AUTHOR: NSTARX Engineering team talks about how GPU capacity planning and cost control is so critical for AI workloads in production. This article is at least 25-30 minutes read.
A) GPUs: The Epicenter of Modern AI Workloads
Graphics Processing Units have evolved from their original purpose of rendering graphics to becoming the fundamental building blocks of artificial intelligence infrastructure. Unlike traditional CPUs that excel at sequential processing, GPUs deliver massive parallel computing power essential for the matrix operations that underpin neural networks.
Modern AI workloads demand computational capabilities that only GPUs can provide. Training a large language model, processing real-time inference requests, or running computer vision pipelines all require thousands of parallel operations executed simultaneously. A single NVIDIA H100 GPU, for instance, can perform over 1,000 trillion operations per second on AI workloads—a level of throughput unattainable with CPU-only architectures.
GPUs have become the critical bottleneck and success factor for AI initiatives. They represent both the largest infrastructure investment and the primary performance determinant for machine learning systems. Whether training foundation models, fine-tuning for specific domains, or serving production inference, GPU availability and efficiency directly translate to business outcomes.
B) Why GPU Capacity Planning and Cost Control Matter
The economics of GPU infrastructure present unique challenges that make capacity planning and cost control business-critical priorities rather than mere operational concerns.
Financial Impact: GPU costs dominate AI infrastructure budgets. High-end accelerators like H100s or A100s can cost between $25,000 to $40,000 per unit in capital expenditure, with cloud instances ranging from $2 to $8 per hour depending on the GPU type and provider. For organizations running hundreds or thousands of GPUs, monthly cloud costs can easily exceed millions of dollars.
Utilization Complexity: Unlike traditional compute resources, GPUs exhibit binary efficiency characteristics—they deliver maximum value at high utilization but become exponentially wasteful when underutilized. A GPU running at 30% utilization isn’t delivering 30% of the value; it’s often delivering less than 10% due to the fixed costs of memory allocation, data transfer overhead, and inability to effectively share resources across workloads.
Resource Scarcity: The global shortage of advanced GPUs creates a unique dynamic where capacity constraints often matter more than costs. Organizations face multi-month wait times for hardware procurement and encounter quota limitations from cloud providers. Poor capacity planning doesn’t just waste money—it can delay critical AI initiatives by quarters.
Multi-dimensional Optimization: GPU capacity planning requires simultaneously optimizing across cost, performance, availability, and time. A training job that could complete in 8 hours on 64 GPUs versus 32 hours on 16 GPUs presents different cost-performance tradeoffs that vary based on current utilization, upcoming deadlines, and opportunity costs.
C) Real-World Examples: Success and Failure in GPU Management
Failure Case: The Stranded GPU Catastrophe
A prominent fintech company embarked on an ambitious initiative to build proprietary fraud detection models. They reserved 200 A100 GPUs from their cloud provider for six months at a committed spend of $2.4 million, securing a 40% discount over on-demand pricing.
Three months into the reservation, their ML team discovered that their training pipeline had critical inefficiencies. Data preprocessing bottlenecks meant GPUs sat idle 60% of the time waiting for batch preparation. The team attempted to refactor their pipeline, but the changes required rewriting significant portions of their training infrastructure.
The result: $1.4 million in stranded GPU spend over the remaining three months. The reserved capacity couldn’t be released or repurposed effectively, and the team couldn’t justify spinning up additional workloads to consume the idle capacity. The failed reservation became a cautionary tale in their quarterly business review.
Success Case: Dynamic Capacity Management
A mid-sized AI research lab took a fundamentally different approach. They implemented comprehensive workload profiling before committing to any long-term reservations. Their analysis revealed:
- Training workloads ran 24/7 but had predictable compute patterns
- Inference workloads showed strong diurnal patterns with 4x variance between peak and trough
- Research experimentation was highly bursty and unpredictable
Based on this profiling, they adopted a three-tier strategy:
- Reserved instances for baseline training workloads (30% of peak capacity)
- Scheduled scaling for predictable inference patterns (40% of peak capacity)
- Spot instances and preemptible capacity for research workloads (30% of peak capacity)
This approach reduced their effective GPU costs by 52% while actually improving resource availability for time-sensitive workloads. More importantly, they avoided stranded spend by matching commitment durations to actual workload lifecycles.
Failure Case: The Queue Collapse
A healthcare AI company built a centralized GPU cluster to serve multiple ML teams. They implemented a simple FIFO queue system where jobs were processed in submission order. The system appeared to work well initially with 85% average utilization.
However, after six months, the queue became dysfunctional. Large multi-day training jobs monopolized all resources, causing small inference deployment tests to wait days for execution. Research teams began hoarding GPUs by submitting placeholder jobs, creating artificial scarcity. The average time from job submission to completion increased by 400%, effectively rendering the shared cluster unusable.
The company eventually had to invest in a complete redesign of their scheduling infrastructure and workload orchestration, representing six months of engineering effort that could have been avoided with proper planning.
D) The Amplified Challenge: Generative AI and Agentic AI
The emergence of generative AI and agentic AI systems has fundamentally intensified the GPU capacity planning challenge in several dimensions:
Scale and Unpredictability
Generative AI models operate at unprecedented scales. Training GPT-class models requires thousands of GPUs for weeks or months. However, the resource requirements are highly non-linear and difficult to predict. A model might converge faster than expected, or require additional training runs to achieve target performance metrics. This uncertainty makes traditional capacity planning methods inadequate.
Multi-Stage Workflows
Modern GenAI applications involve complex multi-stage pipelines: pre-training, fine-tuning, alignment training (RLHF), distillation, and continuous deployment. Each stage has different GPU requirements, memory constraints, and batch size considerations. Poor planning at any stage creates cascading bottlenecks throughout the entire workflow.
Inference Explosion
Unlike traditional ML models, generative AI inference is computationally intensive. A single GPT-4 class inference request might require billions of operations. As organizations deploy more LLM-based applications, inference costs often exceed training costs. Without proper capacity planning, inference workloads can create unexpected GPU shortages that impact both production services and development activities.
Agentic AI Complexity
Agentic AI systems that autonomously execute multi-step tasks introduce radical unpredictability in resource consumption. An agent might spawn multiple parallel sub-tasks, each requiring GPU acceleration. The system might need to handle anywhere from 10 to 1,000 concurrent agent workflows, making static capacity provisioning impossible.
Failed Reservations and Stranded Spend
These complexities create two critical failure modes:
Failed Reservations occur when organizations commit to GPU capacity based on initial estimates, only to discover their actual requirements are 3-5x higher due to longer training times, more iteration cycles, or architectural changes. Teams then face the choice of either severely limiting their work or paying premium on-demand rates while already committed to unused reserved capacity.
Stranded Spend manifests when teams over-provision to avoid shortages. Reserved GPUs sit idle because workloads completed faster than expected, architectural changes reduced GPU requirements, or coordination failures left resources unallocated. Unlike stranded CPU compute, idle GPUs represent astronomical waste due to their high unit costs.
The dynamic, exploratory nature of GenAI development makes both failure modes increasingly common. Research teams can’t accurately predict how many training runs will be needed, how long each will take, or what GPU configurations will prove optimal until well into the development process.
E) Critical Components of GPU Capacity Planning and Cost Control
Workload Profiling
Comprehensive workload profiling forms the foundation of effective GPU capacity management. Organizations must move beyond simple “we need more GPUs” requests to understand the actual computational characteristics of their workloads.
GPU Utilization Metrics: Track not just whether GPUs are allocated, but their actual compute utilization. Monitor GPU-SM (streaming multiprocessor) utilization, memory bandwidth utilization, and tensor core utilization. A GPU showing 100% allocation but 30% SM utilization indicates pipeline inefficiencies rather than compute constraints.
Memory Characteristics: Profile memory access patterns, bandwidth requirements, and working set sizes. Many workloads are memory-bound rather than compute-bound, making GPU selection and batch size optimization critical for cost efficiency.
Communication Patterns: For distributed training, profile all-reduce communication overhead, gradient synchronization time, and inter-GPU data transfer. Communication bottlenecks often limit scaling efficiency beyond certain GPU counts.
Temporal Patterns: Analyze workload submission patterns, job durations, and queue depths over time. Identify diurnal patterns, weekly cycles, and seasonal variations that enable more intelligent capacity provisioning.
Autoscaling
Effective autoscaling for GPU workloads requires sophistication beyond traditional CPU autoscaling due to the stateful nature of ML workloads and the high cost of GPU instances.
Workload-Aware Scaling: Implement scaling policies that understand ML workload semantics. Training jobs can’t be arbitrarily paused and resumed like stateless web services. Design autoscaling around natural checkpointing boundaries, allowing jobs to scale between epochs rather than mid-batch.
Predictive Scaling: Use historical patterns and job queue analysis to scale proactively rather than reactively. If the queue depth indicates 200 GPU-hours of pending work, provision capacity before job submission rather than after.
Multi-Tier Scaling: Implement different scaling strategies for different workload types. Scale inference workloads based on request latency and throughput. Scale training workloads based on queue depth and deadlines. Scale research workloads using spot instances and interruptible capacity.
Cost-Aware Policies: Configure autoscaling to consider economic factors, not just performance. Scale using spot instances first, fall back to on-demand only when necessary, and implement budget guardrails that prevent runaway costs.
Queueing and Scheduling
Intelligent queueing transforms GPU clusters from chaotic resource battles into predictable, efficient systems.
Priority-Based Scheduling: Implement multi-tier priority queues that ensure production inference workloads preempt research experiments, while preventing starvation of lower-priority jobs through fair-share algorithms.
Bin-Packing Optimization: Use advanced scheduling algorithms that pack workloads efficiently onto available GPU resources. Consider not just GPU count, but GPU memory requirements, CPU/memory ratios, and data locality to maximize cluster utilization.
Gang Scheduling: For distributed training jobs requiring multiple GPUs simultaneously, implement gang scheduling that allocates all required resources atomically or defers the job. This prevents partial allocation that wastes resources waiting for additional capacity.
Backfilling: Allow small, short-duration jobs to backfill into temporary gaps between large jobs, increasing overall utilization without impacting large job completion times.
Bin-Packing Strategies
Effective bin-packing maximizes the utility extracted from each dollar spent on GPU infrastructure.
Multi-Dimensional Packing: Consider GPU memory, system memory, CPU cores, and storage I/O as constraints when packing workloads. A workload requiring 40GB GPU memory can’t share an 80GB A100 with another 40GB+ workload, regardless of compute availability.
Fragmentation Management: Track and minimize resource fragmentation. If most workloads require 2, 4, or 8 GPUs, avoid creating odd-sized fragments (like 3 or 5 available GPUs) that remain unused.
Affinity and Anti-Affinity: Implement placement policies that colocate communication-intensive distributed training across minimal network hops while separating competing workloads to prevent I/O contention.
Preemption Mechanisms
Preemption enables efficient multi-tenancy and cost optimization by allowing lower-cost, interruptible capacity to serve appropriate workloads.
Checkpointing Infrastructure: Build robust checkpointing that allows training jobs to resume from saved state after preemption. Implement incremental checkpointing to minimize overhead and enable sub-hour recovery granularity.
Preemption Policies: Define clear policies for when and what gets preempted. Prioritize production inference, allow preemption of research workloads on spot instances, and implement grace periods for jobs approaching completion.
Spot Instance Integration: Leverage cloud provider spot/preemptible instances that offer 60-90% discounts over on-demand pricing. Design workloads to tolerate interruption through checkpointing and automatic restart mechanisms.
Migration Capabilities: Implement live migration or rapid restart capabilities that minimize disruption when preemption occurs, maintaining overall productivity despite interruptions.
Additional Critical Considerations
Monitoring and Observability: Deploy comprehensive monitoring across GPU utilization, memory usage, power consumption, temperature, error rates, and application-level metrics. Visibility enables proactive optimization and rapid issue resolution.
Cost Allocation and Chargeback: Implement accurate cost allocation to teams and projects. Visibility into actual costs drives accountability and informed decision-making about resource consumption.
Capacity Forecasting: Build models that forecast future capacity needs based on project roadmaps, historical growth rates, and planned initiatives. Forecast at multiple time horizons (weekly, monthly, quarterly) to inform both operational and strategic decisions.
Vendor and Region Diversification: Reduce dependency on single cloud providers or regions. GPU availability varies significantly across providers and regions; flexibility enables opportunistic capacity acquisition and cost optimization.
FinOps Integration: Embed GPU capacity planning within broader FinOps practices. Establish cost budgets, implement spending alerts, conduct regular cost optimization reviews, and align GPU investments with business value delivery.
F) Production Pitfalls in GPU Management
Pitfall 1: Over-Provisioned Reserved Capacity
Organizations commit to multi-month or multi-year GPU reservations to capture discounts, but significantly overestimate actual requirements. This creates stranded spend as idle GPUs accumulate costs without delivering value.
Pitfall 2: Lack of Workload Isolation
Multiple teams share GPU infrastructure without proper isolation mechanisms. Resource contention, noisy neighbors, and priority conflicts lead to unpredictable performance and developer frustration.
Pitfall 3: Inefficient Data Pipelines
GPU utilization suffers because data preprocessing, loading, and augmentation bottleneck on CPU resources. GPUs sit idle waiting for data, wasting expensive compute capacity.
Pitfall 4: Missing Checkpointing Strategy
Training jobs lack robust checkpointing, making them vulnerable to interruptions. Any failure requires restarting from scratch, wasting all previous computation and making spot instances unusable.
Pitfall 5: Static Capacity Allocation
Infrastructure is provisioned based on peak demand estimates and remains static. This results in either chronic shortage during peaks or massive waste during troughs.
Pitfall 6: No Cost Visibility
Teams lack visibility into their actual GPU consumption and associated costs. Without accountability, wasteful practices persist and optimization opportunities remain unidentified.
Pitfall 7: Fragmented Tooling
Different teams use incompatible frameworks, orchestration tools, and deployment patterns. This prevents resource sharing, complicates standardization, and multiplies operational complexity.
Pitfall 8: Insufficient Security Controls
Organizations optimize training workloads but deploy unoptimized models for inference. Inference then consumes 5-10x more GPU resources than necessary through lack of quantization, batching, and caching.
Pitfall 9: Queue Starvation
Large, long-running jobs monopolize all resources while small, time-sensitive jobs wait indefinitely. This creates perverse incentives where teams game the system by fragmenting work or hoarding resources.
Pitfall 10: No Capacity Governance
GPU resource allocation lacks governance processes. Ad-hoc provisioning, unclear approval workflows, and absent chargeback mechanisms lead to uncontrolled spending.
G) NStarX Best Practices for GPU Capacity Planning and Cost Control
Best Practice 1: Dynamic Capacity Rightsizing
Pitfall Addressed: Over-Provisioned Reserved Capacity, Static Capacity Allocation
NStarX Approach: Implement a hybrid capacity model with three tiers:
- Baseline Reserved Capacity (20-30% of peak): Commit to 1-year reserved instances for predictable, continuous workloads. Size this based on minimum guaranteed utilization across all teams.
- Flex Capacity Pool (40-50% of peak): Utilize savings plans or 3-month commitments that offer flexibility across instance types while capturing moderate discounts (20-35%). This tier absorbs predictable but variable workloads.
- Burst Capacity (20-30% of peak): Leverage spot instances, preemptible VMs, and on-demand capacity for experimental workloads, development activities, and unexpected demand spikes.
Implementation:
- Conduct quarterly capacity reviews analyzing actual vs. reserved utilization
- Implement automated rightsizing recommendations based on 90-day rolling averages
- Use capacity planning models that forecast needs across multiple scenarios (conservative, expected, aggressive)
- Establish escape clauses with cloud providers allowing capacity rebalancing every quarter
Expected Outcomes: Reduce stranded spend by 40-60% while maintaining 95%+ resource availability for time-sensitive workloads.
Best Practice 2: Multi-Tenant GPU Orchestration
Pitfall Addressed: Lack of Workload Isolation, Queue Starvation
NStarX Approach: Deploy Kubernetes with GPU operator extensions and implement namespace-based multi-tenancy with resource quotas and priority classes.
Implementation:
- Create dedicated namespaces for production, staging, development, and research workloads
- Implement resource quotas limiting maximum GPU allocation per namespace
- Configure priority classes: Critical (production inference), High (scheduled training), Medium (development), Low (research)
- Deploy network policies ensuring workload isolation and security
- Use pod priority and preemption to ensure high-priority workloads can evict lower-priority jobs
Technical Configuration:
yaml
# Priority classes definition
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: production-inference
value: 1000000
globalDefault: false
description: "Production inference workloads"
---
# Resource quotas per namespace
apiVersion: v1
kind: ResourceQuota
metadata:
name: gpu-quota
namespace: research
spec:
hard:
requests.nvidia.com/gpu: "32"
limits.nvidia.com/gpu: "32"
Expected Outcomes: Eliminate resource conflicts, reduce average job wait time by 60%, provide predictable performance for production workloads.
Best Practice 3: Intelligent Data Pipeline Acceleration
Pitfall Addressed: Inefficient Data Pipelines
NStarX Approach: Implement GPU-aware data loading with prefetching, caching, and asynchronous I/O to maximize GPU utilization.
Implementation:
- Use framework-native data loaders (PyTorch DataLoader with num_workers > 0, TensorFlow tf.data)
- Implement multi-threaded data preprocessing on CPU while GPU processes previous batches
- Deploy data caching layers (Redis, object storage) for frequently accessed datasets
- Use mixed-precision training to reduce memory bandwidth requirements
- Implement gradient accumulation to effectively increase batch sizes without additional memory
Technical Approach:
python
# Optimized data loading pattern
dataloader = DataLoader(
dataset,
batch_size=256,
num_workers=8, # Parallel data loading
pin_memory=True, # Faster GPU transfer
prefetch_factor=4, # Prefetch batches
persistent_workers=True # Avoid worker restart overhead
)
# Gradient accumulation for effective larger batches
accumulation_steps = 4
for i, (inputs, labels) in enumerate(dataloader):
outputs = model(inputs)
loss = criterion(outputs, labels) / accumulation_steps
loss.backward()
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
Expected Outcomes: Increase GPU utilization from typical 40-60% to 85-95%, reduce training time by 30-40%.
Best Practice 4: Enterprise Checkpointing Framework
Pitfall Addressed: Missing Checkpointing Strategy
NStarX Approach: Standardize on frequent, incremental checkpointing with automated restart capabilities.
Implementation:
- Checkpoint every N iterations (typically every 100-500 iterations for large models)
- Use asynchronous checkpointing to avoid blocking training progress
- Store checkpoints in high-performance object storage with versioning enabled
- Implement automatic resume from last successful checkpoint on job failure
- Use checkpoint sharding for large models to parallelize save/load operations
Technical Framework:
python
# Robust checkpointing implementation
class CheckpointManager:
def __init__(self, checkpoint_dir, checkpoint_frequency=500):
self.checkpoint_dir = checkpoint_dir
self.frequency = checkpoint_frequency
def save_checkpoint(self, iteration, model, optimizer, scheduler):
checkpoint = {
'iteration': iteration,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'timestamp': datetime.now().isoformat()
}
# Asynchronous save to avoid blocking
checkpoint_path = f"{self.checkpoint_dir}/checkpoint_{iteration}.pt"
torch.save(checkpoint, checkpoint_path)
# Upload to object storage for durability
upload_to_s3(checkpoint_path, f"s3://checkpoints/{checkpoint_path}")
def load_latest_checkpoint(self):
# Find latest checkpoint from object storage
checkpoints = list_s3_objects("s3://checkpoints/")
if checkpoints:
latest = max(checkpoints, key=lambda x: x['LastModified'])
return download_and_load(latest['Key'])
return None
Expected Outcomes: Enable use of 70-90% cheaper spot instances, reduce wasted computation from failures by 90%, improve overall cost efficiency by 50-65%.
Best Practice 5: Predictive Autoscaling Engine
Pitfall Addressed: Static Capacity Allocation
NStarX Approach: Deploy ML-powered predictive scaling that forecasts demand and provisions capacity proactively.
Implementation:
- Collect historical metrics on job submissions, queue depths, and resource utilization
- Train time-series forecasting models (ARIMA, Prophet, LSTM) on usage patterns
- Generate hourly, daily, and weekly demand forecasts
- Configure autoscaling policies that provision capacity 15-30 minutes before predicted demand
- Implement separate scaling policies for inference (latency-based) and training (queue-based)
Scaling Algorithm:
python
# Predictive scaling logic
def calculate_target_capacity(current_time, queue_metrics, historical_data):
# Forecast next hour demand
predicted_demand = forecast_model.predict(current_time, horizon='1h')
# Current queue backlog
queue_backlog_hours = queue_metrics['pending_gpu_hours']
# Calculate required capacity
base_capacity = predicted_demand * 1.2 # 20% buffer
burst_capacity = min(queue_backlog_hours / 2, max_burst_limit)
target_capacity = base_capacity + burst_capacity
# Cost optimization: prefer spot instances up to 70% of capacity
spot_capacity = target_capacity * 0.7
on_demand_capacity = target_capacity * 0.3
return {
'spot_instances': calculate_instance_count(spot_capacity),
'on_demand_instances': calculate_instance_count(on_demand_capacity)
}
Expected Outcomes: Reduce average queue wait time by 70%, decrease on-demand instance usage by 40%, improve cost efficiency by 35%.
Best Practice 6: FinOps Dashboard and Cost Attribution
Pitfall Addressed: No Cost Visibility, No Capacity Governance
NStarX Approach: Implement comprehensive cost tracking with real-time dashboards and team-level chargeback.
Implementation:
- Tag all GPU resources with project, team, environment, and workload type metadata
- Collect cost and usage metrics hourly into centralized data warehouse
- Build real-time dashboards showing GPU costs by team, project, and workload type
- Generate weekly cost reports with trend analysis and optimization recommendations
- Implement budget alerts when teams approach spending thresholds (80%, 100%, 120%)
- Conduct monthly FinOps reviews with stakeholders to review spending and optimization opportunities
Dashboard Metrics:
- Total GPU spend by team/project (current month, trend)
- Cost per training run, cost per inference request
- GPU utilization rates by team
- Reserved vs. on-demand vs. spot usage breakdown
- Stranded capacity identification (reserved but unused)
- Optimization opportunity quantification
Expected Outcomes: Increase cost awareness driving 25-40% reduction in wasteful spending, enable data-driven capacity planning, improve budget predictability.
Best Practice 7: Standardized ML Platform
Pitfall Addressed: Fragmented Tooling
NStarX Approach: Establish a unified ML platform with standardized frameworks, APIs, and deployment patterns.
Implementation:
- Define supported frameworks (e.g., PyTorch, TensorFlow, JAX) with blessed versions
- Provide standardized Docker base images with optimized libraries and drivers
- Build common libraries for checkpointing, distributed training, and monitoring
- Create self-service APIs for job submission, capacity requests, and resource management
- Implement platform abstractions that hide infrastructure complexity from data scientists
Platform Components:
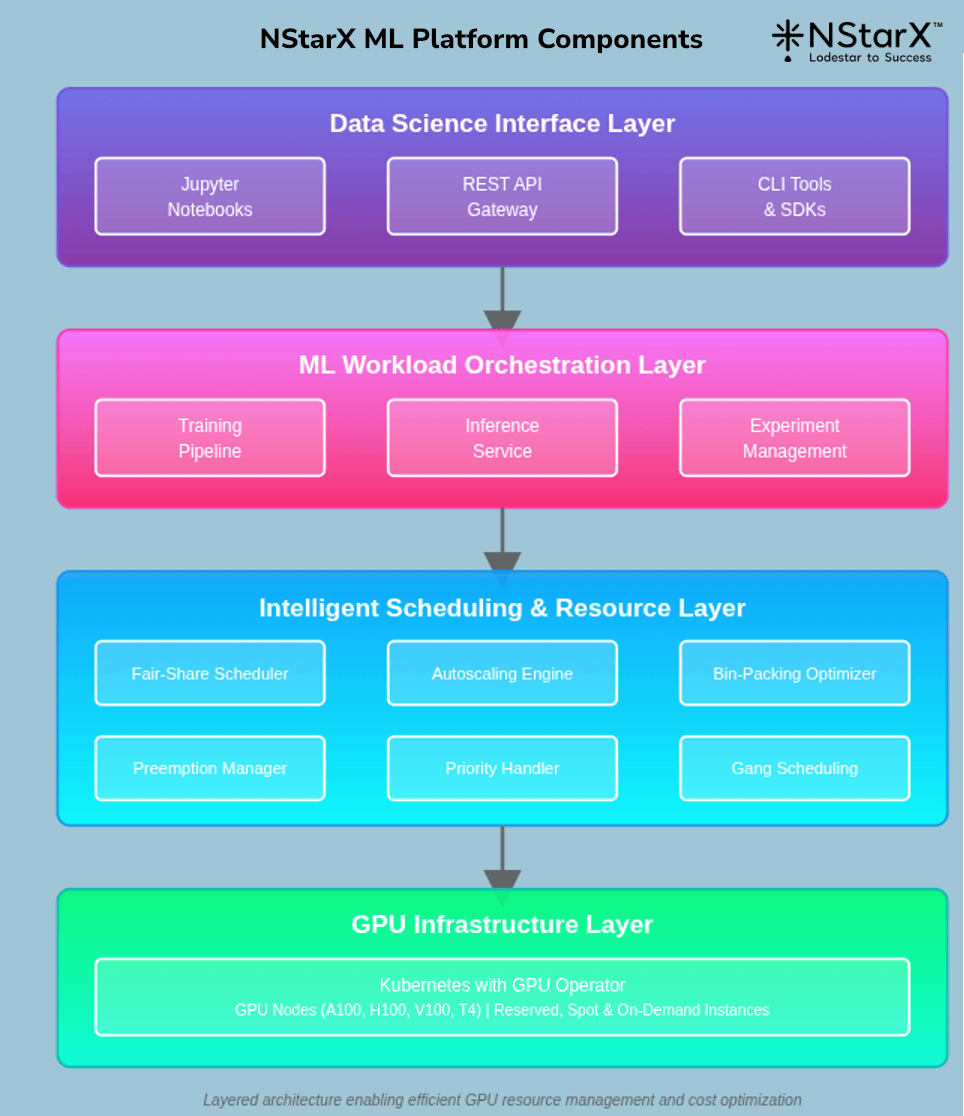
Expected Outcomes: Reduce engineering overhead by 50%, enable resource sharing across teams, accelerate onboarding of new ML engineers, simplify operations.
Best Practice 8: Inference Optimization Pipeline
Pitfall Addressed: Ignoring Inference Optimization
NStarX Approach: Implement systematic inference optimization as a required step before production deployment.
Implementation:
- Model Quantization: Convert FP32 models to INT8 or FP16, reducing memory usage by 50-75%
- Operator Fusion: Use TensorRT or similar tools to fuse operations and eliminate overhead
- Dynamic Batching: Aggregate multiple inference requests into single batches to maximize throughput
- Model Caching: Cache embeddings and intermediate results for common inputs
- KV Cache Optimization: For LLMs, implement efficient key-value caching for attention mechanisms
- Multi-Model Serving: Deploy multiple model replicas across GPU memory to improve utilization
Optimization Workflow:
python
# Inference optimization pipeline
def optimize_for_production(model, validation_data):
# Step 1: Quantization
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
# Step 2: Compile with optimization
optimized_model = torch.compile(
quantized_model,
mode="max-autotune"
)
# Step 3: TensorRT conversion (if available)
if tensorrt_available():
optimized_model = convert_to_tensorrt(
optimized_model,
precision="fp16"
)
# Step 4: Validate accuracy
validate_accuracy(optimized_model, validation_data)
# Step 5: Benchmark throughput
benchmark_results = run_benchmarks(optimized_model)
return optimized_model, benchmark_results
Expected Outcomes: Reduce inference GPU requirements by 60-80%, improve latency by 40-60%, decrease inference costs by 70-85%.
Best Practice 9: Advanced Queue Management
Pitfall Addressed: Queue Starvation
NStarX Approach: Implement sophisticated scheduling with fair-share, backfilling, and SLA-aware policies.
Implementation:
-
- Use weighted fair-share scheduling ensuring each team gets proportional access based on allocation
- Implement backfilling to slot small jobs into gaps between large jobs
- Configure SLA-aware scheduling that prioritizes jobs approaching deadlines
Deploy gang scheduling for multi-GPU jobs ensuring atomic allocation
- Provide queue visualization showing estimated wait times and position
Scheduling Algorithm:
python
# Fair-share scheduling with backfilling
class NStarXScheduler:
def schedule_jobs(self, pending_jobs, available_gpus):
scheduled = []
# Step 1: Priority jobs (SLA-critical)
for job in sorted(pending_jobs, key=lambda j: j.sla_deadline):
if job.gpu_count <= available_gpus:
scheduled.append(job)
available_gpus -= job.gpu_count
# Step 2: Fair-share allocation
team_allocations = calculate_fair_share()
for team, allocation in team_allocations.items():
team_jobs = [j for j in pending_jobs if j.team == team]
team_gpus = min(allocation, available_gpus)
for job in sorted(team_jobs, key=lambda j: j.submit_time):
if job.gpu_count <= team_gpus:
scheduled.append(job)
team_gpus -= job.gpu_count
# Step 3: Backfilling with small jobs
small_jobs = [j for j in pending_jobs
if j.gpu_count <= 4 and j.estimated_duration < 3600]
for job in small_jobs:
if job.gpu_count <= available_gpus:
scheduled.append(job)
available_gpus -= job.gpu_count
return scheduled
Expected Outcomes:Improve fairness metrics by 80%, reduce small job wait times by 90%, increase overall cluster utilization by 15-25%.
Best Practice 10: Governance and Approval Framework
Pitfall Addressed: No Capacity Governance
NStarX Approach: Establish clear governance processes for GPU resource allocation and spending.
Implementation:
- Define tiered approval workflows based on resource request size:
- < 10 GPUs: Auto-approved within team quota
- 10-50 GPUs: Requires team lead approval
- 50-200 GPUs: Requires director approval and capacity review
- 200 GPUs: Requires VP approval and formal business case
- Implement quarterly capacity planning cycles where teams submit forecasts
- Conduct monthly capacity review meetings to assess utilization and adjust allocations
- Establish chargeback mechanisms where teams are billed for actual GPU usage
- Create capacity request templates requiring justification, duration, and success metrics
Governance Process:
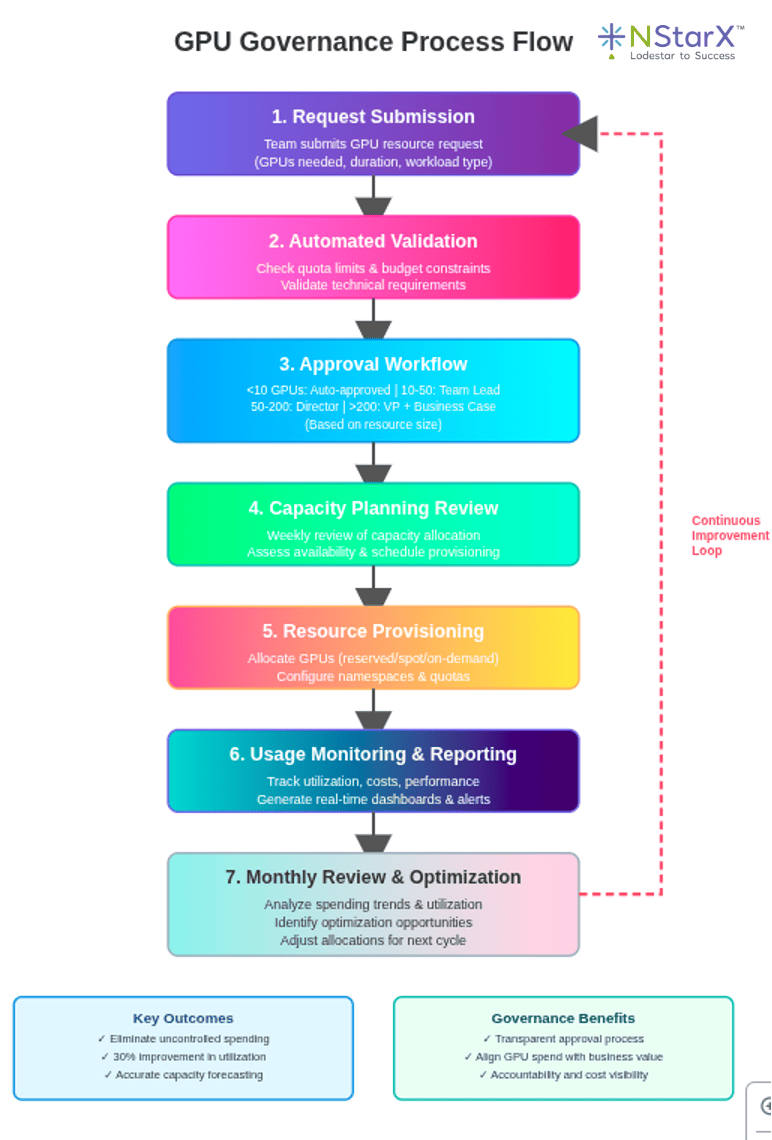
Expected Outcomes: Eliminate uncontrolled spending, improve capacity utilization by 30%, align GPU investments with business priorities, enable accurate forecasting.
H) Reference Architecture for GPU Capacity Management
Architecture Overview
The NStarX GPU management reference architecture implements a multi-layered approach that separates concerns while enabling end-to-end optimization.
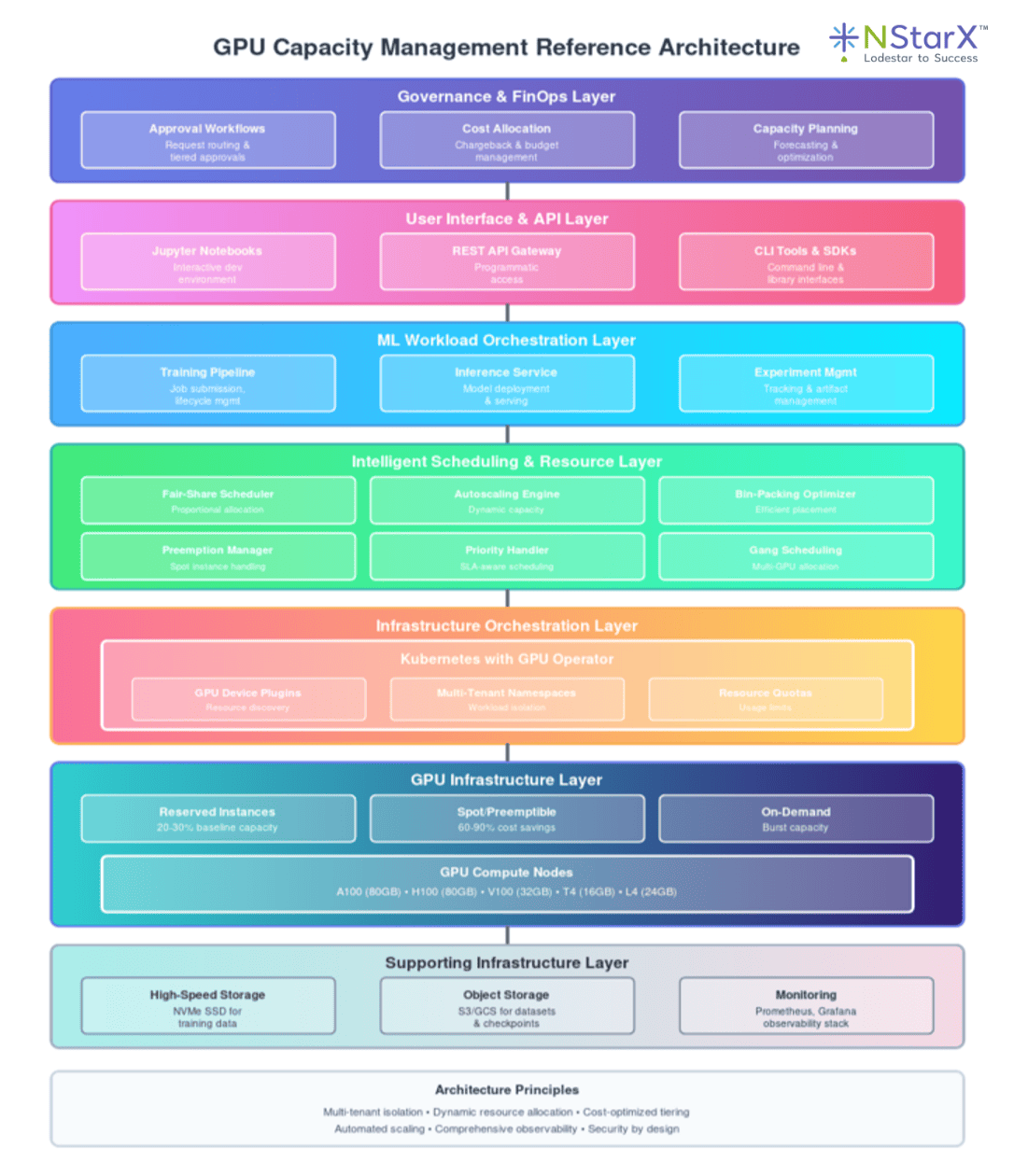
Component Descriptions
Governance & FinOps Layer: Implements approval workflows, cost allocation, budget management, and capacity planning. Integrates with cloud provider cost management APIs and internal financial systems.
User Interface & API Layer: Provides multiple interfaces for different user personas. Data scientists use Jupyter notebooks, ML engineers use REST APIs, and power users leverage CLI tools. All interfaces enforce consistent authentication, authorization, and resource quotas.
ML Workload Orchestration Layer: Manages the lifecycle of training jobs, inference services, and experiments. Handles job submission, dependency management, artifact tracking, and results storage. Integrates with MLOps platforms like MLflow or Kubeflow.
Intelligent Scheduling & Resource Layer: The brain of the system, implementing advanced scheduling algorithms, autoscaling logic, bin-packing optimization, and preemption policies. Continuously optimizes resource allocation based on priorities, SLAs, and costs.
Infrastructure Orchestration Layer: Kubernetes provides the foundation with GPU operator extensions enabling GPU resource management, namespace isolation, and quota enforcement. Implements pod security policies and network segmentation.
GPU Infrastructure Layer: The physical and virtual GPU resources organized into three tiers (reserved, spot, on-demand). Supports multiple GPU types optimized for different workload characteristics.
Supporting Infrastructure Layer: High-speed NVMe storage for training data, object storage for datasets and checkpoints, and comprehensive monitoring infrastructure tracking both infrastructure and application metrics.
Data Flow Example: Training Job Submission
- Submission: User submits training job via API specifying GPU requirements, priority, and deadline
- Validation: System validates request against team quotas and budget constraints
- Approval: If required, routes to appropriate approver based on resource size
- Scheduling: Scheduler evaluates pending queue and available capacity
- Bin-Packing: Optimizer determines optimal placement considering GPU memory, network topology
- Provisioning: If needed, autoscaler provisions additional capacity (spot preferred)
- Execution: Kubernetes launches pods on selected nodes with GPU allocation
- Execution: Kubernetes launches pods on selected nodes with GPU allocation
- Monitoring: System tracks GPU utilization, costs, and job progress
- Checkpointing: Regular checkpoints saved to object storage
- Completion: Results stored, resources released, costs attributed to team
Multi-Cloud Integration
The architecture supports multi-cloud deployments to optimize for availability and cost:
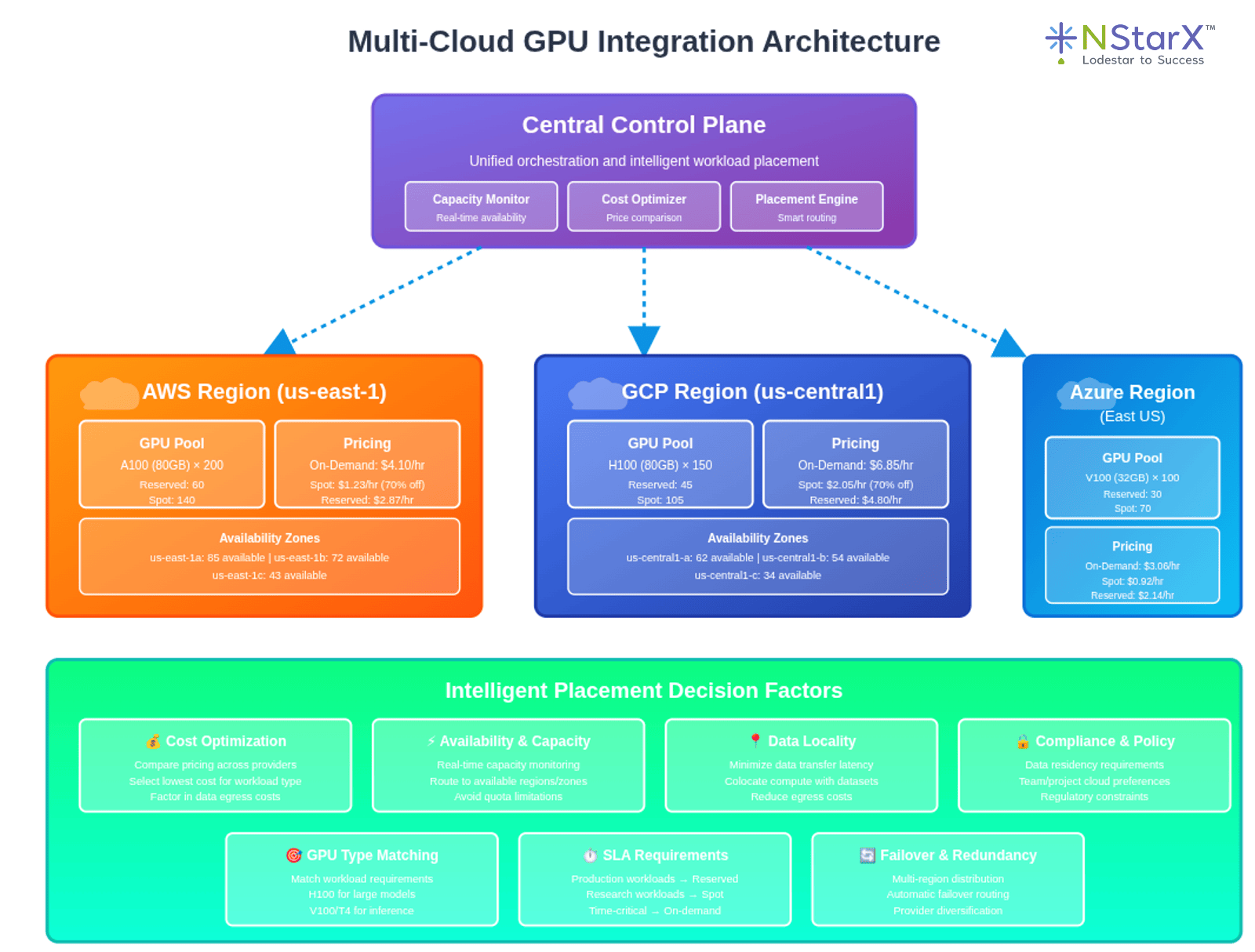
Central control plane makes placement decisions based on:
- Current availability across regions and providers
- Relative pricing for required GPU types
- Data locality and egress costs
- Team preferences and compliance requirements
Security Architecture
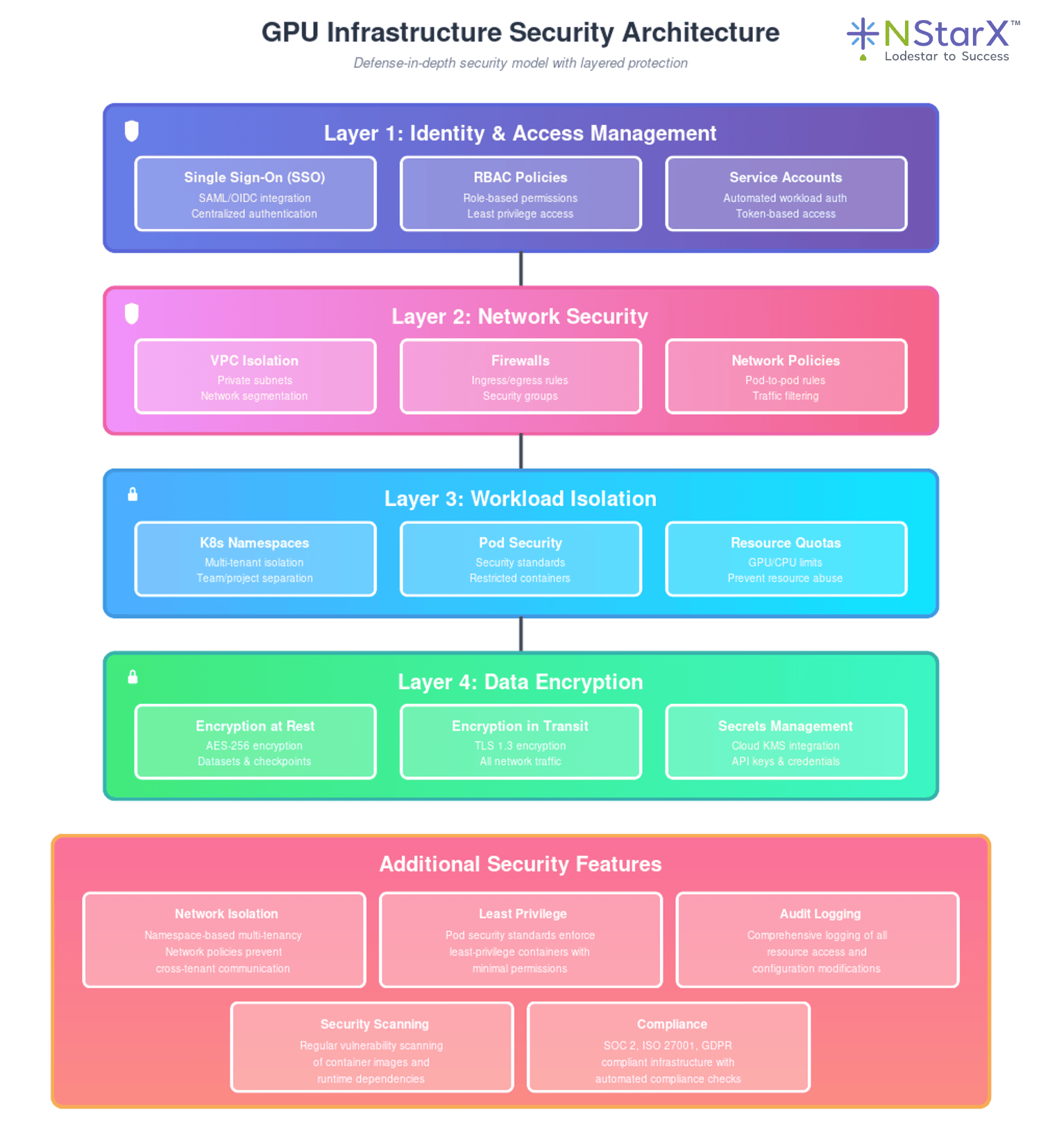
Security Features:
- Namespace-based multi-tenancy with network policies preventing cross-tenant communication
- Pod security standards enforcing least-privilege containers
- Secrets management using cloud provider KMS integration
- Encrypted storage for datasets and checkpoints
- Audit logging of all resource access and modifications
- Regular security scanning of container images and dependencies
I) Future Considerations for GPU and Cost Control
1. Heterogeneous GPU Architectures
Future AI workloads will leverage increasingly diverse GPU types optimized for specific tasks. Organizations must plan for:
Specialized Accelerators: Integration of domain-specific accelerators like Google TPUs, AWS Trainium/Inferentia, and emerging AI chips from startups. Each offers unique price-performance characteristics requiring sophisticated workload-to-hardware mapping.
GPU Disaggregation: Technologies like NVIDIA Grace Hopper superchips blur traditional boundaries between CPU and GPU memory. Future capacity planning must account for unified memory architectures and their implications for workload placement.
Recommendation: Build hardware abstraction layers that allow workload definitions to specify performance requirements rather than specific GPU models. This enables automatic mapping to optimal available hardware as the landscape evolves.
2. Carbon-Aware Computing
Environmental sustainability will become a critical dimension of GPU capacity planning alongside cost and performance.
Carbon-Aware Scheduling: Schedule flexible training jobs during periods of high renewable energy availability. Some cloud regions offer carbon intensity APIs enabling real-time optimization for minimal environmental impact.
Datacenter Selection: Choose regions and availability zones based on their renewable energy mix. Training jobs that can tolerate higher latency might route to regions with lower carbon intensity.
Efficiency Metrics: Track and optimize not just cost per training run, but energy consumption and carbon emissions per model trained.
Recommendation: Integrate carbon metrics into capacity planning tools. Set organizational carbon budgets alongside financial budgets, and optimize for both constraints simultaneously.
3. Federated Learning and Edge Deployment
AI workloads increasingly span cloud datacenters and edge devices, requiring new capacity planning paradigms.
Hybrid Cloud-Edge Orchestration: Coordinate training across centralized GPU clusters and distributed edge devices. Manage bandwidth constraints, intermittent connectivity, and heterogeneous compute capabilities.
Privacy-Preserving Compute: Federated learning keeps data decentralized, requiring GPU capacity planning across distributed participants rather than centralized clusters.
Recommendation: Extend capacity planning tools to model distributed computing environments. Account for network bandwidth as a first-class resource constraint alongside GPU availability.
4. Quantum-Classical Hybrid Systems
As quantum computing matures, hybrid workflows combining classical GPU computation with quantum processing will emerge.
Resource Orchestration: Schedule workflows that alternate between GPU-based classical computation and quantum processing units. Manage queue coordination between radically different computational paradigms.
Cost Modeling: Quantum computing introduces entirely new cost structures (per-shot pricing, error correction overhead) requiring expanded financial models.
Recommendation: Monitor quantum computing developments and begin modeling hybrid workflow economics. Early planning will provide competitive advantages as these technologies mature.
5. Neuromorphic and Biological Computing
Emerging neuromorphic processors and bio-computing approaches may complement or replace GPUs for certain AI workloads.
Technology Diversification: Organizations may operate portfolios including traditional GPUs, neuromorphic chips, and potentially bio-computing substrates, each optimal for different problem classes.
Workload Classification: Develop sophisticated understanding of which workload characteristics benefit from which computing paradigms.
Recommendation: Maintain technology flexibility in capacity planning tools and architecture. Avoid over-optimization for current GPU-centric world as the landscape may shift dramatically.
6. Advanced Optimization Techniques
Emerging model architectures and training techniques will reshape resource requirements.
Sparse Models: Mixture-of-Experts and other sparse architectures activate only subsets of parameters per inference, dramatically changing GPU memory and compute profiles.
Neural Architecture Search: Automated NAS workloads generate thousands of candidate architectures requiring massive but highly parallel GPU capacity.
Few-Shot and Zero-Shot Learning: Techniques reducing training data requirements may shift GPU demand from training to sophisticated inference pipelines.
Recommendation: Build flexible capacity planning that accommodates workload diversity. Avoid assuming all AI workloads follow current training-heavy patterns.
7. Regulatory and Compliance Evolution
AI governance frameworks will increasingly impact GPU capacity planning.
Compute Auditing: Regulations may require tracking and reporting GPU usage for specific model types, particularly for powerful foundation models.
Geographic Restrictions: Data residency and sovereignty requirements may constrain where certain workloads can execute, fragmenting global GPU capacity.
Transparency Requirements: Organizations may need to document and justify resource allocation decisions for regulated AI applications.
Recommendation: Build compliance tracking into GPU management platforms from the start. Implement comprehensive audit trails for all capacity decisions and resource allocations.
8. Continuous Learning and Deployment
The shift toward continuously learning production models will fundamentally change capacity planning.
Always-On Training: Models that continuously learn from production data require persistent GPU allocation, eliminating the traditional train-deploy-serve lifecycle distinction.
A/B Testing at Scale: Organizations will run dozens of model variants simultaneously in production, each requiring dedicated GPU capacity for continuous fine-tuning.
Recommendation: Design capacity planning for steady-state consumption rather than batch-oriented workloads. Implement sophisticated traffic splitting and gradual rollout capabilities.
9. Economic Model Evolution
GPU pricing structures and acquisition models will continue evolving.
Serverless GPU Functions: Pay-per-millisecond GPU execution for inference workloads, requiring entirely new cost modeling approaches.
GPU-as-a-Service: Managed ML platforms increasingly abstract GPU management entirely, shifting planning from infrastructure to service consumption patterns.
Fractional GPU Ownership: Tokenization or fractional ownership models may enable new capacity acquisition strategies.
Recommendation: Regularly reassess GPU acquisition strategies. The optimal mix of owned, reserved, and on-demand capacity will shift as markets evolve.
10. Organizational Learning and Skill Development
Long-term success requires continuous capability building.
Platform Teams: Invest in dedicated platform engineering teams with deep GPU optimization expertise. This expertise becomes a lasting competitive advantage.
Community of Practice: Foster knowledge sharing across ML teams regarding GPU best practices, optimization techniques, and cost management.
Vendor Relationships: Build strategic partnerships with GPU vendors, cloud providers, and specialized AI infrastructure companies for early access to new capabilities and optimization guidance.
Recommendation: Treat GPU management expertise as a strategic capability requiring ongoing investment, not merely an operational concern. Organizations that master GPU economics will have significant advantages in AI-driven markets.
J) Conclusion
GPU capacity planning and cost control represent one of the most critical operational challenges facing organizations deploying AI at scale. The unique characteristics of GPU economics—high unit costs, binary utilization efficiency, supply constraints, and workload unpredictability—create a perfect storm where poor planning results in either crippling resource shortages or massive financial waste.
The emergence of generative AI and agentic systems has amplified these challenges exponentially. Training frontier models requires thousands of GPUs for months. Deploying production inference services consumes resources at scales previously unimaginable. Research exploration demands flexibility that conflicts with the long-term commitments required for cost optimization. These tensions guarantee that stranded GPU spend and failed reservations will remain persistent risks without systematic approaches to capacity management.
The path forward requires treating GPU capacity planning as a strategic capability, not an operational afterthought. Organizations must implement comprehensive workload profiling to understand actual resource consumption patterns. They must deploy intelligent autoscaling that balances cost, performance, and availability across multiple objectives simultaneously. Sophisticated queueing and scheduling systems ensure fair resource allocation while maximizing utilization. Bin-packing optimization and preemption mechanisms extract maximum value from every dollar spent on GPU infrastructure.
Most critically, organizations need integrated solutions that span governance, technology, and culture. Financial transparency and cost attribution drive accountability. Standardized platforms enable resource sharing and reduce fragmentation. Robust checkpointing and spot instance integration unlock massive cost savings. Advanced scheduling prevents resource conflicts and queue dysfunction.
The NStarX best practices outlined in this document provide a comprehensive framework addressing the full spectrum of GPU capacity planning challenges. From dynamic capacity rightsizing to inference optimization, from predictive autoscaling to governance frameworks, these practices represent battle-tested approaches to the problems that plague GPU-intensive organizations.
Looking forward, the GPU landscape will continue evolving rapidly. New accelerator types, carbon considerations, federated learning, and continuously learning systems will reshape resource requirements. Organizations that invest now in flexible, sophisticated capacity planning capabilities will adapt successfully to these changes. Those that continue managing GPUs as generic compute resources will face mounting costs, persistent shortages, and inability to compete effectively in AI-driven markets.
The stakes are clear: GPU capacity planning excellence is not optional for organizations with serious AI ambitions. It is the difference between AI initiatives that deliver transformative business value and those that consume budgets while delivering disappointing results. The time to act is now—before stranded spend and failed reservations become existential threats to AI programs.
K) References
- NVIDIA Corporation. “NVIDIA H100 Tensor Core GPU Architecture.” NVIDIA Technical Documentation. https://www.nvidia.com/en-us/data-center/h100/
- Chowdhery, A., et al. “PaLM: Scaling Language Modeling with Pathways.” Journal of Machine Learning Research, 2023. https://arxiv.org/abs/2204.02311
- Amazon Web Services. “Amazon EC2 P5 Instances.” AWS Documentation. https://aws.amazon.com/ec2/instance-types/p5/
- Google Cloud. “GPUs on Compute Engine.” Google Cloud Documentation. https://cloud.google.com/compute/docs/gpus
- Microsoft Azure. “GPU Optimized Virtual Machine Sizes.” Azure Documentation. https://learn.microsoft.com/en-us/azure/virtual-machines/sizes-gpu
- Kubernetes. “Schedule GPUs.” Kubernetes Documentation. https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
- NVIDIA. “GPU Operator.” NVIDIA Cloud Native Technologies. https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/
- MLPerf. “MLPerf Training Benchmark Results.” MLCommons. https://mlcommons.org/benchmarks/training/
- Ray Project. “Ray: A Framework for Distributed Applications.” Ray Documentation. https://docs.ray.io/
- Vaswani, A., et al. “Attention Is All You Need.” Advances in Neural Information Processing Systems, 2017. https://arxiv.org/abs/1706.03762
- Brown, T., et al. “Language Models are Few-Shot Learners.” NeurIPS, 2020. https://arxiv.org/abs/2005.14165
- Shoeybi, M., et al. “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.” arXiv, 2019. https://arxiv.org/abs/1909.08053
- Apache. “Apache Airflow Documentation.” Apache Software Foundation. https://airflow.apache.org/docs/
- Kubernetes. “Horizontal Pod Autoscaling.” Kubernetes Documentation. https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
- NVIDIA. “Multi-Instance GPU (MIG) User Guide.” NVIDIA Documentation. https://docs.nvidia.com/datacenter/tesla/mig-user-guide/
- Paszke, A., et al. “PyTorch: An Imperative Style, High-Performance Deep Learning Library.” NeurIPS, 2019. https://arxiv.org/abs/1912.01703
- Abadi, M., et al. “TensorFlow: A System for Large-Scale Machine Learning.” OSDI, 2016. https://www.usenix.org/conference/osdi16/technical-sessions/presentation/abadi
- FinOps Foundation. “FinOps Framework.” Linux Foundation. https://www.finops.org/framework/
- Cloud Carbon Footprint. “Cloud Carbon Footprint Methodology.” Cloud Carbon Footprint Project. https://www.cloudcarbonfootprint.org/docs/methodology
- Narayanan, D., et al. “PipeDream: Generalized Pipeline Parallelism for DNN Training.” SOSP, 2019. https://arxiv.org/abs/1806.03377
- Rajbhandari, S., et al. “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models.” SC20, 2020. https://arxiv.org/abs/1910.02054
- NVIDIA. “TensorRT Documentation.” NVIDIA Developer. https://developer.nvidia.com/tensorrt
- Hugging Face. “Optimum: Hardware Optimization Tools.” Hugging Face Documentation. https://huggingface.co/docs/optimum/
- Zheng, L., et al. “Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning.” OSDI, 2022. https://arxiv.org/abs/2201.12023
- Prometheus. “Prometheus Monitoring System.” Prometheus Documentation. https://prometheus.io/docs/
- Kubeflow. “Kubeflow: The ML Toolkit for Kubernetes.” Kubeflow Documentation. https://www.kubeflow.org/docs/
- MLflow. “MLflow: An Open Source Platform for the Machine Learning Lifecycle.” MLflow Documentation. https://mlflow.org/docs/latest/index.html
- Zaharia, M., et al. “Apache Spark: A Unified Engine for Big Data Processing.” Communications of the ACM, 2016. https://spark.apache.org/research.html
- NVIDIA. “RAPIDS: GPU-Accelerated Data Science.” NVIDIA RAPIDS. https://rapids.ai/
- Google. “Vertex AI Documentation.” Google Cloud. https://cloud.google.com/vertex-ai/docs