2026 Enterprise Strategy Whitepaper: Tokenomics 2.0
The Economics of Enterprise Agentic AI
This whitepaper explores “AI Tokenomics,” a new discipline for managing the unpredictable costs of agentic AI, where complex workflows can amplify token consumption by over 200x. It introduces a comprehensive framework for AI FinOps and token-aware architecture to help enterprises avoid overspending by 8–12x. By implementing proactive governance and optimized inference strategies, organizations can achieve sustainable AI scaling and significant long-term ROI.
Executive Summary: The AI Tokenomics Imperative
Why AI Tokenomics Is the Defining Discipline of the Agentic Era
Enterprise AI is entering a second, more consequential phase. The first phase — deploying AI assistants and copilots — generated predictable, token-bounded costs. The second phase — autonomous agentic AI systems operating workflows without human intervention — is creating a new class of invisible infrastructure cost that enterprises are dramatically underprepared for.
Token consumption is the new infrastructure tax. Just as uncontrolled cloud sprawl blindsided CFOs in 2012–2015, uncontrolled agentic AI spend is becoming the defining financial governance challenge of 2025–2028. The enterprises that master AI Tokenomics — the discipline of modeling, monitoring, and optimizing inference economics at scale — will emerge with structural cost advantages. Those that ignore it will face compounding operational debt that undermines the ROI case for AI entirely.
212x |
8–12x |
95% |
| Avg Token Amplification (Agentic vs. User Input) | Enterprise AI Spend Underforecast at 18 Months | Token Costs Invisible to Standard Monitoring |
40–65% |
<12% |
$4.2B |
| Potential Spend Reduction via Optimal Routing | Enterprises with Active AI FinOps Practice | Expected AI FinOps Market by 2028 |
What This Report Covers
- The mechanics of agentic token amplification — how 200 tokens become 42,000
- CFO frameworks for AI P&L modeling, cost attribution, and chargeback
- CTO architecture blueprints for token-aware, inference-optimized systems
- AI FinOps operating model — people, process, and platform
- Hybrid and sovereign inference economics
- Security, governance, and compliance cost modeling
- 2026–2030 prediction matrix for enterprise AI economics
- NStarX DLNP platform positioning and enterprise engagement model
Section 1: Agentic AI Token Amplification
The Hidden Cost Architecture of Agentic AI
When a knowledge worker asks an AI system to “prepare a competitive analysis of our top five accounts,” they perceive a single request. What they cannot see is the computational iceberg beneath: an orchestrator decomposing the task, three to five sub-agents spawning in parallel, each agent retrieving context through RAG pipelines, a reasoning model constructing multi-step chains of thought, verification loops re-running when confidence thresholds aren’t met, and finally a result aggregator assembling the output. The user sees one answer. The enterprise pays for tens of thousands of tokens it never budgeted.
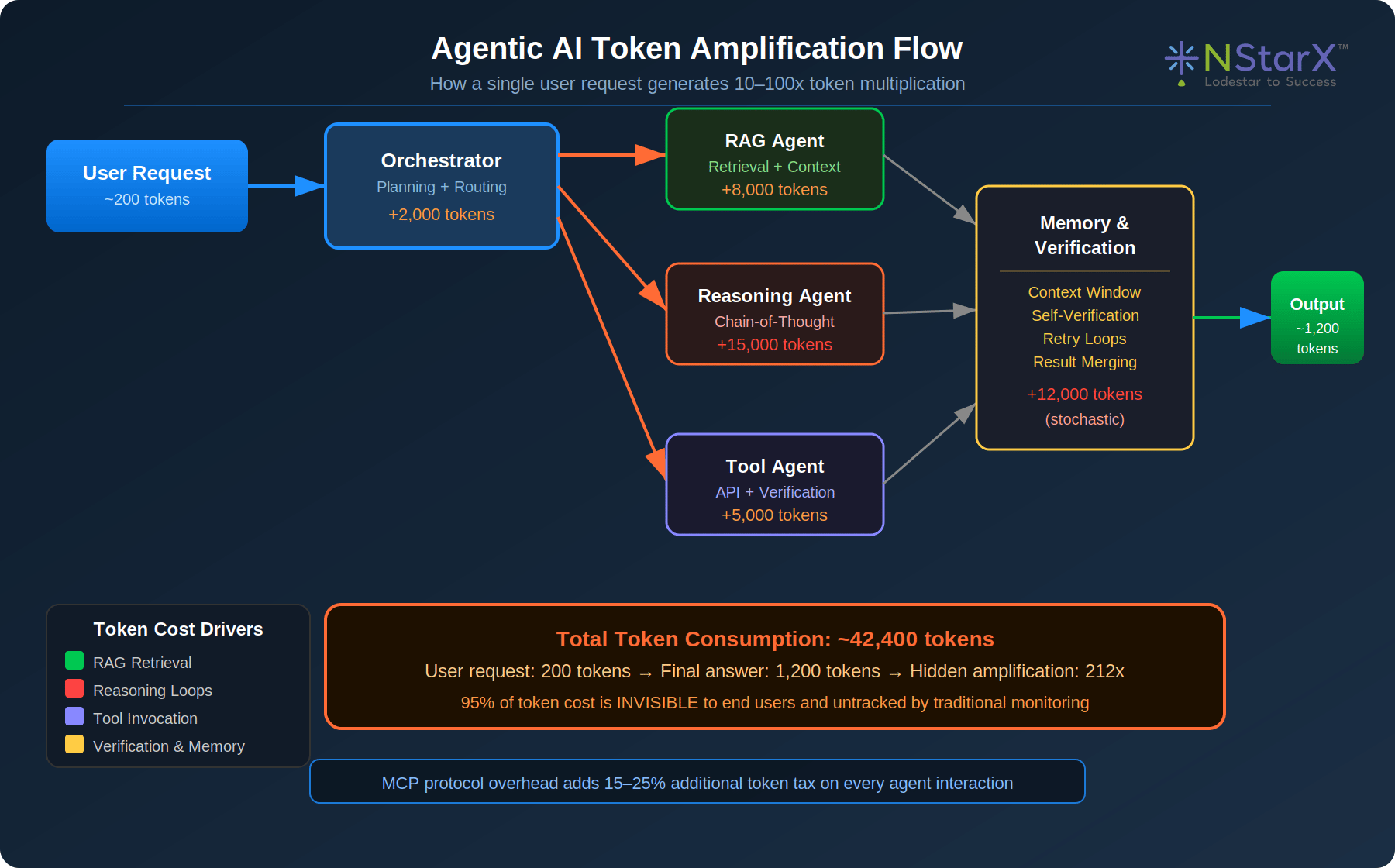
Figure 1: Agentic AI Token Amplification Flow — 200 user tokens become 42,400 total tokens
The Seven Amplification Vectors
1. Orchestration Overhead — Every agentic workflow begins with a planning and routing phase. The orchestrator must parse intent, decompose objectives into sub-tasks, assign agents, and track execution state. This alone consumes 1,500–3,000 tokens per workflow regardless of task complexity — a fixed cost enterprises almost never account for.
2. RAG Retrieval Inflation — Retrieval-Augmented Generation systems inject retrieved document chunks into every agent’s context window. A retrieval query returning five 500-token chunks multiplies context by 2,500 tokens before the reasoning even begins. With multiple retrieval passes across sub-agents, RAG alone can account for 20–40% of total token consumption.
3. Chain-of-Thought Reasoning Explosion — Advanced reasoning models (o3, Claude Sonnet, Gemini 2.0 Pro) generate explicit reasoning traces before producing outputs. A question that takes 800 tokens to answer may require 8,000–20,000 reasoning tokens. These tokens are billed but invisible in most observability stacks because they appear in the thinking trace, not the final response.
4. Self-Verification and Retry Loops — Agentic systems programmed with quality thresholds will re-run reasoning when confidence is low. A 15,000-token reasoning pass that fails a quality check will retry — potentially two or three times. Retry-induced token waste is highly stochastic and nearly impossible to forecast without real-time observability.
5. Multi-Agent Communication Overhead — When agents communicate via A2A protocols and MCP frameworks, each message carries protocol metadata and context serialization overhead. NStarX benchmarks show this adds 15–25% on top of base token consumption across typical enterprise multi-agent workflows.
6. Memory and Context Accumulation — Long-running autonomous agents maintain state across steps. As memory systems accumulate context — previous tool results, intermediate reasoning, retrieved facts — the context window grows with every step. A workflow running 10 steps may present a context 8x larger at step 10 than at step 1.
7. Hallucination-Induced Waste — When AI systems produce incorrect intermediate results, subsequent agents built on those results consume tokens processing flawed inputs. Verification agents that catch and correct these hallucinations consume additional tokens. In regulated industries where correctness is critical, this quality-assurance overhead can reach 25–40% of total token consumption.
| Token Driver | Typical Range | % of Total | Visibility | Control Lever |
|---|---|---|---|---|
| User Input | 50–500 | 0.5–2% | Full | Prompt compression |
| Orchestration | 1,500–3,000 | 4–8% | Low | Workflow decomp optimization |
| RAG Retrieval | 5,000–15,000 | 15–35% | Medium | Chunk sizing, re-rank limits |
| Reasoning Trace | 8,000–20,000 | 20–45% | Very Low | Model selection, depth limits |
| Tool Calls | 2,000–8,000 | 5–20% | Low | API batching, result caching |
| Verification Loops | 3,000–12,000 | 8–25% | Very Low | Confidence thresholds |
| Memory Context | 1,000–10,000 | 3–22% | Low | Context compression, summaries |
| MCP/A2A Overhead | 500–3,000 | 1–8% | None | Protocol optimization |
| Final Output | 500–2,000 | 1–4% | Full | Output length limits |
Section 2: CFO Tokenomics Framework
AI P&L: How CFOs Should Model Agentic AI Economics
The fundamental error in enterprise AI budgeting is treating AI costs as line-item API spend. The real unit of financial accountability is not the token — it is the business outcome. Token costs are a proxy measure, not a governance metric. CFOs who build AI financial governance frameworks around token spend alone will find themselves managing noise rather than signal.
The correct framing is cost-per-business-outcome: the total inference cost required to produce one unit of business value (a completed sales analysis, a resolved support case, a reviewed contract, a closed reconciliation). This metric is accountable, cross-comparable across business units, and directly connectable to ROI models.

Figure 2: CFO AI Cost Attribution Heatmap — Token spend intensity by Business Unit and Workload Type
AI P&L Framework
| P&L Line | Description | Measurement | Owner |
|---|---|---|---|
| AI Revenue Attribution | Revenue attributable to AI-enabled workflows | Pipeline closed / AI-assisted deals | CRO + CFO |
| Inference OPEX | Token consumption costs across all models | Monthly API/GPU spend | AI FinOps Team |
| AI Infrastructure CAPEX | GPU clusters, sovereign inference hardware | Amortized over 3–5 years | CTO + CFO |
| AI Observability Overhead | Telemetry, monitoring, governance tooling | 5–12% of inference spend | Engineering |
| AI Security Overhead | Red team, prompt defense, audit tooling | 3–8% of inference spend | CISO + AI Team |
| AI Governance Overhead | Compliance, audit, governance program costs | 4–10% of inference spend | GRC + Legal |
| Token Waste / Efficiency Loss | Uncached, retry, hallucination-induced tokens | 15–35% of inference spend | AI FinOps |
| AI Human-in-Loop Labor | Review, QA, exception handling by humans | FTE equivalent cost | Operations |
| AI ROI (Net) | Revenue + cost savings minus total AI cost | Net P&L impact | CFO Office |
AI Cost Attribution Model
Enterprise AI costs must be attributed across four dimensions simultaneously to enable meaningful governance: by Business Unit (each BU owns its token budget and chargeback obligation), by Workflow Type (document automation vs. customer agents vs. reasoning carries different cost profiles), by Agent Role (orchestrators, specialists, and verifiers have distinct cost signatures), and by Geography/Jurisdiction (sovereign routing for regulated data adds 20–35% cost premium).
| AI Cost Category | Short-Term Optimization | Medium-Term Strategy | Long-Term Architecture |
|---|---|---|---|
| High-volume simple queries | Cache + local model routing | Semantic cache scaling | Edge inference deployment |
| Complex reasoning workloads | CoT depth limits | Model fine-tuning | Hybrid reasoning layers |
| RAG retrieval costs | Chunk size optimization | Hybrid search + re-rank | Compressed embedding stores |
| Multi-agent workflows | Agent count limits | Workflow decomp optimization | Autonomous cost-aware routing |
| Regulated/sovereign workloads | Jurisdiction tagging | On-prem inference staging | Full sovereign inference |
AI Budgeting Maturity Curve
- Stage 1 — Reactive: Monthly bill review, no attribution, no forecast capability.
- Stage 2 — Aware: Basic spend tracking by team, rough workload categorization.
- Stage 3 — Managed: Workflow-level attribution, chargeback active, anomaly detection.
- Stage 4 — Optimized: Real-time cost governance, cost-per-outcome KPIs, model routing active.
- Stage 5 — Autonomous: AI-predicted cost optimization, self-adjusting model selection, carbon-aware scheduling.
Section 3: CTO Architecture — Token-Aware Engineering
Redesigning Enterprise Architecture for AI Token Economics
The transition from traditional software architecture to AI-native architecture requires a fundamental philosophical shift: inference cost must become a first-class design constraint, not an afterthought. Every architectural decision — from context window sizing to model selection to orchestration topology — has a direct and quantifiable token cost implication.
Token-aware engineering is not about limiting AI capability — it is about deploying that capability at the right cost point for each task. A reasoning frontier model costing $15 per million tokens should never be used for a task a $0.10 per million token local model can perform with equal quality. The architectural patterns that enforce this discipline are the foundation of sustainable AI economics.
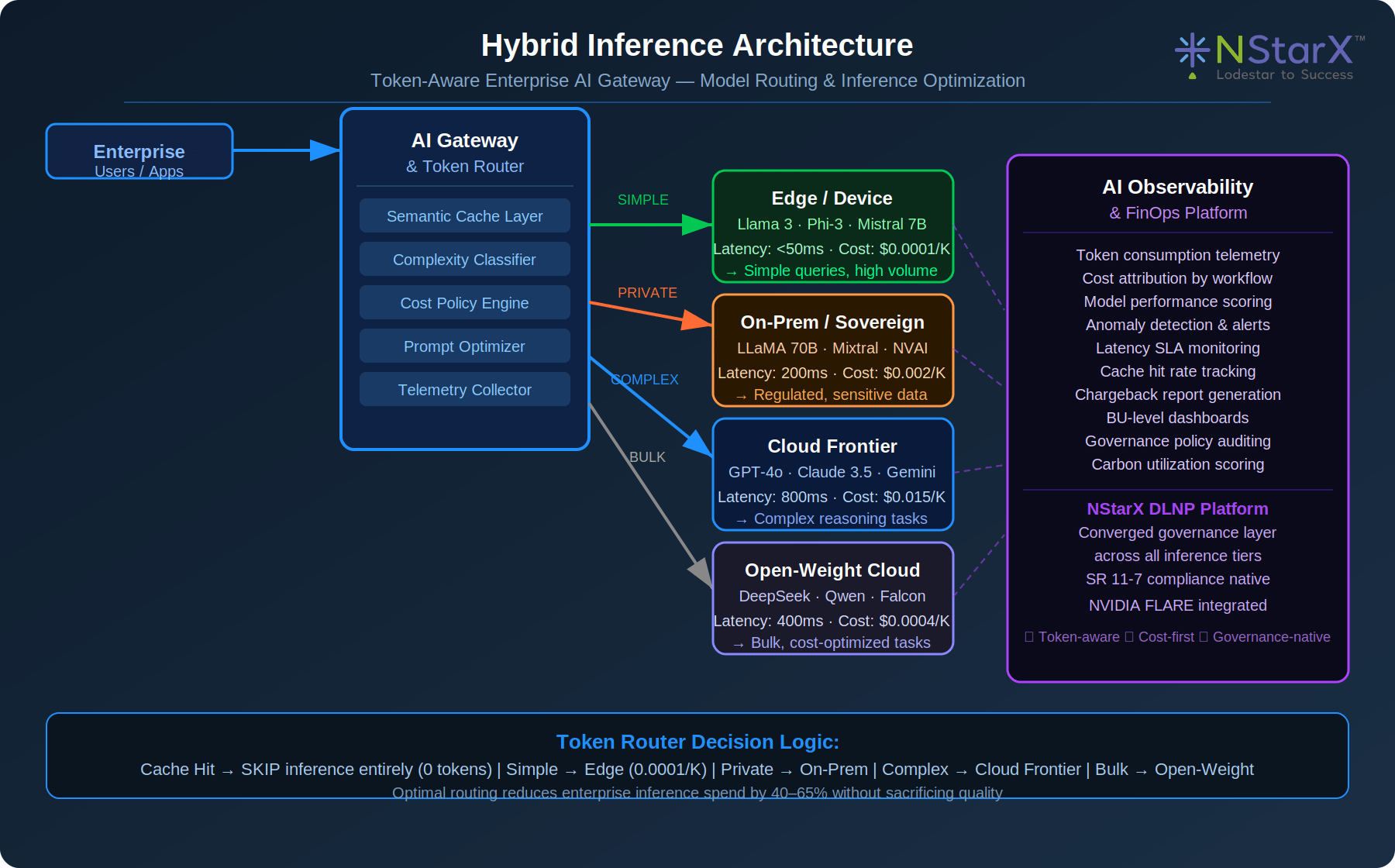
Figure 3: Hybrid Inference Architecture — Enterprise AI Gateway with Token-Aware Model Routing
Core Architectural Patterns
Pattern 1: Cheap-Model-First Routing — All inference requests should begin with the lowest-cost capable model and escalate only when quality thresholds require it. An AI gateway implementing this pattern applies a complexity classifier to incoming requests and routes simple queries to edge or small models, medium-complexity queries to mid-tier models, and only genuinely complex reasoning tasks to frontier models. NStarX implementations demonstrate 40–55% cost reduction with no measurable quality degradation on standard enterprise workflows.
Pattern 2: Semantic Caching Layer — Semantic caching intercepts inference requests before they reach the model and returns cached responses for semantically similar prior queries. Unlike exact-match caching, semantic caching uses embedding similarity to match intent — so “What is our Q3 revenue?” and “Summarize Q3 financial performance?” can return the same cached result. Enterprises with high-volume repetitive queries see cache hit rates of 25–45%, eliminating that fraction of inference costs entirely.
Pattern 3: Context Compression — As agent context windows grow through multi-step workflows, lossless and lossy compression techniques can reduce context size by 30–60% without meaningful accuracy loss. Hierarchical summarization of earlier workflow steps, selective retention of high-signal retrieved chunks, and automatic context pruning policies are production-deployable techniques available today.
Pattern 4: Hybrid Inference Topology — Enterprise inference should be distributed across four tiers: edge inference for low-latency, low-sensitivity queries; on-premises sovereign inference for regulated workloads; cloud open-weight inference for bulk cost-optimized tasks; and cloud frontier inference reserved exclusively for tasks requiring maximum capability. The routing policy between these tiers, enforced by the AI gateway, is the single highest-leverage architectural intervention available to cost-conscious CTOs.
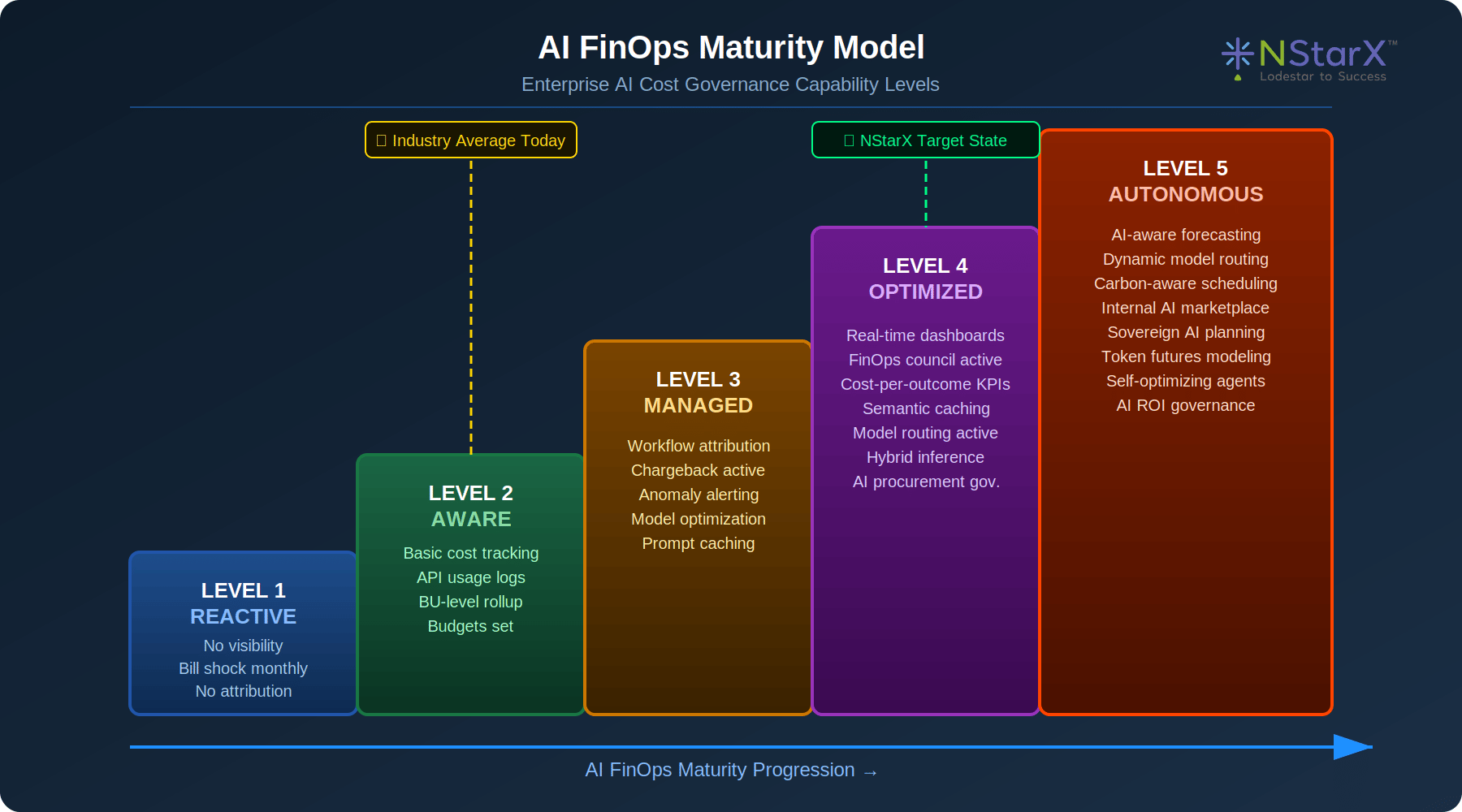
Figure 4: AI FinOps Maturity Model — Five levels from Reactive to Autonomous
Model Economics Comparison
| Model Tier | Example Models | Cost / 1M Tokens | Latency | Best Use Cases |
|---|---|---|---|---|
| Edge / Device | Llama 3 8B, Phi-3, Mistral 7B | $0.05–$0.15 | <50ms | Classification, simple Q&A, extraction |
| Open-Weight Cloud | DeepSeek, Qwen 72B, Falcon | $0.25–$0.80 | 200–400ms | Bulk summarization, routine generation |
| Mid-Tier Cloud | Claude Haiku, GPT-4o Mini | $0.50–$2.00 | 300–600ms | Customer-facing, medium complexity |
| Frontier Cloud | GPT-4o, Claude Sonnet, Gemini Pro | $5–$20 | 600–1,200ms | Complex reasoning, high-stakes decisions |
| Frontier Reasoning | o3, Claude Opus, Gemini Ultra | $15–$75 | 1,000–3,000ms | Strategic analysis, scientific reasoning |
Section 4: The Enterprise AI FinOps Playbook
Building the AI FinOps Operating Model
AI FinOps is the organizational capability to manage AI infrastructure costs with the same rigor applied to cloud spend in the post-2015 era. It is not simply a tooling decision — it is an operating model encompassing people (governance structure and accountability), process (planning, monitoring, and optimization cycles), and platform (telemetry, dashboards, and routing infrastructure).
Unlike traditional cloud FinOps, AI FinOps must contend with fundamentally stochastic cost curves. Cloud compute costs are predictable given resource allocations. Inference costs for agentic systems are not — they depend on model behavior, retrieval quality, reasoning depth, and retry rates in ways that defy static forecasting. AI FinOps practitioners must build probabilistic budgeting models and real-time anomaly detection rather than relying on static allocation frameworks.

Figure 5: AI FinOps Operating Model — People, Process, Platform
AI FinOps Council Structure
| Role | Responsibility | Meeting Cadence |
|---|---|---|
| AI FinOps Council (CIO/CFO/CTO) | Strategic AI spend oversight, budget approvals, governance policy | Bi-weekly |
| BU AI Budget Owners | BU token budget authority, forecast ownership, chargeback approval | Weekly |
| AI FinOps Engineering Team | Telemetry operations, optimization sprints, model routing | Daily (ops) + weekly sprint |
| AI Procurement Officer | Vendor management, contract optimization, API dependency governance | Monthly + as needed |
| AI Security & Compliance | Governance audit, SR 11-7 compliance, prompt defense ops | Weekly |
The AI FinOps Operating Cycle
- Plan (Monthly): Token budget allocation by BU and workload. Forecast based on historical consumption curves and planned workflow expansion. Model selection review against new provider pricing.
- Monitor (Real-time): Token consumption dashboards by workflow and BU. Anomaly detection for spike events. Hallucination waste tracking. Cost-per-outcome trending.
- Optimize (Sprint Cycle): Prompt compression reviews. Cache expansion analysis. Model downgrade candidates identification. Retry loop analysis and circuit breaker implementation.
- Chargeback (Quarterly): BU-level invoice generation from tagged telemetry. Variance analysis against forecast. Incentive structures for BUs that optimize below budget.
- Govern (Ongoing): SR 11-7 compliance audit. Access policy review. Vendor contract renegotiation. API dependency risk assessment.
Critical AI FinOps KPIs
| KPI | Definition | Target | Owner |
|---|---|---|---|
| Cost Per Business Outcome | Total inference cost ÷ completed outcomes | Declining QoQ | CFO + AI Team |
| Token Waste Rate | % of tokens from retries, hallucinations, over-retrieval | <15% | AI FinOps Eng |
| Cache Hit Ratio | % of requests served from semantic cache | >30% | AI Architect |
| Model Utilization Efficiency | Actual tokens ÷ optimal model tokens for task | >85% | AI FinOps Eng |
| BU Budget Adherence | % of BUs within 110% of token budget | >80% | BU Owners |
| Forecast Accuracy (30-day) | Actual vs. forecasted token spend | ±15% | AI FinOps Lead |
| Governance Coverage | % of AI workflows with telemetry attribution | 100% | Engineering |
Section 5: Security, Governance & Compliance Economics
The Hidden Cost of Enterprise AI Governance
Governance is not free. Every security control, compliance requirement, and audit trail imposed on an enterprise AI system carries a direct token and compute cost. The enterprises that ignore this reality and bolt governance onto existing AI systems after deployment consistently face two outcomes: governance systems that fail under production load, or AI systems that become prohibitively expensive due to unplanned governance overhead.
The correct approach is governance-by-design: building security, observability, compliance, and audit capabilities into the AI architecture from inception, with explicit cost budgeting for each governance layer. NStarX’s DLNP Converged Platform and SR 11-7 AI governance baseline implement this model — treating governance infrastructure as a capital investment amortized across AI deployments rather than a per-deployment overhead.
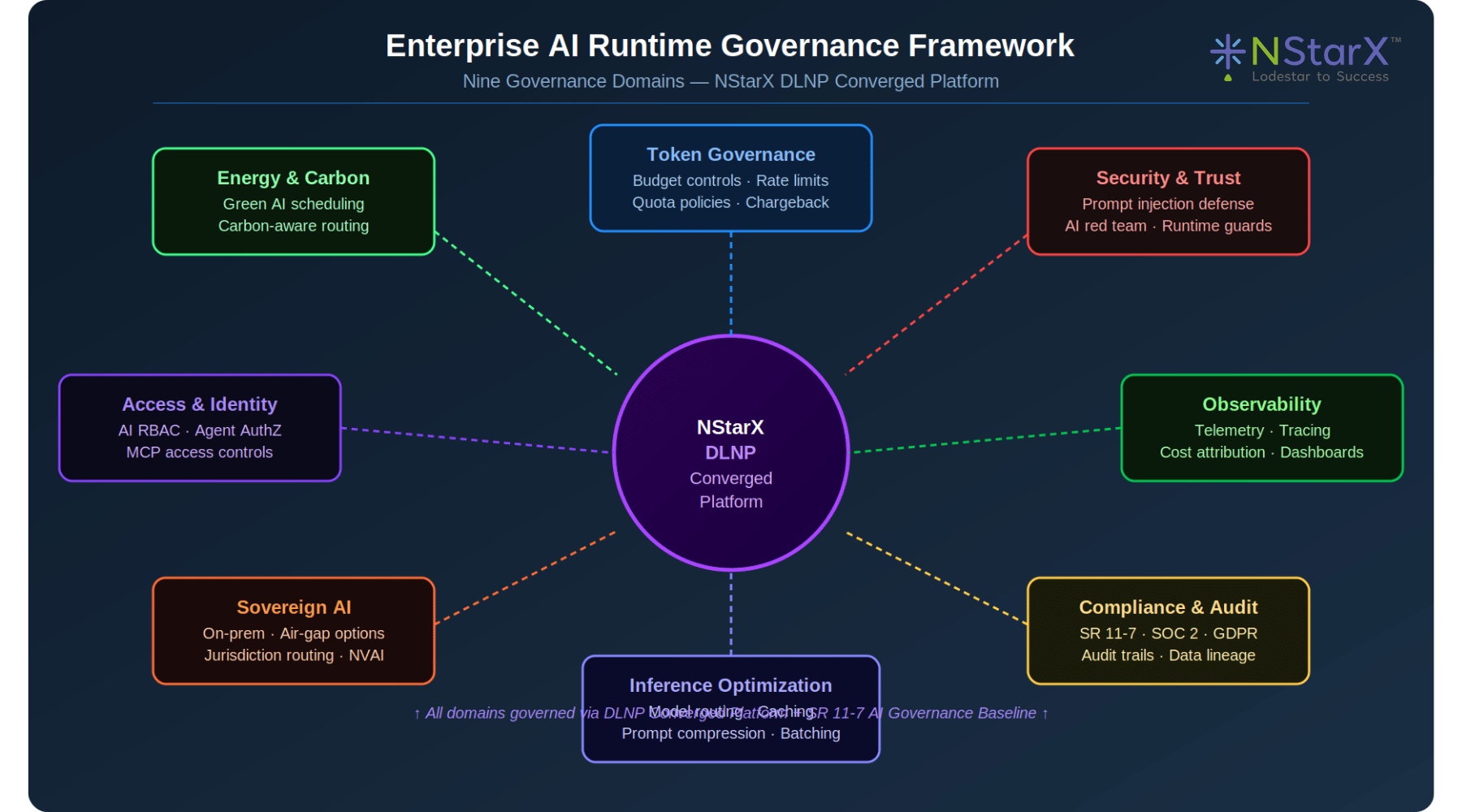
Figure 6: Enterprise AI Runtime Governance Framework — Nine Domains, DLNP Converged Platform
Governance Cost Modeling
| Governance Domain | Typical Overhead | Cost Driver | NStarX Approach |
|---|---|---|---|
| Token Governance | 2–5% of inference | Policy enforcement engine | DLNP policy layer — zero-overhead enforcement |
| Security (Prompt Defense) | 5–12% of inference | Classifier + red team validation | SR 11-7 baseline security controls |
| Observability / Telemetry | 3–8% of infrastructure | OpenTelemetry agents, storage | DLNP telemetry fabric — unified collection |
| Compliance / Audit | 4–10% of ops budget | Audit log generation and storage | Automated compliance trails in DLNP |
| Data Lineage | 2–5% of inference | Provenance tracking per token | Integrated with DLNP data fabric |
| Access Governance | 1–3% of inference | AuthZ checks per agent action | RBAC + MCP access controls in DLNP |
| AI Red Teaming | $50K–$200K per cycle | Manual + automated adversarial testing | NVIDIA FLARE federated security testing |
SR 11-7 AI Governance Baseline
The Federal Reserve SR 11-7 guidance on model risk management, adapted for the AI era, establishes the governance requirements that financial services enterprises — and increasingly all regulated industries — must meet for production AI systems. NStarX has built SR 11-7 compliance into the DLNP platform as a native capability, eliminating the point-solution overhead that characterizes most enterprise compliance approaches.
- Model Inventory: Complete registry of all AI models in production, including versions, training data, and intended use.
- Independent Validation: Adversarial testing and benchmark validation separate from model development.
- Ongoing Monitoring: Drift detection, performance degradation alerts, and bias monitoring in production.
- Documentation: Model cards, risk assessments, and audit-ready decision logs for every model.
- Governance Escalation: Clear paths for escalating model performance failures to risk management.
Section 6: Sovereign AI & Hybrid Inference Economics
The Economics of AI Sovereignty
Sovereign AI is no longer a compliance edge case — it is becoming a mainstream enterprise infrastructure strategy. The combination of escalating data residency requirements, AI provider pricing volatility, geopolitical supply chain risk, and growing regulatory pressure is driving enterprise technology leaders to build hybrid inference architectures that preserve cloud model access while establishing on-premises inference capabilities for regulated and sensitive workloads.
The economics of sovereign AI have shifted dramatically. Inference hardware costs have fallen 60–70% since 2022. NVIDIA FLARE federated learning and inference frameworks make distributed AI operations tractable at enterprise scale. The break-even point for on-premises inference — where the capital cost of GPU infrastructure is offset by avoided API costs — is now achievable in 18–24 months for enterprises processing more than 5 billion tokens per month.
Cloud vs. Sovereign Inference Economics
| Dimension | Cloud API (Frontier) | Cloud Open-Weight | On-Prem Sovereign | Hybrid (NStarX DLNP) |
|---|---|---|---|---|
| Cost per 1M tokens | $5–$20 | $0.25–$1.50 | $0.05–$0.40* | Dynamically optimized |
| Data residency | Provider-controlled | Provider-controlled | Full enterprise control | Workload-routed |
| Latency | 600–1,200ms | 200–600ms | 80–400ms (GPU) | Tier-optimized |
| Model flexibility | Provider-limited | Open ecosystem | Open ecosystem | Full flexibility |
| Governance control | Limited | Limited | Complete | Policy-governed |
| Capital requirement | None | None | High (Year 1–2) | Staged investment |
| Break-even (vs cloud) | N/A | N/A | 18–24 months | 12–18 months |
*On-premises cost includes amortized GPU capital, power, and operations.
AI Provider Lock-In Risk Framework
- Pricing Volatility: Major AI providers have repriced models 2–4 times annually since 2022; enterprises on fixed integrations face surprise cost events.
- API Dependency: Businesses building workflows around a single provider API face existential risk from model deprecations, rate limit changes, and service outages.
- Data Exposure: Training data and inference data ingested by third-party APIs may be subject to provider data policies that conflict with enterprise data governance requirements.
- Capability Lock: Models fine-tuned on proprietary provider platforms create portability barriers that increase switching costs over time.
- Geopolitical Risk: US-China AI competition and export control dynamics create supply chain risks for enterprises dependent on models or hardware from specific jurisdictions.
Section 7: 2026–2030 AI Tokenomics Predictions
The Next Five Years: Enterprise AI Economics Evolution
The AI economics landscape will undergo three distinct transformation phases over the 2026–2030 window. In the near term, inference pricing competition will compress costs dramatically while agentic deployment complexity accelerates spend. In the medium term, structural market mechanisms — token exchanges, AI compute marketplaces, internal AI economies — will emerge. In the long term, AI agents will operate as autonomous economic actors, negotiating their own compute costs and making inference routing decisions without human intervention.
The enterprises that position for this trajectory now — building AI FinOps capabilities, hybrid inference infrastructure, and governance frameworks — will command structural advantages as these dynamics unfold. Those that defer will find themselves paying an accelerating premium for the governance and architecture debt they accumulated during the deployment phase.
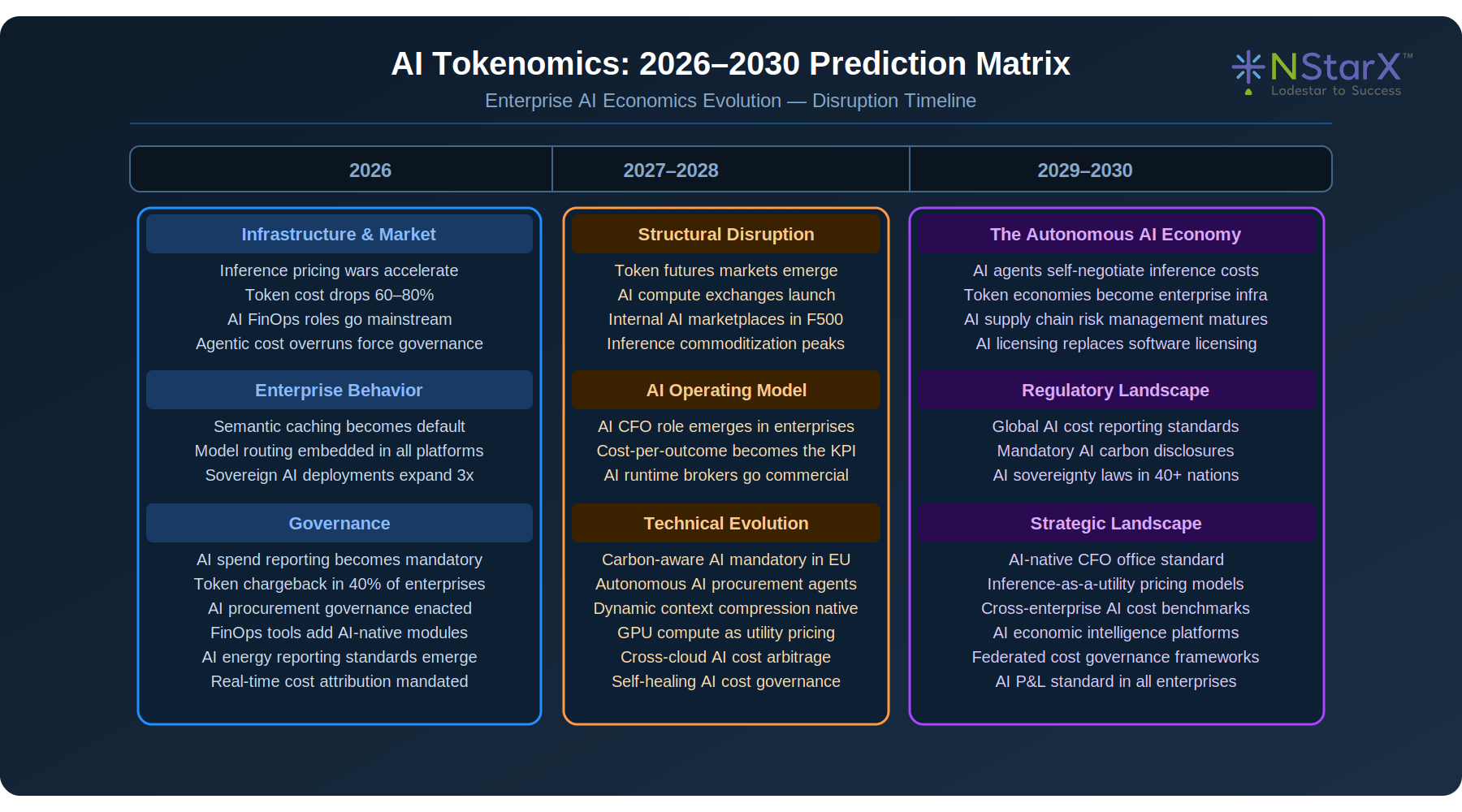
Figure 7: AI Tokenomics 2026–2030 Prediction Matrix
Market Disruption Scenarios
| Scenario | Probability | Enterprise Impact | Strategic Response |
|---|---|---|---|
| Inference commoditization (2026–27) | High (>80%) | Token costs drop 70%+; value shifts to orchestration and governance | Invest in architecture and FinOps, not model access |
| Token futures markets (2027–28) | Medium (50–60%) | Enterprise AI procurement becomes a financial function | Build AI procurement governance capabilities now |
| Autonomous AI procurement (2028–29) | Medium (40–55%) | AI agents self-optimize compute costs without human approval | Establish agent financial governance frameworks |
| AI sovereignty regulation (2027+) | High (>70%) | Data residency mandates expand significantly in EU, APAC | Deploy hybrid/sovereign inference architecture |
| AI utility pricing (2029–30) | Medium (45–60%) | AI compute priced like electricity: usage-based, real-time | Align architecture to consumption-optimized patterns |
Section 8: NStarX — Engineering AI Economics
NStarX: The Enterprise Partner for Economically Sustainable AI
NStarX does not position itself as an AI implementation partner in the conventional sense — a firm that deploys AI capabilities and measures success by feature delivery. NStarX positions itself as the enterprise partner that engineers the economics, governance, and operational sustainability of Agentic AI itself.
The distinction is critical. Every major enterprise can access frontier AI models through API contracts. The differentiating capability in 2026 and beyond is not model access — it is the ability to deploy those models at scale with governance, cost discipline, security controls, and operational maturity. This is the “Service as Software” thesis: AI-native delivery models that make production-grade, economically sustainable AI operations the standard, not the exception.
NStarX Core Platform Capabilities
| Capability | Description | Business Outcome |
|---|---|---|
| DLNP Converged Platform | Unified AI governance, observability, and inference optimization fabric | Single pane of glass for AI cost, risk, and performance |
| SR 11-7 AI Governance Baseline | Model risk governance aligned to financial services and regulated industry standards | Compliance-ready AI operations from day one |
| NVIDIA FLARE Integration | Federated learning and distributed inference orchestration | Privacy-preserving AI across distributed enterprise data |
| Token-Aware Architecture Design | Inference topology designed around cost-per-outcome optimization | 40–65% reduction in inference spend vs. unoptimized deployment |
| AI FinOps Operating Model | People, process, and platform design for enterprise AI cost governance | Predictable, attributable AI economics with chargeback capability |
| Hybrid Sovereign Inference | On-premises + cloud inference architecture with policy-based routing | Data sovereignty + cost optimization without capability sacrifice |
| Multi-Agent Orchestration | Production-grade agentic workflow design with token-aware optimization | Scalable agentic AI that doesn’t explode the operating budget |
The NStarX Engagement Model
- Assessment: Enterprise AI Economics Assessment — benchmark current AI spend, identify token waste, map governance gaps against SR 11-7 and DLNP baseline.
- Architecture: Token-aware architecture redesign — AI gateway implementation, hybrid inference topology, semantic caching deployment.
- Governance: AI FinOps operating model implementation — council structure, chargeback systems, observability platform deployment.
- Optimization: Ongoing AI economics engineering — model routing tuning, prompt optimization cycles, cost-per-outcome trending.
- Sovereign: Sovereign AI planning — on-premises inference business case, NVIDIA GPU infrastructure planning, FLARE deployment.
47% |
90 Days |
100% |
| Average Inference Cost Reduction | Time to AI FinOps Operating Model | Enterprises Achieving SR 11-7 Compliance |
Download Whitepaper
Tokenomics 2.0
The Economics of Enterprise Agentic AI
This whitepaper explores “AI Tokenomics,” a new discipline for managing the unpredictable costs of agentic AI, where complex workflows can amplify token consumption by over 200x. It introduces a comprehensive framework for AI FinOps and token-aware architecture to help enterprises avoid overspending by 8–12x. By implementing proactive governance and optimized inference strategies, organizations can achieve sustainable AI scaling and significant long-term ROI.
NStarX Inc. · AI-Native Platform & Engineering Services · Backed by SHI International · NVIDIA SVAR Partner · DLNP Converged Platform · SR 11-7 AI Governance · NVIDIA FLARE Federated Learning · Service as Software