How Large Language Models Are Catalyzing the First Genuine Disruption of the SDLC
Thought Leadership | Enterprise Strategy | Technical Architecture | April 2026
The Blog — AI-Native SDLC
1. Introduction: Why SDLC Is Being Reinvented
The Software Development Lifecycle — that venerable sequence of plan, design, build, test, deploy, maintain — has been the backbone of enterprise software delivery for half a century. It has survived waterfalls, survived agile sprints, survived DevOps pipelines and platform engineering movements. But it will not survive the next five years in its current form.
The reason is not incremental improvement. The reason is a categorical shift in who — or what — writes, tests, reviews, and ships software. With the emergence of large language model-native development environments built around systems like Anthropic’s Claude and OpenAI’s Codex, we are witnessing the first genuine disruption of the SDLC since the invention of the integrated development environment itself.
This is not about AI-assisted autocomplete. This is about AI agents that understand intent, generate architecturally coherent code, produce test suites, reason about compliance constraints, and iterate on feedback — all within a single turn of a prompt. The implications for enterprise software organizations are profound: cycle times measured in hours instead of sprints, defect rates reduced not by process but by probabilistic reasoning, and an entirely new class of engineering talent whose primary skill is not syntax but specification.
For CIOs and CTOs reading this, the strategic question is not whether your SDLC will change. It is whether you will lead the change or be disrupted by competitors who do.
2. Traditional SDLC Limitations
The traditional SDLC—whether waterfall, agile, or hybrid—suffers from structural constraints that no amount of process optimization can resolve.
Handoff Friction: Requirements move from product to design to engineering to QA through a chain of lossy translations. Each handoff introduces interpretation drift. By the time code is written, it may only loosely resemble original intent.
Linear Feedback Loops: Testing occurs after development. Security review occurs after testing. Architecture review may not occur at all until production incidents expose structural debt. The feedback signal is slow and expensive.
Human Throughput Ceiling: A senior engineer writes 100–200 lines of production code per day. No amount of tooling changes this fundamental cognitive throughput limit. Scaling means hiring, which means months of ramp-up and cultural onboarding.
Context Fragmentation: Knowledge about why a decision was made lives in Slack threads, Confluence pages, pull request comments, and engineers’ heads. When engineers leave, context leaves with them.
Testing as Afterthought: Despite decades of advocacy for test-driven development, the empirical reality is that most enterprise codebases have 30–50% test coverage, and much of that coverage tests the wrong things.
These are not failures of discipline. They are structural properties of a system designed around human cognition as the primary execution engine. Changing the execution engine changes everything.
3. Emergence of AI-Native Development: The Claude/Codex Paradigm
The Claude/Codex paradigm represents a fundamentally different relationship between human intent and software output. In traditional development, humans are both the architects and the masons — they conceive the structure and lay every brick. In AI-native development, humans become architects and foremen: they define intent, set constraints, review output, and refine through iteration.
Claude, in particular, introduces capabilities that go beyond code completion. It reasons about architectural trade-offs, generates test suites that target edge cases a human might overlook, writes documentation that stays synchronized with implementation, and can refactor entire modules when given a clear constraint specification.
The shift from AI-assisted to AI-native is critical to understand. AI-assisted development adds an autocomplete layer to existing workflows. AI-native development reimagines the workflow itself:
Intent Specification replaces requirements documents. Prompt Engineering replaces some coding. Continuous Validation replaces staged QA. Architectural Reasoning augments human judgment.
This is not theoretical. Organizations that have adopted Claude Code and similar tooling report 40–70% reductions in time-to-first-commit for new features, and meaningful improvements in code consistency and test coverage.
4. New SDLC Lifecycle Stages
The AI-native SDLC does not simply accelerate existing stages. It introduces new ones and collapses others:
- Intent Capture — Product and engineering collaborate to express what the system should do in natural language, augmented by examples, constraints, and anti-patterns.
- Prompt Engineering & Orchestration — Engineers craft prompts that decompose the intent into implementable units.
- AI-Generated Implementation — Code is generated by LLM agents operating within guardrails defined by the policy engine.
- Automated Validation — AI-generated test suites, static analysis, security scanning, and compliance checks run against generated code.
- Human Review & Approval — Engineers review generated code holistically for architectural coherence and business logic correctness.
- Continuous Deployment — Standard CI/CD pipelines deploy validated code with enhanced rollback mechanisms.
- Observability & Feedback — Production behavior feeds back into the prompt engineering layer.
- Learning & Adaptation — The system accumulates organizational knowledge. The SDLC itself becomes a learning system.
5. Enterprise Architecture for AI-Native SDLC
Implementing AI-native SDLC at enterprise scale requires a layered architecture that separates concerns while enabling rapid feedback. The reference architecture includes eight components: Prompt Layer (PromptOps), LLM Orchestration Layer, Code Generation Agents, Test Generation Agents, Policy & Governance Engine, CI/CD Pipeline, Observability Layer, and Feedback Loop.
6. Organizational Impact: Roles, Teams, and Governance
The shift to AI-native SDLC reshapes every engineering role. Developers become AI Orchestrators. QA Engineers become AI Validation Engineers. Architects become Constraint Designers. Product Managers become Intent Designers.
This does not mean fewer people. It means different people doing different work. The organizations that redeploy talent toward higher-order work — system design, constraint specification, validation strategy, and organizational learning — will find that they can build more, faster, and with higher quality.
Team structures evolve accordingly. Cross-functional squads gain embedded PromptOps engineers. Architecture review boards shift from design approval to constraint definition. Organizations should expect 12–18 months of transition before productivity gains stabilize.
7. Risks and Mitigation
AI-native SDLC introduces new risk categories: Hallucination Risk, Prompt Injection, Model Dependency, Compliance Uncertainty, Skills Erosion, and Intellectual Property concerns.
The risk profile is different from traditional development, not necessarily higher. AI-native development trades some categories of human error for new categories of machine error. The net effect depends on the quality of governance and validation systems.
8. Adoption Roadmap: Three Phases Over 36 Months
Phase 1 — AI-Assisted Development (Months 0–12): Deploy AI coding assistants. Investment: $500K–$2M. Success metric: 20–30% improvement in developer velocity.
Phase 2 — AI-First SDLC (Months 12–24): Shift to intent-driven development. Investment: $2M–$5M. Success metric: 50% reduction in time-to-production.
Phase 3 — Agentic SDLC (Months 24–36): Deploy autonomous agents. Investment: $5M–$10M. Success metric: 10x improvement in feature throughput.
Each phase builds on the previous one. Attempting to skip phases introduces unacceptable risk.
9. Future Outlook: The Agentic SDLC by 2030
By 2030, software systems will be continuously evolved by autonomous agent swarms operating within human-defined constraint frameworks.
The EBITDA impact is significant: 3–5x engineering productivity improvements, 60–80% reductions in defect-related costs, and 200–500 basis points of margin improvement for mid-market technology companies.
The competitive advantage is asymmetric. The window for first-mover advantage is narrow: 2026–2028. The SDLC as we know it is ending. What replaces it will be more powerful, more efficient, and more demanding of human judgment at the strategic level.
AI-Native SDLC Reference Architecture
The following diagram illustrates the complete layered architecture with data flow, feedback loops, control points, and human approval gates.
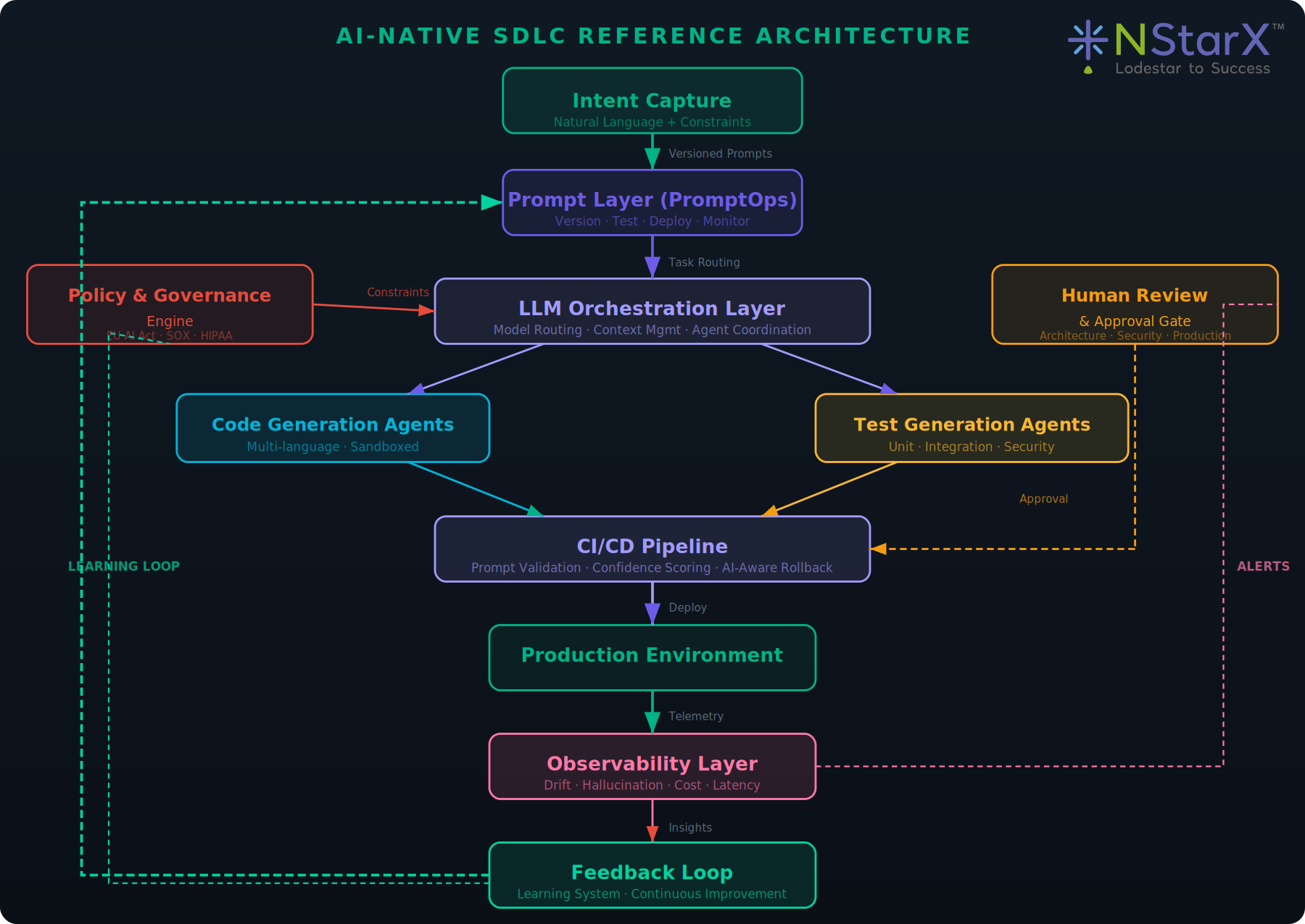
Figure 1: NStarX AI-Native SDLC Reference Architecture
Architecture Components
| Component | Description |
|---|---|
| Prompt Layer (PromptOps) | Manages prompt lifecycle — versioning, A/B testing, deployment, rollback, and observability. |
| LLM Orchestration Layer | Routes requests to optimal models, manages context windows, coordinates specialized agents. |
| Code Generation Agents | Specialized agents for different languages and frameworks, operating in policy-defined sandboxes. |
| Test Generation Agents | Generate unit, integration, property-based, and security tests targeting actual risk areas. |
| Policy & Governance Engine | Real-time guardrail system enforcing security, compliance (EU AI Act, SOX, HIPAA), and standards. |
| CI/CD Pipeline | Extends deployment infrastructure with prompt validation, output verification, and confidence scoring. |
| Observability Layer | Monitors prompt drift, hallucination rates, cost-per-generation, and latency distributions. |
| Feedback Loop | Captures outcomes from every stage, enabling continuous improvement of prompts and configurations. |
Visual Analysis — Charts & Comparisons
Traditional SDLC vs AI-Native SDLC
| Dimension | Traditional SDLC | AI-Native SDLC |
|---|---|---|
| Input Format | PRDs, User Stories, Tickets | Intent Specifications, Constraint Definitions |
| Primary Builder | Human Developer | LLM Agents + Human Oversight |
| Cycle Time | 2–4 week sprints | Hours to days |
| Testing | Post-development, manual-heavy | Concurrent, AI-generated, continuous |
| Architecture Review | Human committee, periodic | Policy engine, real-time enforcement |
| Knowledge Retention | Tribal, fragmented | Encoded in prompts, feedback loops |
| Scaling Model | Hire more engineers | Improve prompts, add agents |
| Defect Source | Logic errors, edge cases | Hallucination, prompt drift |
| Feedback Speed | Sprint retrospectives (weeks) | Real-time observability |
| Cost Driver | Headcount, infrastructure | Token consumption, model licensing |
AI SDLC Maturity Curve
The maturity curve follows an S-shape: slow initial adoption (Phase 1), rapid acceleration as intent-driven workflows prove viable (Phase 2), and plateau as agentic systems approach the frontier of safe automation (Phase 3).
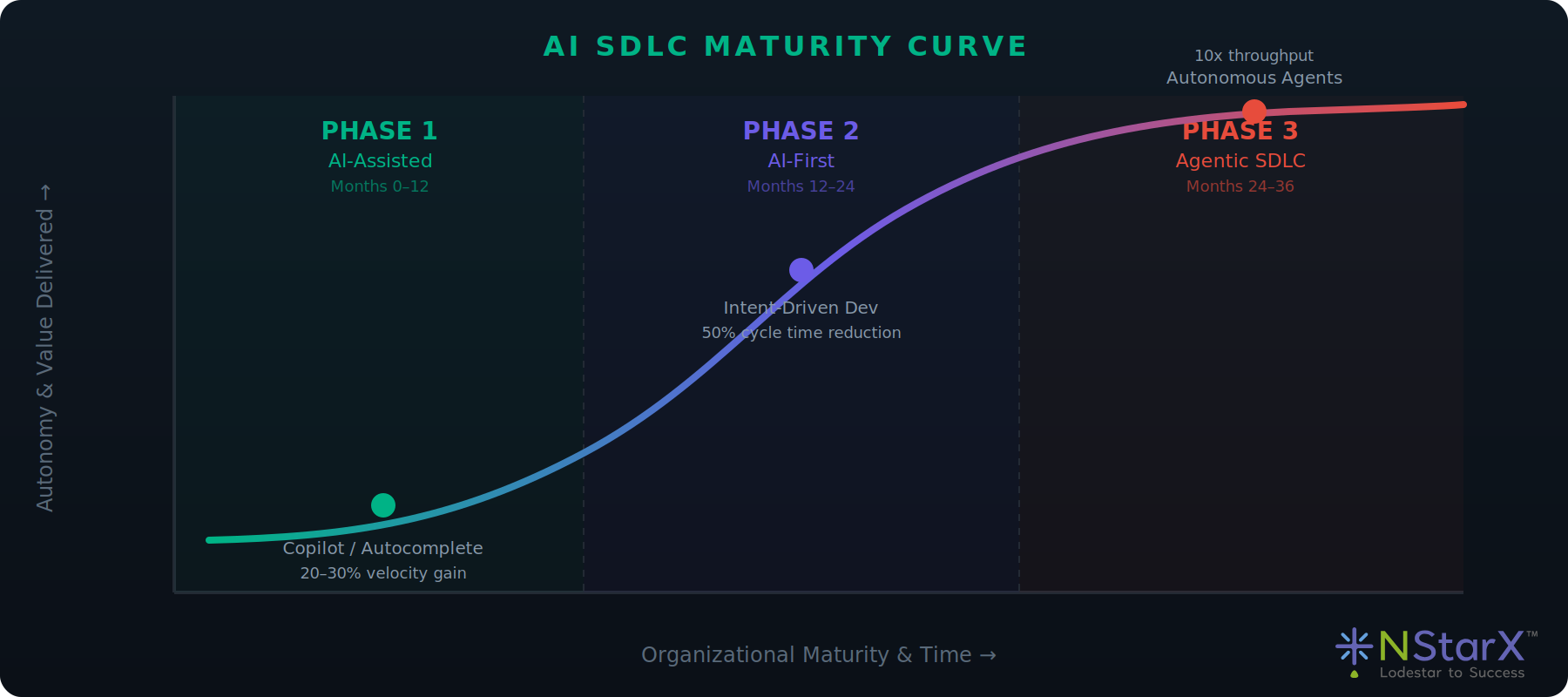
Figure 2: AI SDLC Maturity Curve
Cost vs Velocity: Traditional vs AI-Native
Traditional SDLC exhibits near-linear cost scaling. AI-native SDLC shows logarithmic cost behavior: after initial platform investment, each incremental unit of velocity costs less. The crossover typically occurs 12–18 months after Phase 1 begins.
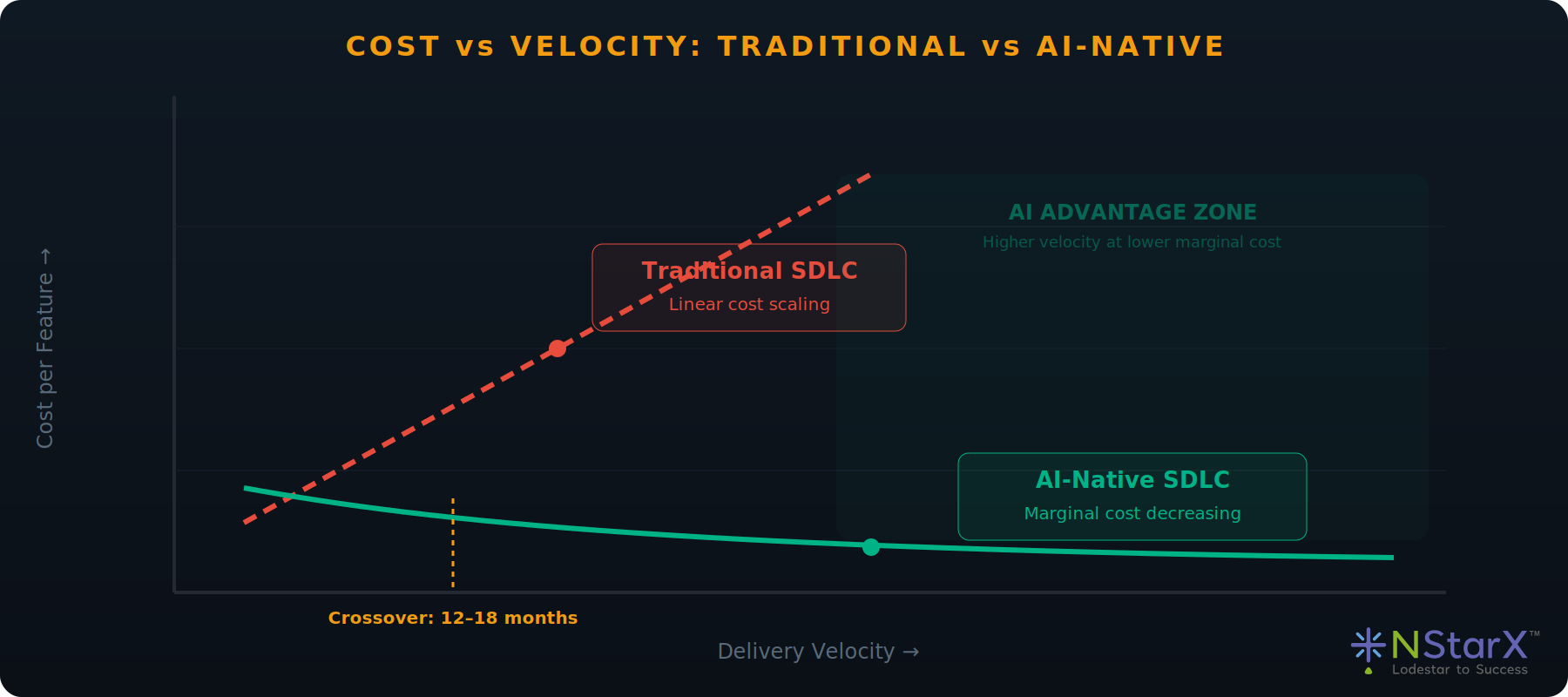
Figure 3: Cost vs Velocity Diagram
Risk Distribution: Traditional vs AI-Native
Traditional risks are dominated by human throughput constraints. AI-native risks are novel (hallucination, prompt drift) but more amenable to systematic mitigation through governance engines and observability.

Figure 4: Risk Distribution Diagram
Role Evolution in AI-Native SDLC
Before vs After: Role Transformation Matrix
| Traditional Role | AI-Native Role | Legacy Skills | New Skills Required |
|---|---|---|---|
| Developer | AI Orchestrator | Language mastery, debugging, data structures | Prompt engineering, constraint spec, output evaluation |
| QA Engineer | AI Validation Engineer | Manual testing, test automation, regression | Probabilistic validation, confidence scoring, adversarial testing |
| Architect | Constraint Designer | System design, pattern selection, capacity planning | Policy-as-code, machine-readable constraints, guardrail design |
| Product Manager | Intent Designer | User stories, PRDs, backlog grooming | Intent specification, acceptance criteria as prompts |
Organizational Restructuring Model
The AI-native organization restructures around three pillars: Intent & Design (WHY), Orchestration (HOW), and Validation & Governance (TRUST).
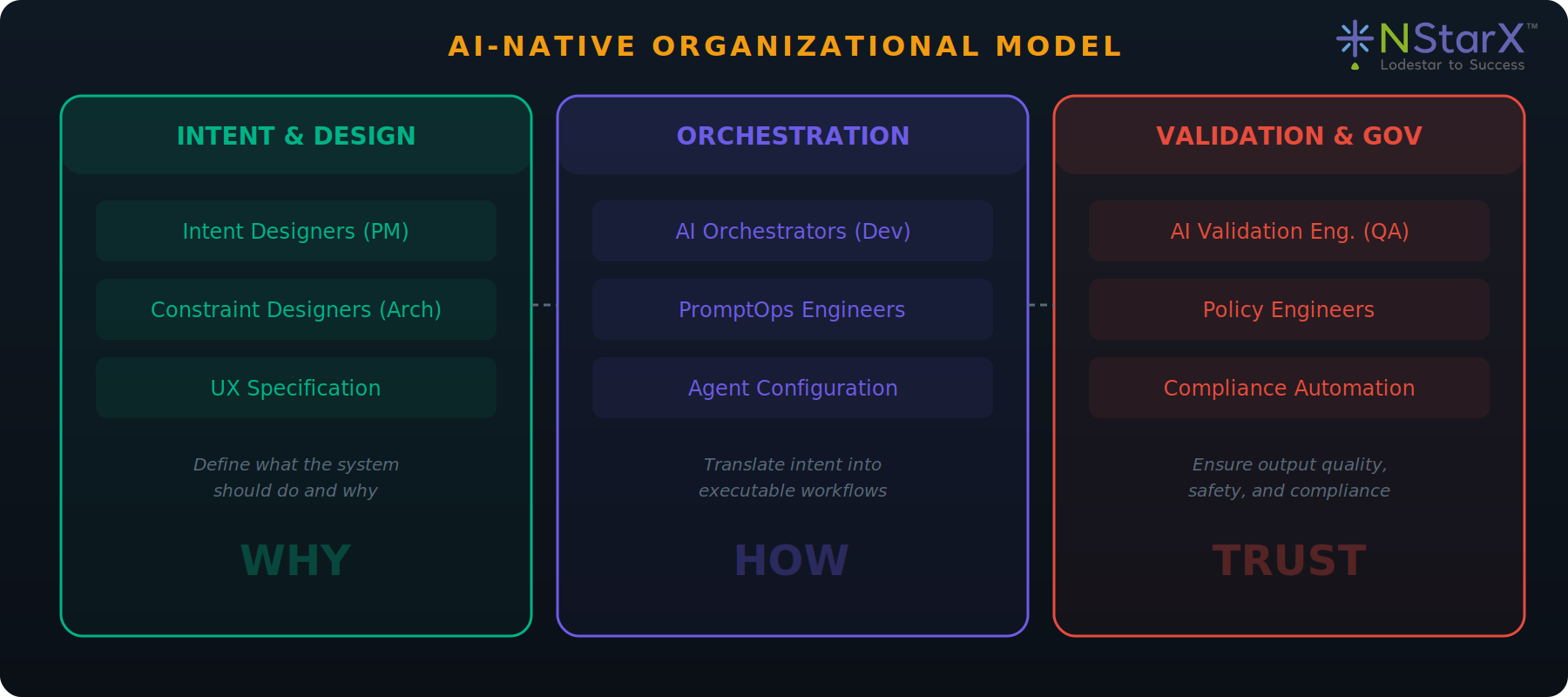
Figure 5: Organizational Model Diagram
Enterprise Adoption Roadmap

Figure 6: Adoption Timeline Diagram
Phase 1: AI-Assisted Development (Months 0–12)
| Dimension | Details |
|---|---|
| Tools & Platforms | Claude / Codex / GitHub Copilot, IDE integrations, basic prompt management, existing CI/CD with AI-generated PR summaries |
| Org Changes | Designate 2–3 PromptOps pioneers. Create AI enablement guild. No org restructuring yet. |
| KPIs | 20–30% velocity improvement. 15% code review turnaround improvement. Baseline hallucination measurement. |
| Risks | Shadow AI usage without governance. Inconsistent prompt quality. IP uncertainty. |
| Investment | $500K–$2M: Tooling ($200K–$800K), training ($100K–$300K), governance ($200K–$500K), 1–2 FTEs. |
Phase 2: AI-First SDLC (Months 12–24)
| Dimension | Details |
|---|---|
| Tools & Platforms | LLM orchestration platform, Policy-as-Code engine, AI test generation, PromptOps platform with versioning |
| Org Changes | Restructure squads with PromptOps engineers. Create Constraint Designer role. Establish AI Governance Board. |
| KPIs | 50% time-to-production reduction. 60% AI-generated test coverage. Prompt reuse rate >40%. |
| Risks | Organizational resistance. Integration complexity. Model vendor lock-in. Governance gaps. |
| Investment | $2M–$5M: Platform ($1M–$2M), change mgmt ($500K–$1M), governance ($300K–$800K). |
Phase 3: Agentic SDLC (Months 24–36)
| Dimension | Details |
|---|---|
| Tools & Platforms | Multi-agent orchestration, autonomous planning agents, self-healing infrastructure, advanced AI observability |
| Org Changes | Fully restructured org around Intent/Orchestration/Validation pillars. PromptOps as core discipline. |
| KPIs | 10x feature throughput. MTTR <15 min. 80%+ autonomous incident resolution. Cost/feature −60–70%. |
| Risks | Autonomous agent failure modes. Regulatory scrutiny. Skills erosion. Competitive exposure. |
| Investment | $5M–$10M: Agent infra ($2M–$4M), org transformation ($1M–$2M), security ($1M–$2M). |
Governance Model for AI-Native SDLC
The governance framework is built on three pillars — Prompt Governance, Model Risk Management, and Security Validation — bounded above by compliance requirements and below by human oversight gates.
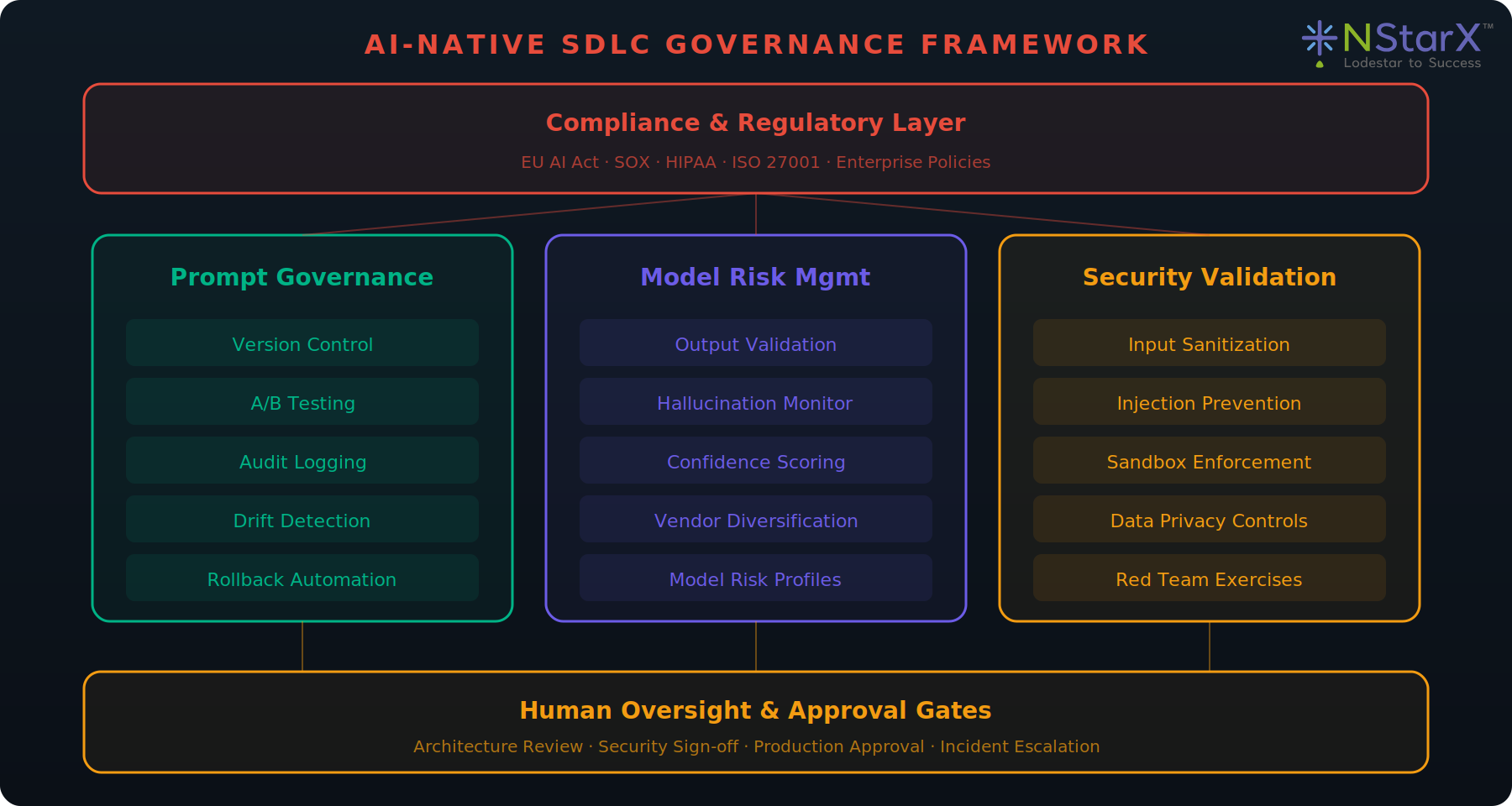
Figure 7: Governance Framework Diagram
Prompt Governance
Every prompt is a versioned artifact stored in a dedicated repository. Changes go through pull request review. Prompts are tested against regression suites before deployment. A/B testing infrastructure allows gradual rollout. Drift detection monitors output quality over time.
Model Risk Management
Each model has a risk profile documenting failure modes, hallucination rates, and domain limitations. Output validation pipelines apply deterministic and probabilistic checks. Vendor concentration risk is managed through architectural abstraction.
Security Validation
All inputs are sanitized against injection patterns. Generated code executes in sandboxed environments. Data privacy controls ensure sensitive information is never included in prompts without authorization. Regular red-team exercises test AI-specific attack vectors.
Compliance Mapping
The EU AI Act requires specific documentation for high-risk AI systems. The governance engine maintains real-time mapping between AI capabilities and regulatory requirements. Automated compliance reports are generated for audit.
Enterprise Readiness Checklist
| # | Checklist Item | Status |
|---|---|---|
| 1 | Prompt version control system deployed and enforced | Pending |
| 2 | Model risk management framework approved by CISO | Pending |
| 3 | AI output validation pipeline integrated into CI/CD | Pending |
| 4 | EU AI Act compliance mapping complete | Pending |
| 5 | Hallucination detection active in observability layer | Pending |
| 6 | Human approval gates defined for production deployments | Pending |
| 7 | IP/licensing policy for AI-generated code ratified by legal | Pending |
| 8 | Data residency and privacy controls verified | Pending |
| 9 | Model vendor contingency plan documented | Pending |
| 10 | AI-specific incident response runbook published | Pending |
| 11 | Monthly prompt audit schedule established | Pending |
| 12 | Skills maintenance program implemented | Pending |
PromptOps: A New Engineering Discipline
PromptOps is the discipline of managing prompts as first-class engineering artifacts throughout their entire lifecycle — from authoring through deployment to continuous optimization. Just as DevOps transformed infrastructure management by treating configuration as code, PromptOps transforms AI interaction management by treating prompts as versioned, tested, monitored, and governed software components.
Prompt Lifecycle
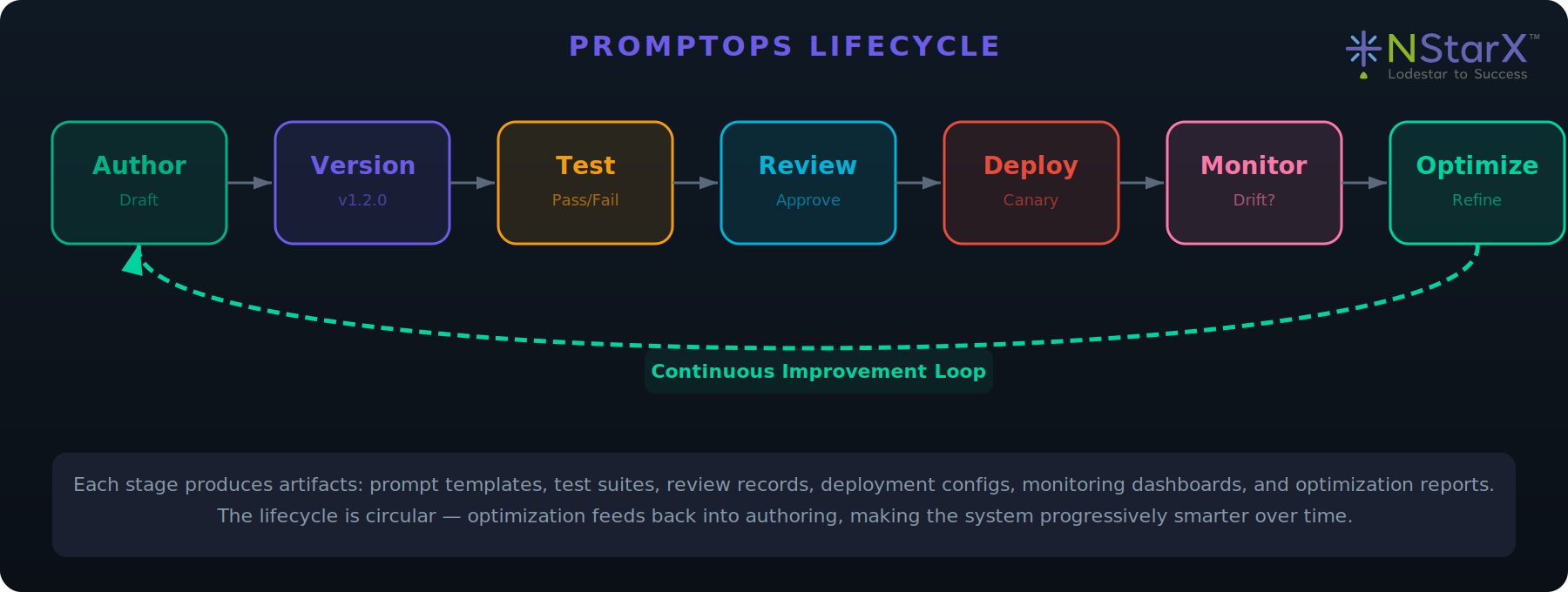
Figure 8: PromptOps Lifecycle Diagram
| Stage | Description |
|---|---|
| Author | Engineers craft prompts with clear intent, constraints, and examples. Prompts include metadata: owner, domain, model target. |
| Version | Prompts use semantic versioning (major.minor.patch). Branching/merging follows GitFlow conventions. |
| Test | Regression suites validate against expected outputs. Adversarial tests check for injection vulnerabilities. |
| Review | Peer review evaluates clarity, constraint completeness, security posture, and organizational alignment. |
| Deploy | Staged pipeline: dev → staging → canary → production. Feature flags enable gradual rollout. |
| Monitor | Continuous monitoring for drift, cost anomalies, latency spikes, and hallucination rates. |
| Optimize | Feedback-driven refinement of constraints, examples, model versions, and agent configurations. |
PromptOps Best Practices Checklist
| # | Best Practice | Priority |
|---|---|---|
| 1 | Treat prompts as production code — same review, testing, and deployment rigor | Critical |
| 2 | Use structured templates: system context, task, constraints, examples, output format | Critical |
| 3 | Maintain a prompt registry with search, tagging, and reuse metrics | Critical |
| 4 | Implement semantic versioning for all prompt artifacts | Critical |
| 5 | Build regression suites with 20+ test cases per critical prompt | Critical |
| 6 | Monitor prompt-to-output quality with automated scoring | High |
| 7 | Establish prompt ownership with named owners and review cadence | High |
| 8 | Document rationale: why this approach, alternatives considered, constraints | High |
| 9 | Use canary deployments for production prompt changes | High |
| 10 | Conduct monthly audits for drift, redundancy, and optimization | High |
The Agentic SDLC: 2030 Outlook
Three Pillars of the 2030 SDLC
| Pillar | Description | Impact |
|---|---|---|
| Fully Autonomous Agents | Agent swarms handle architecture evolution, optimization, and experimentation. Humans operate at strategic intent. | 3–5x productivity |
| Self-Healing Systems | Systems detect anomalies, generate and validate fixes, deploy autonomously. MTTR <5 min for known patterns. | −60–80% defect costs |
| Continuous Evolution | Discrete releases dissolve. Software adapts in real-time to users, regulations, and competition. | −70% time-to-market |
Financial Impact Model

Figure 9: Financial Impact Diagram
Competitive Asymmetry
The competitive advantage is asymmetric. Organizations at Phase 3 maturity operate at a fundamentally different speed. For mid-market technology companies, this translates to 200–500 basis points of margin improvement — the difference between market leadership and obsolescence. The first-mover window is narrow: 2026–2028.