1. The Honeymoon Phase is Over
The initial excitement around large language models (LLMs) and generative AI has matured into a more sobering reality. What began as dazzling demonstrations and proof-of-concepts in boardrooms worldwide has collided with the harsh constraints of production environments. The gap between a working prototype and a reliable, scalable production system has never been more apparent.
Organizations rushed to experiment with LLMs, captivated by their capabilities. ChatGPT crossed 200 million monthly users, and enterprises scrambled to integrate similar capabilities into their operations. However, as the dust settles in 2025, we’re witnessing a critical inflection point: the difference between those who can successfully operationalize LLMs and those who cannot.
The honeymoon phase characterized by uncritical enthusiasm has given way to the hard work of engineering discipline. Companies are discovering that deploying an LLM in production is fundamentally different from running a successful POC. It’s not just about getting a model to work—it’s about ensuring it works reliably, cost-effectively, and safely at scale, day after day.
2. The Reality Check: POC Statistics and Success Rates
The Sobering Numbers
The statistics paint a stark picture of the current landscape:
Recent research reveals that 42% of companies now abandon the majority of their AI initiatives before reaching production—a dramatic surge from just 17% the previous year. This represents more than a statistical anomaly; it signals a fundamental disconnect between AI promise and implementation reality.
When examining enterprise-grade systems, the numbers become even more concerning: 60% of organizations evaluated such tools, but only 20% reached pilot stage and just 5% reached production. Meanwhile, generic LLM chatbots show high pilot-to-implementation rates of approximately 83%, but this masks deeper splits in perceived value.
According to industry analysis, while 67% of organizations use generative AI products that rely on LLMs, only 23% of respondents planned to deploy commercial models or have already done so as of 2023. Furthermore, Gartner predicts that through 2025, at least 50% of generative AI projects will be abandoned at the pilot stage due to poor data quality, among other factors.
Perhaps most telling, while 92% of companies plan to increase their AI investments, only 1% of leaders call their companies “mature” on the deployment spectrum.
Real-World Examples of the Divide
The contrast between POC success and production failure manifests across industries:
- Financial Services: When working with real business data used by insurance companies, LLM products show only 22% accuracy, dropping to zero when processing mid and expert-level requests.
- Enterprise Tools: A corporate lawyer at a mid-sized firm reported that her organization invested $50,000 in a specialized contract analysis tool, yet she consistently defaulted to ChatGPT because the enterprise solution couldn’t iterate or adapt to her specific needs. This pattern suggests that a $20-per-month general-purpose tool often outperforms bespoke enterprise systems costing orders of magnitude more, at least in terms of immediate usability and user satisfaction.
- Code Generation: A large-scale study found that since the rise of AI coding assistants, the amount of code being reverted or modified within two weeks of being written has spiked, projected to double in 2024 compared to pre-AI times. This indicates that AI-generated code is more likely to be wrong or suboptimal, requiring fixes soon after introduction.
- Model Updates Gone Wrong: In April 2025, OpenAI shipped a GPT-4o update that focused too much on short-term feedback and produced overly flattering but disingenuous answers. The incident was caused by a change in the system prompt that led to unintended behavioral effects, demonstrating that even industry leaders struggle with production deployments.
3. Top 5 Challenges: Production Reality vs. POC Fantasy
Challenge 1: Cost Unpredictability and Runaway Spending
- The POC Illusion: During proof-of-concept phases, token costs seem manageable. A few hundred dollars covers thousands of test queries.
- The Production Reality: One CIO noted,”what I spent in 2023 I now spend in a week.” Enterprise leaders expect an average of approximately 75% growth in LLM spending over the next year.ChatGPT’s daily operational cost is estimated at around $700,000, highlighting the scale challenge.
- Real-World Impact: Cost becomes the hidden bottleneck. Without proper routing strategies and optimization, inference costs can spiral out of control as usage scales. Organizations discover that their initial budget projections were off by orders of magnitude.
Challenge 2: Latency and Performance at Scale
- The POC Illusion: Demo environments with minimal concurrent users show impressive response times.
- The Production Reality: LLMs demand substantial memory due to their processing of vast amounts of information, posing difficulties when attempting to deploy on memory-constrained systems. Scalability challenges arise because model parallelism efficiency varies—it excels within a single node but can hamper performance across nodes due to increased inter-machine communication overhead.
- Real-World Impact: Time To First Token (TTFT), or how quickly users start seeing output, becomes critical. Low waiting times for responses are essential in real-time interactions. What worked with 10 test users becomes unusable with 10,000 production users.
Challenge 3: Data Quality and Context Limitations
- The POC Illusion: Small, curated datasets produce impressive results during testing.
- The Production Reality: Poor data quality can introduce noise, biases, and inaccuracies, leading to critical issues. For DACH region SMEs and other enterprises, the data quality challenge extends beyond technical considerations to encompass governance, privacy, and compliance requirements that are particularly stringent in regulated markets.
- Real-World Impact: Organizations that skip or minimize data preparation inevitably encounter problems during scaling, leading to project abandonment or significant rework—outcomes that enterprises can ill afford.
Challenge 4: Hallucinations and Output Reliability
- The POC Illusion: With careful prompt engineering, POCs demonstrate high accuracy on controlled test cases.
- The Production Reality: Hallucinations are a real problem when working with LLMs, and inaccuracies can lead to misinformation, affecting business decisions and customer trust. Retrieval-augmented generation (RAG), which combines search with generation to ground outputs in real data, has become a common approach. It helps reduce hallucinations but doesn’t eliminate them.
- Real-World Impact: A single hallucination in a customer-facing application can damage brand reputation. In regulated industries, inaccurate outputs can have legal and compliance implications.
Challenge 5: Security, Safety, and Compliance
- The POC Illusion: Security considerations are often an afterthought in POC environments.
- The Production Reality: The prototype-to-production gap becomes apparent when someone asks about security, compliance, cost at scale, handling edge cases, and rollback strategies. LLM deployment has specific requirements that most other applications don’t have.
- Real-World Impact: In 2024, Google’s AI tool Gemini faced backlash for generating historically inaccurate images, highlighting the challenges AI faces in balancing diversity with accuracy. Without proper guardrails, production systems remain vulnerable to prompt injection attacks, data leakage, and generating harmful content.
4. NStarX Best Practices: Design Patterns for Production-Ready LLMs
At NStarX, our experience deploying LLMs at scale has taught us that success requires treating these systems with the same rigor as mission-critical infrastructure. Here are the battle-tested design patterns and practices we’ve developed.
Below Figure shows diagrammatically NStarX best practices (Figure 1):
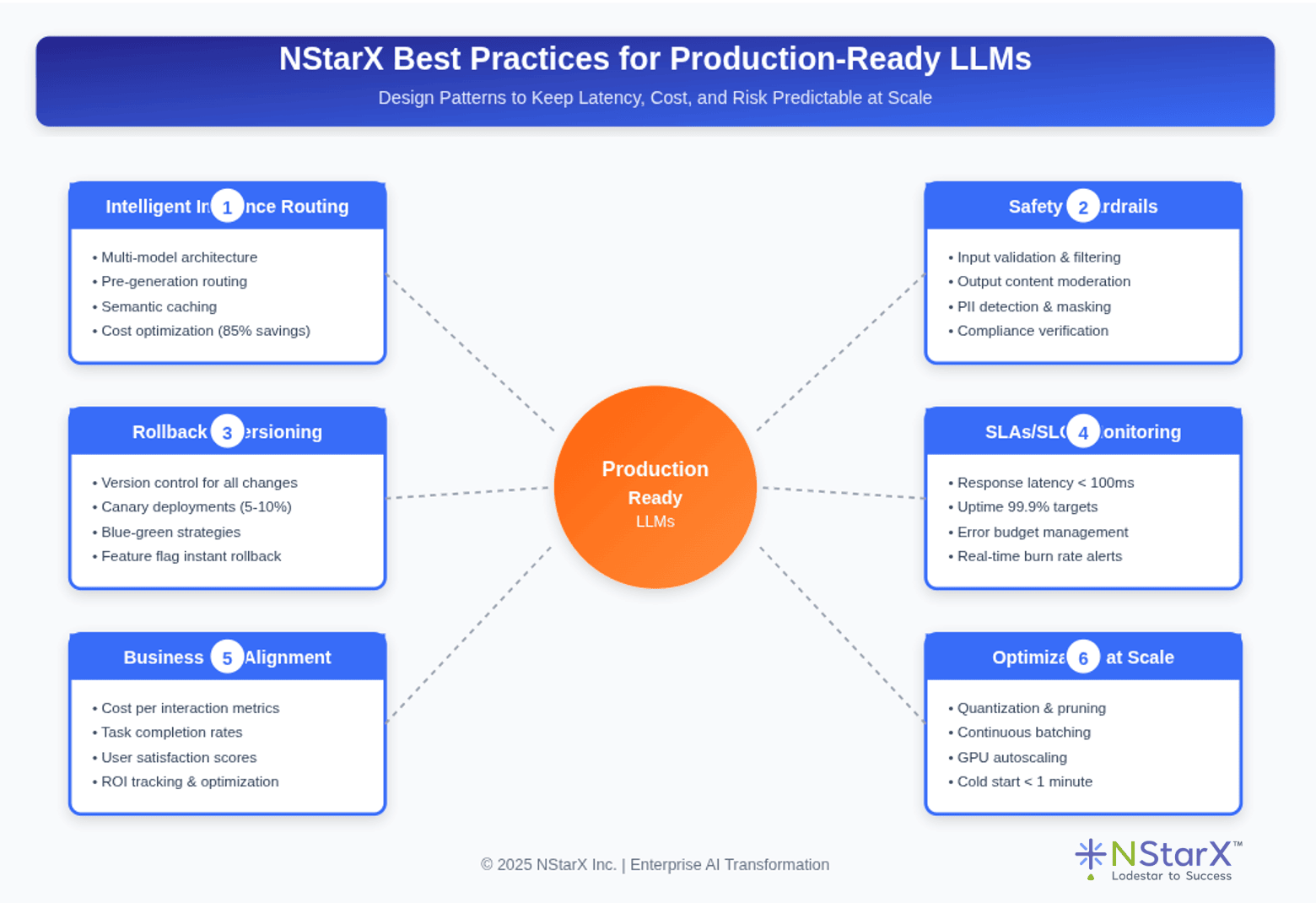 Figure 1: Best Practices for Production Ready LLMs
Figure 1: Best Practices for Production Ready LLMs
A. Intelligent Inference Routing
The Pattern: Rather than sending every request to a single, expensive frontier model, implement intelligent routing that matches queries to the most appropriate and cost-effective model.
Implementation Strategies:
- Pre-Generation Routing: Assess the LLM candidate’s ability to answer a query based on complexity and topic before generation. This minimizes latency by not waiting for the LLM response.
- Multi-Model Architecture: 37% of enterprises now use 5 or more models in production, up from 29% the previous year. Model differentiation by use case has become increasingly pronounced.
- Cost-Performance Optimization: Routers can cut inferencing costs by up to 85% by diverting a subset of queries to smaller, more efficient models. Requests are routed to the smallest viable model that meets quality requirements, with users able to choose between “fast and cheap” or “slow and high quality” responses.
NStarX Implementation:
- Classify queries by complexity using lightweight models
- Route simple queries to efficient models, complex queries to frontier models
- Implement semantic caching to serve similar queries from cache
- Monitor routing decisions and continuously optimize based on performance metrics
B. Comprehensive Safety Guardrails
The Pattern: Implement layered safety controls that filter inputs and outputs without compromising user experience.
Multi-Level Guardrail Strategy:
- Input Guardrails: Input guardrails are applied before your LLM application processes a request. They intercept incoming inputs to determine whether they are safe to proceed with. Key protections include:
- Prompt injection detection
- Jailbreak prevention
- PII identification and masking
- Topic filtering for off-limits subjects
- Output Guardrails: Output guardrails evaluate the generated output for vulnerabilities. If issues are detected, the LLM system typically retries generation a set number of times to produce a safer output. Critical checks include:
- Content moderation for toxicity
- Hallucination detection
- Bias identification
- Compliance verification
NStarX Best Practices:
- Design guardrails asynchronously—send your guardrails along with your main LLM call. If guardrails get triggered you send back their response, otherwise send back the LLM response
- Choose fast, accurate guardrails to minimize latency impact
- Focus on protecting against inputs you never want reaching your LLM and outputs you never want reaching users
- Regularly test and update guardrails based on red team exercises
C. Robust Rollback and Versioning Plans
The Pattern: Treat every model and prompt change as a deployment requiring version control and rollback capability.
Version Control Framework:
- Track Everything: Effective versioning in LLM deployments means tracking not just the model weights, but the entire context of how a model was created, including prompts, training data, hyperparameters, and system configurations.
- Staged Rollouts: Cloud platforms like AWS SageMaker use blue-green deployments that spin up a new model version alongside the old and shift traffic gradually, with automated monitors to trigger rollback if anomalies occur.
- Prompt Management: Treating prompts as fixed code in a source code repository is a reliable way to manage LLM systems. Teams can use version control systems to record changes and maintain a clear history of how prompts have evolved over time.
NStarX Rollback Strategy:
- Implement canary deployments for all model updates (5-10% of traffic initially)
- Define clear rollback triggers (error rate thresholds, latency degradation)
- Maintain at least two production-ready model versions simultaneously
- Use feature flags to enable instant rollback without redeployment
- Document all changes comprehensively for audit trails
D. Rigorous SLAs, SLOs, and Performance Monitoring
The Pattern: Establish clear service level objectives that translate business requirements into measurable technical metrics.
Service Level Framework:
- Define Meaningful SLIs: SLIs are the metrics you’ll measure to determine SLO compliance. For LLM systems, critical SLIs include response latency percentiles, error rates, throughput, and output quality scores.
- Set Realistic SLOs: Establish clear SLAs to define performance expectations. For example, aim for metrics like latency under 100ms, uptime of 99.9%, and accuracy above 95% for critical tasks.
- Balance Business and Technical Constraints: A 99.95% SLO might be perfect for a B2B dashboard, while 99.99% is essential for a payments API. The distinction also strengthens incident response—when you define error budgets and burn rates, you get a crisp, objective signal for when to slow releases.
NStarX Monitoring Stack:
Operational Metrics:
- Latency (response time) measures the time it takes for the LLM to generate a response. Lower latency is crucial for real-time applications.Throughput measures the number of requests that the LLM can handle in a given time period.
- Compute per token or API call measures the computing resources consumed, including GPU memory usage, bandwidth, temperature, storage, and energy consumption.
Quality Metrics:
- Answer correctness, semantic similarity, hallucination detection, task completion, and tool correctness for agent systems
- Factuality assessment using knowledge bases or automated tools
Error Budget Management:
- Track fast burn (2% budget in 1 hour), medium burn (5% budget in 6 hours), and slow burn (10% budget in 3 days) with appropriate escalation procedures
E. Business KPI Alignment
The Pattern:Connect technical metrics to tangible business outcomes to justify investment and guide optimization efforts.
Key Business Metrics:
- Cost Efficiency:
- Cost per successful interaction
- Token cost as percentage of revenue
- Infrastructure cost trends over time
- User Experience:
- Task completion rates
- User satisfaction scores
- Escalation rates to human support
- Business Impact:
- Automation rate (% of queries handled without human intervention)
- Revenue impact of AI-powered features
- Customer retention improvements
NStarX Approach:
- Establish baseline metrics before deployment
- Set quarterly targets aligned with business objectives
- Create executive dashboards showing business impact, not just technical metrics
- Conduct regular ROI assessments to validate continued investment
F. Optimization Techniques for Scale
Memory and Compute Optimization:
Quantization converts model weights to lower precision (from 32-bit to 8-bit) to decrease memory usage and speed up computations. Pruning removes unnecessary parameters, focusing only on those most critical for inference tasks.
Batching Strategies:
Continuous batching allows requests to join an ongoing batch mid-flight, and completed sequences leave immediately, keeping GPUs busy at all times. Prefill and decode mixing handles both new requests and ongoing ones in the same forward pass, maximizing GPU efficiency.
Infrastructure Considerations:
GPU autoscaling is critical for managing AI workloads. During peak traffic, systems can preempt lower-priority batch jobs to reallocate GPUs to higher priority inference jobs. Through optimizations, cold start time can be cut to under 1 minute for most enterprise replicas.
5. The Future: What Lies Ahead
The LLM landscape continues to evolve at breakneck speed, with several key trends shaping the future of production deployments:
Autonomous AI Agents
One of the biggest trends in 2025 is agentic AI—LLM-powered systems that can make decisions, interact with tools, and take actions without constant human input. By 2028, Gartner predicts that 33% of enterprise apps will include autonomous agents, enabling 15% of work decisions to be made automatically.
Production Implications: Agentic systems require even more robust guardrails, monitoring, and rollback capabilities as they have the autonomy to take actions with real-world consequences.
Domain-Specific and Smaller Models
The focus has shifted from general-purpose LLMs to models tailored for specific industries and tasks. Models like BloombergGPT for finance and Med-PaLM for medical data deliver better accuracy and fewer errors because they understand the context of their domain more deeply.
The drive toward smaller, more efficient LLMs continues. DeepSeek recently showcased its DeepSeek-R1 model, a 671-billion-parameter reasoning model that achieved performance similar to high-end models yet with significantly lower inference costs.
Enhanced Reasoning Capabilities
OpenAI’s o1 model is designed for chain-of-thought reasoning. Combined with memory and planning tools, these agents can schedule meetings, analyze reports, or manage workflows with multi-step reasoning.
AI reasoning moves beyond basic understanding into advanced learning and decision making, which requires additional compute for pre-training, post-training and inference.
Regulatory and Compliance Evolution
The EU AI Act took effect in August 2024, with full rollout planned through 2026. Companies are adopting RLHF (Reinforcement Learning from Human Feedback), fairness-aware training, and external audits to reduce risks.
By 2026, over 70% of LLM apps will include bias mitigation and transparency features to ensure responsible AI use, especially crucial in sectors like healthcare where accuracy and fairness are paramount.
Multimodal and Integrated Systems
Future models are no longer limited to text. Multimodal LLMs can handle text, image, audio, and even video, allowing new use cases like analyzing X-rays, generating music, or understanding video scenes and answering questions about them.
Market Growth and Consolidation
The global LLM market was valued at $4.5 billion in 2023 and is projected to reach $82.1 billion by 2033, representing a compound annual growth rate of 33.7%. By 2025, the number of apps utilizing LLMs will surge to 750 million globally.
Model API spending has more than doubled, jumping from $3.5 billion to $8.4 billion. Enterprises are increasing production inference rather than just model development, marking a shift from previous years.
6. Conclusion
The journey from LLM proof-of-concept to production-ready system is fraught with challenges that many organizations underestimate. The statistics are sobering: 42% of AI initiatives are abandoned before reaching production, and only 5% of enterprise-grade LLM systems make it to full deployment. These numbers reflect a fundamental truth—deploying LLMs at scale requires engineering discipline, not just enthusiasm.
Success in production environments demands a shift in mindset. Organizations must move beyond treating LLMs as magical solutions and instead apply rigorous software engineering practices: intelligent inference routing to manage costs, comprehensive safety guardrails to protect users and business, robust rollback mechanisms to handle inevitable issues, and clear SLAs/SLOs tied to business outcomes.
The design patterns we’ve outlined—from multi-model routing strategies to layered guardrail systems, from version-controlled deployments to error budget management—represent hard-won lessons from production deployments. These aren’t theoretical constructs but practical necessities for any organization serious about operationalizing LLMs at scale.
Looking forward, the landscape will continue to evolve rapidly. Autonomous agents, domain-specific models, enhanced reasoning capabilities, and stricter regulatory requirements will reshape how we deploy and manage LLMs. Organizations that establish strong foundations now—with proper monitoring, governance, and optimization practices—will be positioned to adapt and thrive.
The honeymoon with LLMs is indeed over. The real work begins now: building production systems that are reliable, cost-effective, safe, and capable of delivering sustained business value. At NStarX, we believe that with the right design patterns and operational discipline, organizations can bridge the gap between POC promise and production reality.
The future belongs not to those who merely experiment with LLMs, but to those who master the art and science of deploying them at scale.
7. References
- S&P Global. (2025). “AI Implementation Paradox: 42% of Enterprise Projects Fail.” Medium. Retrieved from https://medium.com/@stahl950/the-ai-implementation-paradox-why-42-of-enterprise-projects-fail-despite-record-adoption-107a62c6784a
- MIT NANDA. (2025). “The GenAI Divide: STATE OF AI IN BUSINESS 2025.” MLQ.ai. Retrieved from https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf
- McKinsey & Company. (2025). “AI in the workplace: A report for 2025.” Retrieved from https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/superagency-in-the-workplace-empowering-people-to-unlock-ais-full-potential-at-work
- Menlo Ventures. (2025). “2025 Mid-Year LLM Market Update: Foundation Model Landscape + Economics.” Retrieved from https://menlovc.com/perspective/2025-mid-year-llm-market-update/
- Springs Apps. (2025). “Large Language Model Statistics And Numbers (2025).” Retrieved from https://springsapps.com/knowledge/large-language-model-statistics-and-numbers-2024
- Andreessen Horowitz. (2025). “How 100 Enterprise CIOs Are Building and Buying Gen AI in 2025.” Retrieved from https://a16z.com/ai-enterprise-2025/
- Founders Forum Group. (2025). “AI Statistics 2024–2025: Global Trends, Market Growth & Adoption Data.” Retrieved from https://ff.co/ai-statistics-trends-global-market/
- Deeper Insights. (2025). “The Unspoken Challenges of Large Language Models.” Retrieved from https://deeperinsights.com/ai-blog/the-unspoken-challenges-of-large-language-models/
- Teneo.ai. (2024). “5 biggest challenges with LLMs and how to solve them.” Retrieved from https://www.teneo.ai/blog/5-biggest-challenges-with-llms-and-how-to-solve-them
- A3logics. (2025). “The Challenges of Deploying LLMs.” Retrieved from https://www.a3logics.com/blog/challenges-of-deploying-llms/
- Adnan Masood. (2025). “Deploying LLMs in Production: Lessons from the Trenches.” Medium. Retrieved from https://medium.com/@adnanmasood/deploying-llms-in-production-lessons-from-the-trenches-a742767be721
- Red Hat Developer. (2025). “LLM Semantic Router: Intelligent request routing for large language models.” Retrieved from https://developers.redhat.com/articles/2025/05/20/llm-semantic-router-intelligent-request-routing
- Databricks. (2025). “LLM Inference Performance Engineering: Best Practices.” Retrieved from https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices
- Label Your Data. (2024). “LLM Inference: Techniques for Optimized Deployment in 2025.” Retrieved from https://labelyourdata.com/articles/llm-inference
- IBM Research. (2024). “LLM routing for quality, low-cost responses.” Retrieved from https://research.ibm.com/blog/LLM-routers
- Vamsikd. (2025). “LLM Inference Optimization in Production: A Technical Deep Dive.” Medium. Retrieved from https://medium.com/@vamsikd219/llm-inference-optimization-in-production-a-technical-deep-dive-57eacb81550d
- arXiv. (2025). “Doing More with Less – Implementing Routing Strategies in Large Language Model-Based Systems.” Retrieved from https://arxiv.org/html/2502.00409v2
- Turing. (2025). “LLM Guardrails: A Detailed Guide on Safeguarding LLMs.” Retrieved from https://www.turing.com/resources/implementing-security-guardrails-for-llms
- Software Analyst. (2025). “Securing AI/LLMs in 2025: A Practical Guide.” Retrieved from https://softwareanalyst.substack.com/p/securing-aillms-in-2025-a-practical
- Rui Pedro Moreira. (2025). “Guardrails for LLMs: Pillars, Tools, and Best Practices.” Medium. Retrieved from https://medium.com/@rpml89/guardrails-for-llm-pillars-tools-and-best-practices-db23e6300dde
- Confident AI. (2025). “LLM Guardrails: The Ultimate Guide to Safeguard LLM Systems.” Retrieved from https://www.confident-ai.com/blog/llm-guardrails-the-ultimate-guide-to-safeguard-llm-systems
- ML6. (2024). “The landscape of LLM guardrails: intervention levels and techniques.” Retrieved from https://www.ml6.eu/en/blog/the-landscape-of-llm-guardrails-intervention-levels-and-techniques
- Aparna Dhinakaran. (2024). “Safeguarding LLMs with Guardrails.” Medium. Retrieved from https://medium.com/data-science/safeguarding-llms-with-guardrails-4f5d9f57cff2
- WitnessAI. (2025). “LLM Guardrails: Securing LLMs for Safe AI Deployment.” Retrieved from https://witness.ai/blog/llm-guardrails/
- Palo Alto Networks. (2025). “How Good Are the LLM Guardrails on the Market?” Retrieved from https://unit42.paloaltonetworks.com/comparing-llm-guardrails-across-genai-platforms/
- OpenAI Cookbook. (2025). “How to implement LLM guardrails.” Retrieved from https://cookbook.openai.com/examples/how_to_use_guardrails