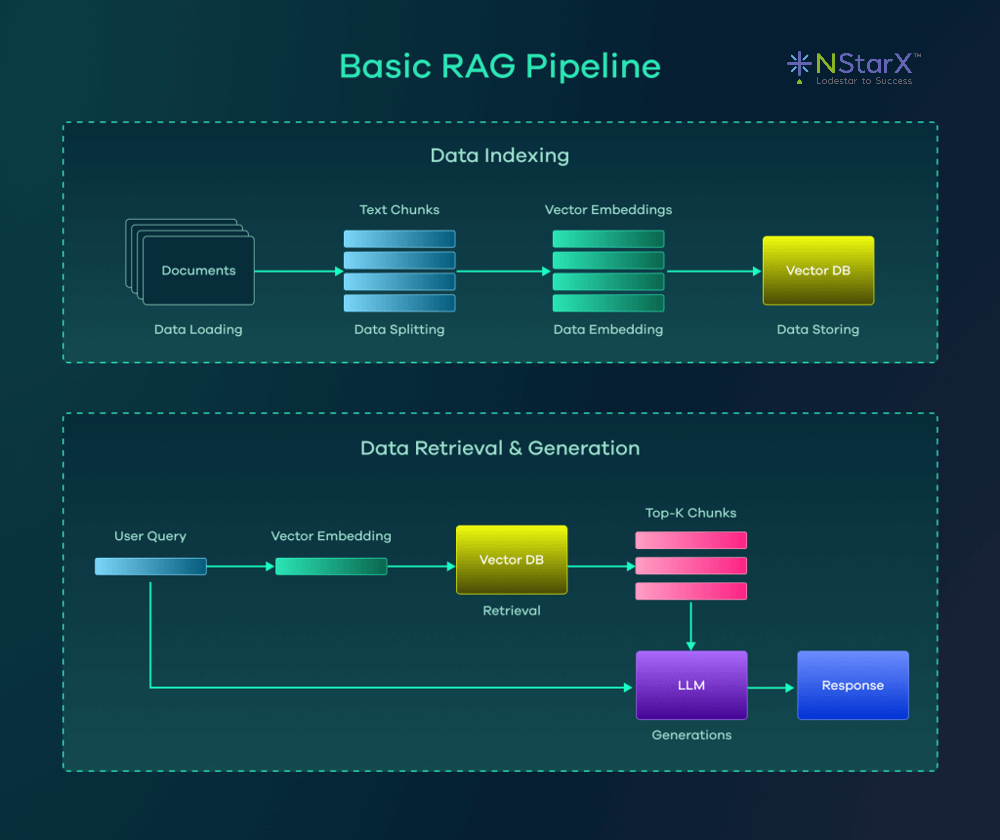
Basic RAG pipeline architecture from lakeFS with distinct data indexing and retrieval stages. Source documents are transformed into vector embeddings (indexing phase), and user queries retrieve relevant vectors which the LLM uses for answer generation.
Breaking the pipeline into clear “zones” is what keeps a RAG build from turning into a messy, expensive, and ultimately unusable pilot project. Each zone has one job, and you only do work when something actually changed. That’s the real purpose of this type of structure. Compute stays proportional to change, not to the size of your datalake. When you treat ingest, curation, embedding, and indexing as separate checkpoints, it becomes much easier to control cost, enforce quality, and keep retrieval fresh, without constantly reprocessing everything.
The Need for Incremental Updates
Underpinning all these zones is the strategy of incremental updates, which is the cornerstone of cost efficiency in RAG. Rather than periodic big-bang refreshes that recalculate the world, the pipeline should continuously trickle changes through. This design has several business advantages: it delivers value faster (new data is searchable within hours or even minutes, not weeks), and it keeps the cloud bill in check by never doing work that isn’t needed. Incremental processing also makes costs predictable as you don’t see huge spikes in spend because the pipeline load stays roughly proportional to actual business activity. For example, the amount of new or changed data created this week typically should define the upper bound for what the pipeline needs to process. Predictability is a CFO’s dream when it comes to budgeting for AI infrastructure. Moreover, an incremental approach lets the team iterate and improve the pipeline on the fly. If a particular data source starts generating too much noise, you can fine-tune the curation or chunking for that source alone, without redoing the entire index. In other words, the company can deliver usable results early, by onboarding a few high-value sources first through the pipeline, prove the value add of those, and then gradually expand, all the while keeping the budget under control. This incremental philosophy turns RAG from a one-off project into a sustainable, scalable operational capability.
Another benefit of an incremental approach is that you don’t need to boil the ocean on day one. Rather than spending months ingesting and embedding the entire data lake before an LLM can answer anything, you can start with a slice of high-value data and get a usable system running quickly. For example, you might begin with one department’s documents and build out the RAG pipeline for that subset. This delivers an early win where users can start asking the LLM real questions and getting answers with sources, while limiting initial startup costs. As you prove value, you can incrementally expand to more data sources and departments, confident that your pipeline will scale in a controlled way. Stakeholders love this approach because it demonstrates progress and ROI early, without the huge upfront cost and commitment. It’s essentially an agile methodology for AI data integration which delivers in slices, learns and adjusts, keeps the budget under control throughout, and allows all stakeholders to see the added benefit more quickly than they would from larger, more ambitious endeavors.
Conclusion
Implementing Retrieval Augmented Generation at scale is not just a technical endeavor, it is a strategic business move that requires balancing value delivery with cost management. Costs can quickly snowball if you do not define cost controls and a realistic spend plan up front, especially when data infrastructure gaps are still being addressed.
In this blog, we framed the challenge many decision makers face in how to go from a pilot project to a production solution, without blank check spending or endless infrastructure churn. The solution lies in treating RAG as a platform, built with the same rigor as any core data system, and adopting an incremental pipeline design from day one, working and growing iteratively. Starting small and calculated, only expanding when previous phases are in fully optimized, automated working condition.
By breaking the overall pipeline into zones (raw, curated, embedded, indexed) and enforcing incremental updates, organizations can avoid the trap of the “embed everything” inefficiency. Instead, you invest resources where they count by ingesting only new or changed data, refining it into quality information, embedding only what is relevant and updated, and keeping the index current in a lightweight way. The payoff is twofold. Firstly, cost savings and predictable spend on the operational side, and secondly, better ROI on the innovation side because your LLM applications are always using relevant, up-to-date knowledge to generate answers that employees and customers can trust.
In essence, a well-designed RAG factory turns your data lake into a living knowledge repository that can fuel AI driven insights without melting your cloud budget. With the groundwork laid and the business case established, you can move forward confidently. The message for CTOs and tech leaders is clear. You do not need a perfect data foundation to begin reaping value from generative AI. What you need is a pragmatic, cost-aware RAG approach. Build the RAG platform iteratively, treat it as a long-term investment, and it will return value many times over, in agility, in user satisfaction, and in the bottom line.
References
-
- Amplify Partners. “The 2025 AI Engineering Report.” https://www.amplifypartners.com/blog-posts/the-2025-ai-engineering-report
- Nimbleway. “Step-by-step Guide to Building a RAG Pipeline.” https://www.nimbleway.com/blog/rag-pipeline-guide
- Menlo Ventures. “2024: The State of Generative AI in the Enterprise.” https://menlovc.com/2024-the-state-of-generative-ai-in-the-enterprise/
- Fluree. “GraphRAG & Knowledge Graphs: Making Your Data AI-Ready for 2026.” https://flur.ee/fluree-blog/graphrag-knowledge-graphs-making-your-data-ai-ready-for-2026/
- Sadik Shaikh. “RAG in Production — Scaling, Costs & Future Trends.” https://medium.com/@sadikkhadeer/rag-in-production-scaling-costs-future-trends-fc76473745a4
- Databricks. “Build an Unstructured Data Pipeline for RAG.” https://docs.databricks.com/aws/en/generative-ai/tutorials/ai-cookbook/quality-data-pipeline-rag
- Reddit r/LLMDevs. “Ingestion + chunking is where RAG pipelines break most often.” https://www.reddit.com/r/LLMDevs/comments/1pu52yw/ingestion_chunking_is_where_rag_pipelines_break/
- DaveAI. “How to Structure Data for RAG: The Role of Token Splitting.” https://www.iamdave.ai/blog/how-to-structure-data-for-rag-the-role-of-token-splitting/
- NetSolutions. “Decoding RAG Costs: A Practical Guide to Operational Expenses.” https://www.netsolutions.com/insights/rag-operational-cost-guide/
- Amazon Web Services. “Get started with Amazon Titan Text Embeddings V2: A new state of the art embeddings model on Amazon Bedrock.” https://aws.amazon.com/blogs/machine-learning/get-started-with-amazon-titan-text-embeddings-v2-a-new-state-of-the-art-embeddings-model-on-amazon-bedrock/
- Amazon Web Services. “Amazon Bedrock pricing.” https://aws.amazon.com/bedrock/pricing/
- Tech Monitor. “Survey reveals 78% of businesses unprepared for gen AI due to poor data foundations.” https://www.techmonitor.ai/digital-economy/ai-and-automation/survey-reveals-78-of-businesses-unprepared-for-gen-ai-due-to-poor-data-foundations
- lakeFS. “RAG Pipeline: Example, Tools & How to Build It.” https://lakefs.io/blog/what-is-rag-pipeline/