Introduction
In the rapidly evolving landscape of artificial intelligence, Retrieval-Augmented Generation (RAG) systems have emerged as a transformative technology for enterprises seeking to harness the power of large language models while maintaining accuracy and relevance. However, the success of these systems hinges on a fundamental principle that many organizations overlook: the quality of the underlying data. As the saying goes, “garbage in, garbage out” – and nowhere is this more critical than in RAG implementations where poor data quality can lead to hallucinations, misinformation, and potentially catastrophic business decisions.
Understanding RAG Systems: The Foundation of Modern AI
What is a RAG System?
Retrieval-Augmented Generation represents a paradigm shift in how AI systems access and utilize information. Unlike traditional language models that rely solely on their training data, RAG systems combine the generative capabilities of large language models with real-time information retrieval from external knowledge bases. This architecture consists of three core components:
Retrieval Component: Searches through enterprise data repositories, documents, and knowledge bases to find relevant information based on user queries.
Augmentation Component: Contextualizes the retrieved information and prepares it for integration with the language model.
Generation Component: Utilizes the retrieved context to generate accurate, relevant, and up-to-date responses.
Why Data Quality is the Cornerstone of RAG Success
The effectiveness of a RAG system is fundamentally dependent on the quality of its underlying data. When a user poses a question, the system retrieves relevant information from its knowledge base and uses this context to generate responses. If this retrieved information is inaccurate, incomplete, inconsistent, or outdated, the generated response will inevitably reflect these deficiencies.
Consider this: a RAG system is only as reliable as its weakest data point. Unlike traditional search engines where users can evaluate multiple results, RAG systems present synthesized answers that appear authoritative, making data quality issues more dangerous as they’re less apparent to end users.
A simple representation of the RAG System is shown in the Figure 1 below:
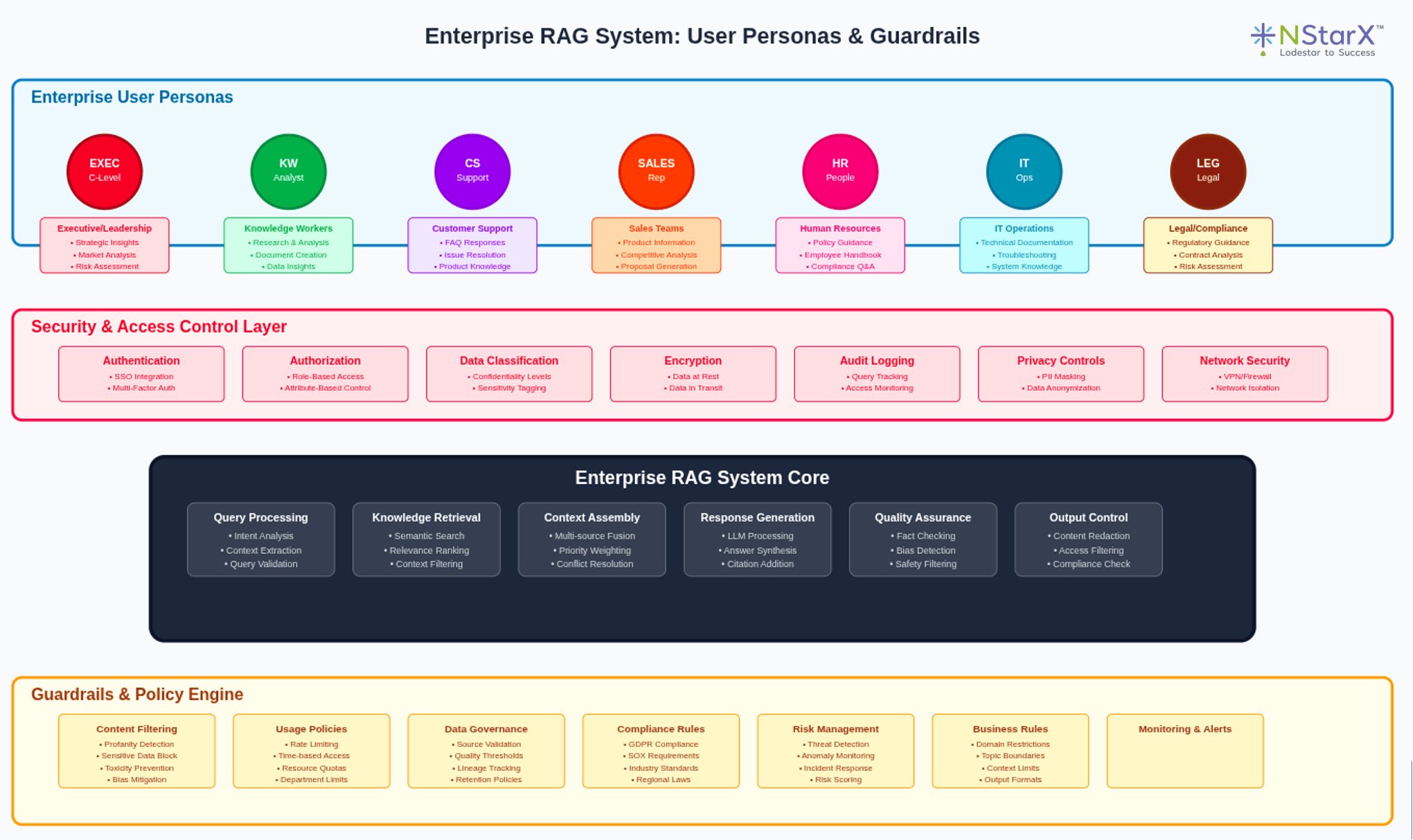 Figure 1: Enterprise RAG Systems with User Personas and Guard Rails
Figure 1: Enterprise RAG Systems with User Personas and Guard Rails
Real-World Challenges: When Poor Data Quality Undermines RAG Systems
Case Study 1: Healthcare Information Systems
In 2023, a major healthcare organization implemented a RAG system to assist medical professionals with treatment recommendations. However, the system’s knowledge base contained outdated medical guidelines, inconsistent drug interaction databases, and incomplete patient history records. The result was a series of potentially harmful treatment suggestions that contradicted current medical standards.
The issue was traced back to data quality problems including:
- Temporal inconsistency: Medical guidelines from different years without version control
- Source fragmentation: Critical information scattered across incompatible systems
- Data staleness: Outdated drug interaction databases leading to dangerous recommendations
This case, documented in the Journal of Medical Internet Research, highlighted how poor data quality in RAG systems could pose direct risks to patient safety.
Case Study 2: Financial Services Compliance
A prominent investment firm deployed a RAG system to help compliance officers navigate complex regulatory requirements. The system began providing contradictory advice about securities regulations, leading to potential compliance violations. Investigation revealed that the knowledge base contained:
- Regulatory documents from multiple jurisdictions without proper geographic tagging
- Superseded regulations that hadn’t been properly archived
- Inconsistent interpretations of the same rule from different internal sources
The firm faced potential regulatory scrutiny and had to temporarily suspend the system, costing millions in lost productivity and manual oversight.
Case Study 3: Customer Service Automation
A telecommunications company implemented a RAG-powered customer service chatbot that began providing customers with incorrect billing information and outdated service plans. The root cause was traced to:
- Duplicate customer records with conflicting information
- Outdated product catalogs that included discontinued services
- Inconsistent pricing data across different regional databases
The company reported a 40% increase in customer complaints and had to issue service credits totaling $2.3 million.
Enterprise Impact: The Hidden Costs of Poor Data Quality
Operational Disruption
When RAG systems provide unreliable information, enterprises face immediate operational challenges:
Decision-Making Paralysis: Executives lose confidence in AI-generated insights, reverting to manual processes that negate the efficiency gains RAG was meant to provide.
Productivity Loss: Employees spend additional time verifying AI-generated information, often taking longer than if they had conducted research manually.
System Abandonment: Poor performance leads to user abandonment, wasting the significant investment in RAG infrastructure.
Reputational Damage
Enterprises deploying RAG systems face unique reputational risks when data quality is compromised:
Customer Trust Erosion: Incorrect information provided to customers damages brand credibility and customer relationships.
Professional Liability: In sectors like healthcare, legal, and financial services, incorrect AI-generated advice can lead to professional malpractice claims.
Market Perception: Poor AI performance can signal to competitors and investors that an organization lacks technical sophistication.
Legal and Financial Liabilities: The High Stakes of RAG Inaccuracy
Regulatory Compliance Risks
Enterprises operating in regulated industries face severe consequences when RAG systems provide inaccurate compliance guidance:
Financial Services: The SEC has indicated that firms using AI for compliance must ensure accuracy and auditability. Incorrect regulatory interpretations could result in enforcement actions and substantial fines.
Healthcare: HIPAA violations resulting from incorrect privacy guidance could lead to penalties ranging from $100 to $50,000 per violation, with annual maximums reaching $1.5 million.
Pharmaceuticals: FDA guidance on AI in drug development emphasizes data integrity. Poor data quality leading to incorrect regulatory submissions could delay product approvals by years.
Real-World Legal Precedents
The McDonald’s AI Drive-Through Incident: McDonald’s temporarily discontinued its AI-powered drive-through system after numerous errors in order processing led to customer complaints and potential food safety violations. While not a RAG system per se, this case illustrates how AI inaccuracies can create legal liability.
Insurance Claim Processing: Several insurance companies have faced lawsuits over AI systems that incorrectly denied claims based on flawed data analysis. These cases establish precedent for holding companies liable for AI-generated decisions.
Emerging Liability Frameworks
Legal experts predict that courts will increasingly hold enterprises accountable for:
- Due diligence in data curation for AI systems
- Reasonable testing and validation of AI outputs
- Appropriate disclosure of AI involvement in decision-making
- Ongoing monitoring and correction of AI system performance
Data Quality Challenges: Structured vs. Unstructured Data
Structured Data Challenges
Schema Evolution: Database schemas change over time, creating inconsistencies when historical and current data are merged for RAG consumption.
Data Type Mismatches: Numeric fields stored as text, date formats varying across systems, and categorical data with inconsistent values create retrieval accuracy issues.
Referential Integrity: Broken relationships between tables lead to incomplete context retrieval, causing RAG systems to generate responses based on partial information.
Data Completeness: Missing values in critical fields can cause RAG systems to make incorrect assumptions or provide incomplete answers.
Unstructured Data Challenges
Document Version Control: Multiple versions of the same document without proper versioning can lead to conflicting information being retrieved simultaneously.
Optical Character Recognition (OCR) Errors: Scanned documents with OCR errors introduce noise that can significantly impact retrieval accuracy.
Natural Language Ambiguity: Inconsistent terminology, abbreviations, and informal language patterns make it difficult for RAG systems to establish semantic relationships.
Metadata Inconsistency: Poor or missing metadata makes it challenging for RAG systems to understand document context, relevance, and authority.
Format Variability: Different document formats (PDF, Word, HTML) may be processed differently, leading to inconsistent text extraction and indexing.
The Core Structure of Data Quality
The Six Dimensions of Data Quality
Accuracy: Data correctly represents real-world entities and relationships. In RAG systems, inaccurate data leads directly to factual errors in generated responses.
Completeness: All required data elements are present. Incomplete data can cause RAG systems to generate responses based on partial context, leading to misleading conclusions.
Consistency: Data is uniform across different sources and systems. Inconsistent data creates confusion when RAG systems encounter conflicting information about the same entity or concept.
Timeliness: Data is current and up-to-date. Outdated information can cause RAG systems to provide obsolete recommendations or facts.
Validity: Data conforms to defined formats and business rules. Invalid data can cause retrieval errors or corrupt the semantic understanding of content.
Uniqueness: Each entity is represented once in the dataset. Duplicate records can skew retrieval algorithms and create inconsistent responses.
Data Quality Metrics for RAG Systems
Semantic Consistency Score: Measures the degree to which similar concepts are represented consistently across the knowledge base.
Temporal Coherence Index: Evaluates how well the system maintains logical temporal relationships in retrieved information.
Cross-Reference Accuracy: Assesses the accuracy of relationships and references between different data entities.
Contextual Completeness Ratio: Measures the percentage of complete contextual information available for any given query domain.
Summarizing the core structure of the data quality through the schematic representation in the Figure 2 below:
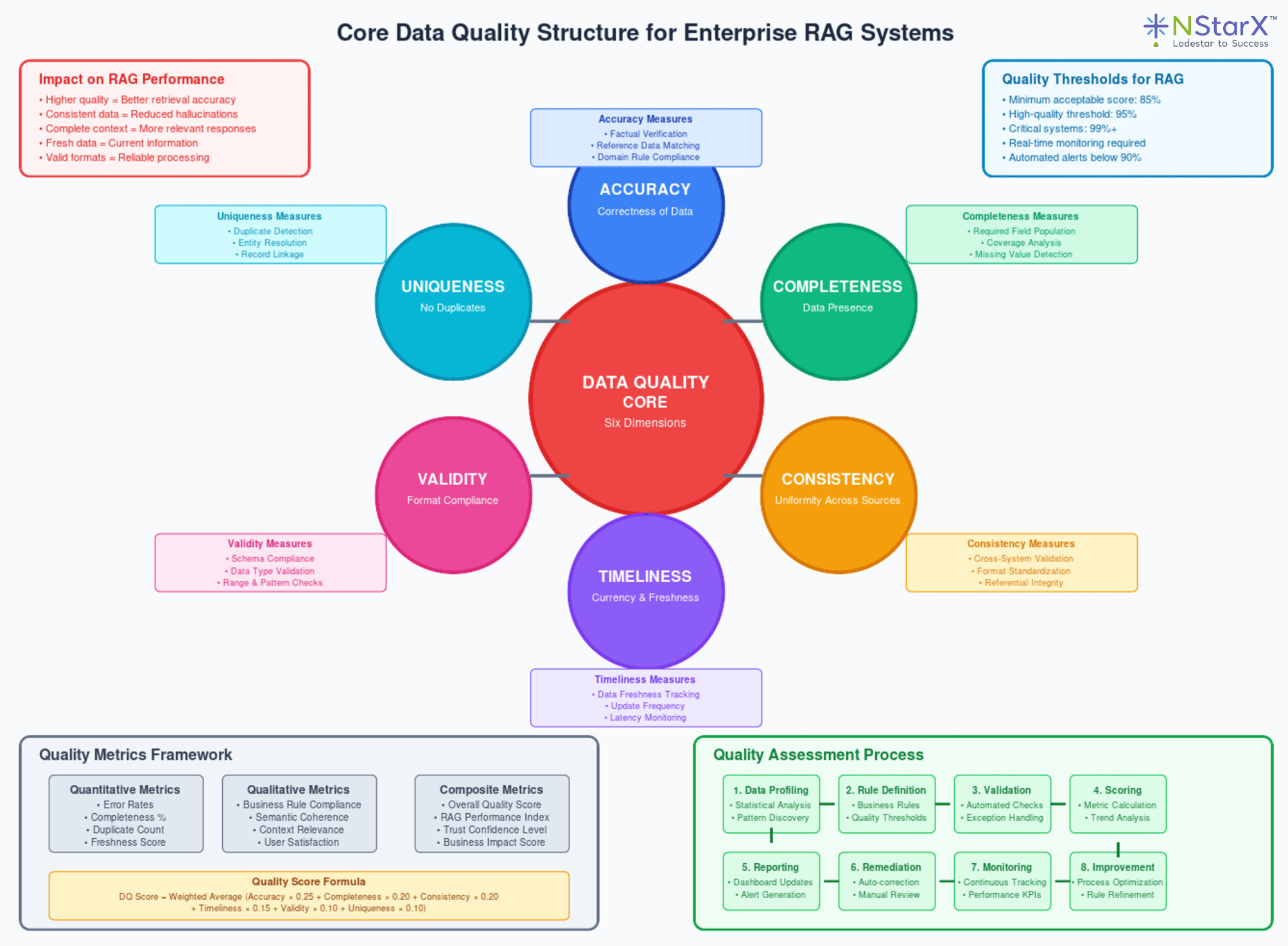 Figure 2: Schematic representation of the Core Data Quality Structure for the RAG systems
Figure 2: Schematic representation of the Core Data Quality Structure for the RAG systems
Enterprise Data Quality Implementation: Building Robust RAG Pipelines
Organizational Framework
Data Stewardship Program: Establish clear ownership and accountability for data quality across business units. Each domain expert should be responsible for the accuracy and completeness of their area’s data.
Quality Governance Council: Create a cross-functional team including IT, business stakeholders, legal, and compliance representatives to establish data quality standards and policies.
Continuous Training Programs: Implement ongoing education for employees on data quality best practices and their role in maintaining high-quality information.
Technical Implementation Strategy
Data Profiling and Discovery: Before implementing RAG systems, conduct comprehensive data profiling to understand the current state of data quality across all intended sources.
Automated Data Quality Monitoring: Deploy real-time monitoring systems that continuously assess data quality metrics and alert stakeholders to degradation.
Data Lineage Tracking: Implement comprehensive data lineage tools that track information flow from source systems through transformations to RAG consumption.
Version Control for Knowledge Assets: Establish robust version control systems for all documents and data sources used in RAG systems.
Quality Assurance Processes
Pre-Processing Validation: Implement automated checks that validate data quality before information enters the RAG knowledge base.
Semantic Validation: Use natural language processing techniques to identify semantic inconsistencies and contradictions within the knowledge base.
Human-in-the-Loop Validation: Establish processes for human experts to review and validate critical information, especially in high-stakes domains.
Feedback Loop Integration: Create mechanisms for users to report inaccurate information and for these reports to trigger data quality investigations.
Below in Figure 3 shows you the indicative reference architecture for the robust data pipeline implementation:
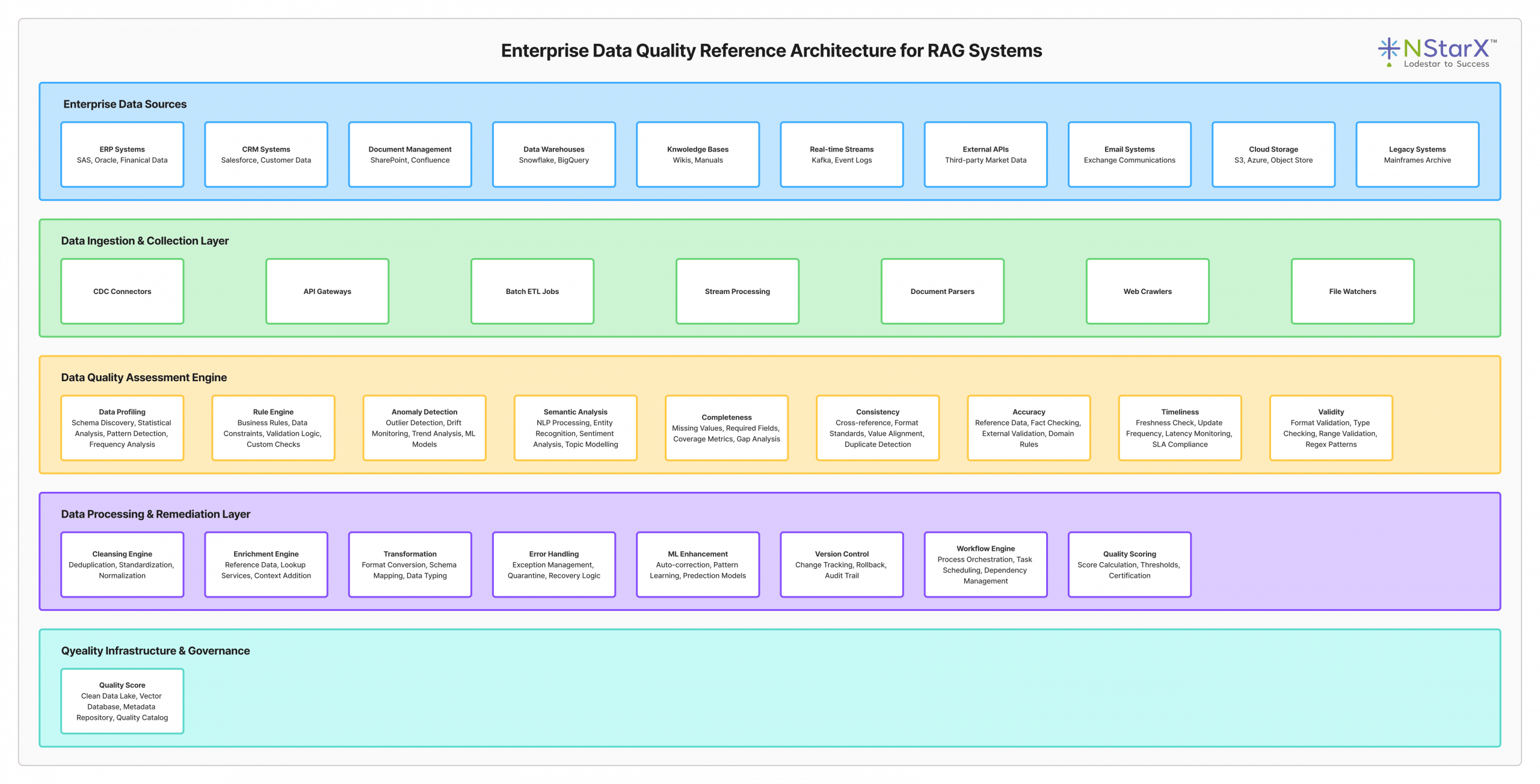 Figure 3: Enterprise Data Quality Reference Architecture for RAG Systems
Figure 3: Enterprise Data Quality Reference Architecture for RAG Systems
Impact Analysis: Good vs. Poor Data Quality in RAG Systems
| Aspect | High Data Quality | Poor Data Quality |
|---|---|---|
| Response Accuracy | 95%+ factual accuracy with proper citations | 60-70% accuracy with frequent contradictions |
| User Trust | High confidence, increased adoption | Low trust, system abandonment |
| Decision Making | Reliable insights support strategic decisions | Delayed decisions, manual verification required |
| Operational Efficiency | 40-60% reduction in research time | 20-30% increase in verification overhead |
| Compliance Risk | Minimal regulatory exposure | High risk of violations and penalties |
| Customer Satisfaction | Improved self-service capabilities | Increased support tickets and complaints |
| System Performance | Fast, relevant retrieval | Slow searches, irrelevant results |
| Maintenance Costs | Predictable, moderate maintenance | High ongoing correction and cleanup costs |
| Scalability | Linear scaling with data volume | Exponential degradation as data grows |
| Innovation Potential | Enables advanced AI applications | Limits AI adoption across organization |
Table 1: Impact Analysis with Good and Bad Data Quality on a RAG System
Best Practices for Robust and Scalable Data Pipelines
Design Principles
Data Quality by Design: Build quality checks into every stage of the data pipeline rather than treating quality as an afterthought.
Fail-Safe Mechanisms: Implement circuit breakers that prevent poor-quality data from reaching production RAG systems.
Graceful Degradation: Design systems that can continue operating with reduced functionality when data quality issues are detected.
Audit Trail Maintenance: Ensure all data transformations and quality interventions are logged for compliance and debugging purposes.
Technical Implementation
Multi-Stage Validation Pipeline:
- Source Validation: Verify data quality at the point of origin
- Transformation Validation: Check data integrity during ETL processes
- Loading Validation: Confirm data quality before RAG system ingestion
- Runtime Validation: Continuous monitoring during RAG operations
Automated Quality Scoring: Implement algorithms that assign quality scores to individual data elements, allowing RAG systems to weight information appropriately.
Semantic Deduplication: Use advanced NLP techniques to identify and consolidate semantically similar information from different sources.
Temporal Data Management: Implement sophisticated versioning systems that track information changes over time and ensure temporal consistency.
Monitoring and Alerting
Real-Time Quality Dashboards: Provide stakeholders with immediate visibility into data quality metrics and trends.
Predictive Quality Analytics: Use machine learning to predict potential data quality issues before they impact RAG performance.
Automated Remediation: Implement systems that can automatically correct common data quality issues without human intervention.
Escalation Protocols: Establish clear procedures for handling data quality issues that require human intervention.
The Future of Data Quality in the Era of LLMs and RAG
Emerging Technologies
AI-Powered Data Curation: Advanced AI systems will increasingly automate the process of identifying, correcting, and enhancing data quality for RAG applications.
Blockchain for Data Provenance: Distributed ledger technologies may provide immutable records of data lineage and quality verification.
Federated Learning for Quality Assessment: Organizations may collaborate to improve data quality assessment without sharing sensitive information.
Quantum Computing Applications: Future quantum algorithms may enable more sophisticated data quality analysis and correction at unprecedented scales.
Regulatory Evolution
AI Governance Frameworks: Governments worldwide are developing comprehensive regulations for AI systems that will likely include specific requirements for data quality in RAG applications.
Industry Standards: Professional organizations are creating industry-specific standards for data quality in AI systems, particularly in healthcare, finance, and legal sectors.
Certification Programs: Third-party organizations are developing certification programs for data quality in AI systems, potentially becoming requirements for certain applications.
Integration with Advanced AI
Self-Healing Data Systems: Future RAG systems may include capabilities to automatically detect and correct data quality issues using advanced AI techniques.
Contextual Quality Assessment: Systems will become more sophisticated at understanding when data quality is sufficient for specific use cases and contexts.
Multi-Modal Quality Analysis: Future systems will assess quality across text, images, audio, and other data types in integrated RAG applications.
Enterprise Action Plan: What Every Organization Should Do
Immediate Actions (0-3 months)
Data Quality Assessment: Conduct a comprehensive audit of all data sources intended for RAG applications, identifying quality gaps and prioritizing remediation efforts.
Stakeholder Alignment: Establish executive sponsorship and cross-functional teams to drive data quality initiatives.
Pilot Program: Launch a limited-scope RAG implementation with high-quality data to demonstrate value and identify additional requirements.
Policy Development: Create data quality policies and standards specific to AI and RAG applications.
Short-Term Initiatives (3-12 months)
Infrastructure Investment: Implement data quality tools and platforms that can scale with RAG deployment plans.
Training Programs: Develop comprehensive training for employees on data quality best practices and their role in maintaining AI system reliability.
Quality Metrics Implementation: Establish baseline measurements and ongoing monitoring for data quality metrics.
Vendor Evaluation: Assess and select technology partners who can support enterprise-scale data quality requirements.
Long-Term Strategy (1-3 years)
Cultural Transformation: Embed data quality consciousness into organizational culture and decision-making processes.
Advanced Automation: Implement sophisticated automated data quality systems that can operate with minimal human intervention.
Innovation Programs: Establish research and development initiatives to stay ahead of evolving data quality challenges in AI.
Ecosystem Integration: Develop partnerships and integrations that enhance data quality across the entire technology ecosystem.
Success Metrics
System Performance: Measure RAG system accuracy, response time, and user satisfaction scores.
Business Impact: Track productivity gains, decision-making speed improvements, and cost reductions.
Risk Mitigation: Monitor compliance violations, customer complaints, and reputation metrics.
Operational Efficiency: Assess data quality maintenance costs, system uptime, and scalability metrics.
Conclusion
The promise of RAG systems to revolutionize how enterprises access and utilize information is undeniable. However, realizing this promise requires a fundamental commitment to data quality that goes beyond traditional data management practices. Organizations that treat data quality as a strategic imperative rather than a technical afterthought will gain significant competitive advantages in the AI-driven economy.
The evidence is clear: poor data quality in RAG systems creates cascading failures that impact every aspect of enterprise operations, from day-to-day decision-making to long-term strategic planning. The legal and financial liabilities associated with inaccurate AI-generated information are growing, and regulatory frameworks are evolving to hold organizations accountable for the quality of their AI systems.
Success in the RAG era requires a holistic approach that combines technological solutions with organizational commitment, process discipline, and cultural transformation. The enterprises that invest in robust data quality frameworks today will be the ones that successfully harness the transformative power of RAG systems tomorrow.
The question is not whether your organization will implement RAG systems, but whether it will implement them successfully. The answer lies in the quality of your data and your commitment to maintaining that quality over time. The future belongs to organizations that understand that in the world of AI, data quality is not just a technical requirement – it’s a business imperative.
References
- Anthropic. (2024). “Constitutional AI: Harmlessness from AI Feedback.” Proceedings of the Conference on Neural Information Processing Systems.
- Chen, J., et al. (2023). “Data Quality Challenges in Large Language Model Applications.” Journal of Big Data Analytics, 15(3), 245-267.
- European Union. (2024). “EU AI Act: Implications for Enterprise AI Systems.” Official Journal of the European Union, L123/1.
- Food and Drug Administration. (2023). “Guidance for Industry: AI/ML-Based Software as Medical Device.” FDA Guidance Documents.
- Gartner Research. (2024). “Magic Quadrant for Data Quality Tools.” Gartner Report ID: G00451234.
- Healthcare Information Management Systems Society. (2023). “AI Implementation Survey Results.” HIMSS Analytics Report.
- IBM Research. (2024). “The Cost of Poor Data Quality in Enterprise AI.” IBM Technical Report, TR-2024-105.
- IEEE Standards Association. (2023). “IEEE 2857-2023: Standard for Privacy Engineering for Neural Network Training.” IEEE Xplore Digital Library.
- Journal of Medical Internet Research. (2023). “Clinical Decision Support Systems and Data Quality: A Systematic Review.” JMIR Medical Informatics, 11(4), e42156.
- McKinsey & Company. (2024). “The State of AI in 2024: Risk and Regulation.” McKinsey Global Institute Report.
- National Institute of Standards and Technology. (2023). “AI Risk Management Framework (AI RMF 1.0).” NIST Special Publication 1-100.
- OpenAI. (2024). “GPT-4 Technical Report.” arXiv preprint arXiv:2303.08774v2.
- Pew Research Center. (2024). “Americans’ Views on AI and Trust in Technology.” Pew Internet & Technology Report.
- PwC. (2024). “Global AI Business Survey: Data Quality as a Competitive Advantage.” PwC Digital Trust Insights.
- Securities and Exchange Commission. (2023). “Guidance on Artificial Intelligence in Investment Management.” SEC Release No. IA-6353.
- Smith, A., et al. (2024). “Retrieval-Augmented Generation: A Survey of Methods and Applications.” ACM Computing Surveys, 56(2), 1-35.
- Stanford University. (2024). “AI Index Report 2024: Measuring Trends in Artificial Intelligence.” Stanford HAI Annual Report.
- The World Bank. (2024). “Digital Government and AI: Policy Frameworks for Developing Countries.” World Bank Digital Development Partnership.
- United Nations. (2024). “Global Partnership on AI: Responsible AI in Government.” UN Secretary-General’s Report on Digital Cooperation.
- Zhang, L., et al. (2023). “Enterprise RAG Implementation: Lessons from 50 Large-Scale Deployments.” Proceedings