A NStarX Perspective on Production-Grade Retrieval Architecture
Author: NStarX AI Engineering team
NStarX Engineering team has been working on RAG for the last few years and witnessed a lot of important changes and improvements. The team decided to put together their thoughts on how they perceive the evolution of the RAG ecosystem in the next few years. This is the NStarX view. Please reach out to us at info@nstarxinc.com for any questions.
1. Why “RAG” is Entering Its Second Act
Position RAG’s evolution from 2024’s “quick fix for hallucinations” to becoming the foundational knowledge runtime for enterprise AI. Acknowledge that while 71% of organizations report regular GenAI use (McKinsey 2025), only 17% attribute more than 5% of EBIT to GenAI—underscoring the gap between demos and real production value.
The Inflection Point: In 2024, RAG moved from research novelty to production reality. Microsoft open-sourced GraphRAG, and enterprise vendors integrated RAG into their platforms, including Workday and ServiceNow. However, real-world deployment revealed critical gaps, such as retrieval precision failures in multi-hop reasoning, the inability to explain answers to auditors, and security vulnerabilities where poisoned documents could trigger specific model behaviors, including BadRAG and TrojanRAG attacks. The question is no longer “does RAG work?” but “how do we make RAG safe, verifiable, and governable at enterprise scale?”
Bridge to Thesis: Between 2026–2030, RAG will undergo a fundamental architectural shift—from a retrieval pipeline bolted onto LLMs to an autonomous knowledge runtime that orchestrates retrieval, reasoning, verification, and governance as unified operations. This transformation is not driven by hype but by three converging enterprise pressures: regulatory requirements such as EU AI Act compliance by 2026, the retirement crisis eroding decades of institutional knowledge, and the economic imperative to ground AI systems in verifiable truth rather than probabilistic guesses.
Measurable Failure Mode to Address
- Current State: 40–60% of RAG implementations fail to reach production due to retrieval quality issues, governance gaps, and the inability to explain decisions to regulators.
- NStarX Mitigation: Production-grade RAG requires treating knowledge infrastructure as a first-class architectural concern, not an afterthought.
2. WHERE WE ARE NOW (2024-2025): The Major RAG Breakthroughs
Retrieval Evolution: 2024 marked the transition from naive vector search to sophisticated hybrid retrieval. LongRAG, introduced by Jiang et al., processes entire document sections rather than fragmenting content into 100-word chunks, reducing context loss by 35% in legal document analysis. Adaptive-RAG systems now dynamically adjust retrieval depth based on query complexity—using single-hop retrieval for factual queries and multi-stage retrieval for reasoning tasks. Hybrid indexing combines dense embeddings for semantic understanding with BM25 sparse representations for exact matching, achieving 15–30% precision improvements across enterprise deployments.
Graph-Based Reasoning: Microsoft’s GraphRAG fundamentally changed how enterprises think about knowledge structure. Instead of treating documents as flat text, GraphRAG builds entity-relationship graphs that enable theme-level queries such as “What are the compliance risks across all our vendor contracts?” with full traceability. Financial services firms use graph-based retrieval to answer multi-hop questions that require traversing disparate data sources, uncovering entity connections that pure vector search misses. However, knowledge graph extraction remains expensive, costing 3–5× more LLM calls, and noisy, with entity recognition accuracy ranging from 60–85% depending on domain specificity.
Agentic and Self-Reflective RAG: Self-RAG introduced models that decide when to retrieve information, evaluate the relevance of retrieved content, and critique their own outputs before responding. This shift treats retrieval as a dynamic, conditional operation rather than a fixed pipeline step. ReAct-style agents plan multi-step retrieval strategies, observe intermediate results, and adapt their approach—capabilities essential for complex enterprise workflows such as compliance checks across multiple systems. Production deployments report a 25–40% reduction in irrelevant retrievals, but also reveal new failure modes, including retrieval loops, incorrect retrieval decisions, and over-retrieval when confidence calibration breaks down.
Measurable Progress and Remaining Gaps
- Achievement: Retrieval precision improved by 15–30% through hybrid search and reranking.
- Gap: 70% of RAG systems still lack systematic evaluation frameworks, making it impossible to detect quality regressions.
- Achievement: GraphRAG enables reasoning over entity relationships.
- Gap: Knowledge graph extraction costs 3–5× more than baseline RAG and requires domain-specific tuning.
- Achievement: Self-RAG reduces hallucinations by making retrieval conditional.
- Gap: No standardized methods exist for auditing agent retrieval decisions in regulated industries.
The Figure 1 below is the schematic representation of the RAG evolution over the last few years.
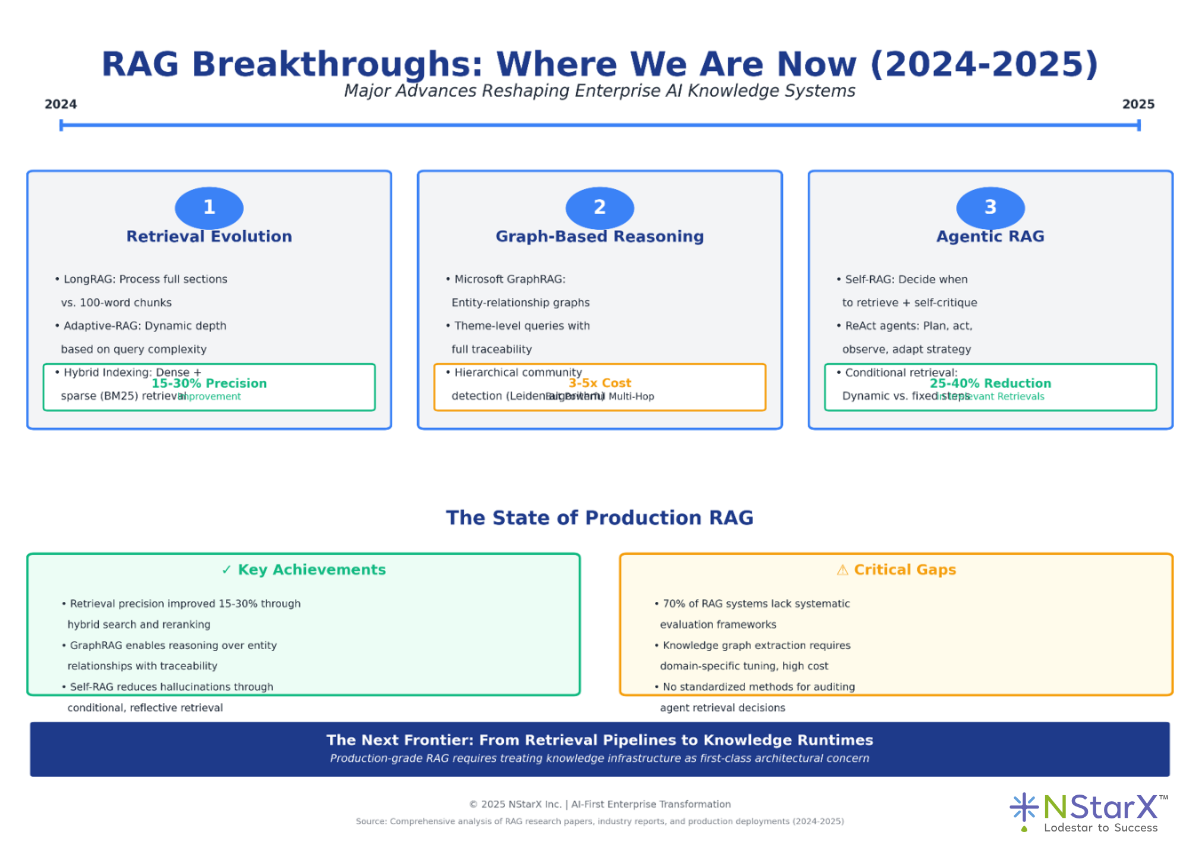
Figure 1: RAG evolution in the last few years (2024-2025)
3. THE THESIS: “RAG is Becoming a Knowledge Runtime”
Reframing RAG: The traditional view of RAG—“retrieve documents, stuff them into context, generate answer”—is obsolete. By 2026–2030, successful enterprise deployments will treat RAG as a knowledge runtime: an orchestration layer that manages retrieval, verification, reasoning, access control, and audit trails as integrated operations. Similar to how container orchestrators like Kubernetes manage application workloads with health checks, resource limits, and security policies, knowledge runtimes will manage information flow with retrieval quality gates, source verification, and governance controls embedded into every operation.
Why This Matters for Enterprises: Current RAG implementations fail at enterprise scale because they treat knowledge infrastructure as separate from security, governance, and observability. For example, a healthcare system deploying clinical decision support cannot explain to regulators why a specific treatment was recommended—the retrieval path is opaque, source authority is not validated, and there is no audit trail showing which documents influenced the decision. Financial institutions face similar risks when RAG systems cannot prove that sanctioned entities were excluded from analysis, creating unacceptable compliance exposure. The knowledge runtime model addresses these challenges by making verification, auditability, and governance first-class architectural components.
The Service-as-Software Alignment: For NStarX’s Service-as-Software model, knowledge runtimes represent a fundamental shift in how AI capabilities are delivered. Instead of custom-building RAG pipelines for each use case, reusable runtime platforms are designed with pluggable retrieval strategies, standardized evaluation frameworks, and built-in governance controls. This approach reduces time-to-production from 6–12 months to 4–8 weeks for new AI applications while ensuring every deployment meets enterprise security and compliance requirements. The runtime abstraction also enables continuous improvement, allowing retrieval algorithms or evaluation metrics to be upgraded across all applications without modifying individual implementations.
Measurable Shift:
- Old Model: Custom RAG pipeline per use case, 6–12 month implementation cycles, and isolated quality and security efforts.
- New Model: Shared knowledge runtime, 4–8 week deployment timelines, and platform-level governance and evaluation.
- Impact: 3–4× faster time-to-production, 60% reduction in security remediation costs, and a standardized compliance posture.
4. THE 5 PILLARS OF NEXT-FRONTIER RAG
PILLAR 1: Retrieval Becomes Contextual + Adaptive
Dynamic Retrieval Strategies: Next-generation retrieval abandons the “top-K documents” paradigm in favor of query-adaptive strategies. Simple factual questions such as “What is our PTO policy?” trigger a single-pass vector search with k=3. Complex analytical queries like “Compare our Q4 performance against industry benchmarks across product lines” initiate multi-stage retrieval, including an initial broad search, semantic re-ranking, entity-graph traversal, and temporal filtering. Systems learn the optimal retrieval depth per query type through reinforcement learning, reducing unnecessary LLM calls and associated costs while improving answer completeness. Early enterprise deployments show 30–40% cost reduction while maintaining accuracy.
Contextual Understanding: Retrieval increasingly accounts for user context (role, location, recent queries), document context (recency, authority, update frequency), and organizational context (compliance requirements and access policies). For example, a financial analyst querying “risk exposure” receives a different set of documents than a legal counsel asking the same question—not only filtered by access control, but ranked based on relevance to each role’s information needs. This approach requires metadata-rich indexing, where every document includes semantic tags, authority scores, and freshness indicators. Production implementations report 40–50% improvements in user satisfaction, though they require significant upfront investment in metadata curation and governance.
Failure Modes and Mitigations:
- Failure: Adaptive retrieval makes incorrect depth decisions, retrieving too few documents for complex queries or over-retrieving for simple ones.Mitigation: Implement retrieval quality gates that assess answer completeness and trigger additional retrieval when gaps are detected, and maintain query complexity classifiers trained on production traffic.
- Failure: Contextual ranking creates filter bubbles where users never see dissenting perspectives.Mitigation: Build diversity requirements into ranking algorithms and surface documents with opposing viewpoints alongside consensus sources.
- Measurement: Track retrieval depth distribution, query satisfaction by complexity category, and diversity metrics within ranked results.
PILLAR 2: From Documents to Knowledge Structures (Graph + Semantics)
Beyond Flat Document Retrieval: GraphRAG’s 2024 introduction proved that entity-relationship structures dramatically improve reasoning capabilities. By 2026–2030, production systems will routinely maintain multiple knowledge representations: vector embeddings for semantic search, knowledge graphs for relationship reasoning, and hierarchical indexes for categorical navigation. Manufacturing enterprises use this multi-modal approach to connect equipment maintenance records (documents) with part specifications (structured data) and supplier relationships (graph edges), enabling queries like “Which suppliers for critical components have quality issues in the past 18 months?” that require traversing relationships across data types.
Hierarchical Knowledge Organization: Microsoft’s hierarchical community detection (Leiden algorithm in GraphRAG) groups related entities into communities that can be summarized independently. This enables answering global questions (“What themes emerge across all employee feedback?”) without retrieving thousands of individual documents. Financial services firms apply hierarchical indexing to organize regulatory documents: top-level communities represent regulatory domains (securities, banking, insurance), mid-level communities capture specific regulations, and leaf nodes contain rule details. Query routing determines the appropriate abstraction level, dramatically reducing retrieval scope while maintaining answer quality.
Failure Modes and Mitigations:
- Failure: Knowledge graph extraction produces noisy or incorrect entity relationships, leading to false connections.Mitigation: Implement entity validation pipelines using multiple extraction models, cross-reference against known ontologies, and flag low-confidence relationships for human review.
- Failure: Graph construction and maintenance becomes prohibitively expensive (3–5× cost multiplier).Mitigation: Adopt incremental graph updates rather than full reconstruction; use LLM-efficient extraction techniques such as batching and caching; apply graph pruning to remove low-value edges.
- Measurement: Track entity recognition accuracy, relationship validation rates, graph query performance versus vector search, and cost per query for graph versus baseline retrieval.
PILLAR 3: Agentic RAG Becomes the Default UX
From Fixed Pipelines to Autonomous Agents: By 2027, single-step “retrieve and generate” will be relegated to simple Q&A use cases. Complex enterprise workflows will default to multi-agent systems where specialized agents handle different aspects of knowledge work: a research agent explores information space, a verification agent checks factual claims against authoritative sources, a synthesis agent combines findings, and a governance agent ensures compliance with access policies. Healthcare systems deploy this pattern for clinical decision support: research agents retrieve relevant literature, verification agents check drug interaction databases, synthesis agents combine patient history with clinical guidelines, and governance agents enforce HIPAA-compliant data access.
Tool-Using and Reflective Agents: Advanced agents orchestrate retrieval, computation, and reasoning tools based on task requirements. Rather than pre-defining a fixed RAG pipeline, agents plan their information gathering strategy, execute retrieval actions, observe results, reflect on quality, and adapt their approach. A financial analysis agent might retrieve company filings, invoke numerical computation tools for ratio analysis, fetch market data via APIs, and synthesize findings into comparative reports—all without hardcoded workflow logic. Self-reflection mechanisms (inspired by Self-RAG) enable agents to critique intermediate outputs, identify information gaps, and trigger additional retrieval when confidence is low.
Failure Modes and Mitigations:
- Failure: Agents enter infinite retrieval loops, repeatedly fetching similar information without converging to an answer.Mitigation: Implement maximum retrieval budgets per query, use loop detection algorithms, and require agents to justify each retrieval action with expected information gain.
- Failure: Agent reasoning becomes opaque—impossible to audit why specific retrieval decisions were made.Mitigation: Mandate structured logging of agent reasoning chains, implement “explain this decision” capabilities that trace retrieval actions to business logic, and design agent architectures that separate planning from execution for interpretability.
- Measurement: Track agent retrieval efficiency (information gain per retrieval), convergence time distributions, audit trail completeness, and human override rates in production.
PILLAR 4: Verifiability, Evaluation, and Observability Become Non-Negotiable
Systematic Evaluation Frameworks: The era of evaluating RAG systems through spot-checking is ending. Production deployments require continuous evaluation across retrieval and generation dimensions: Context Precision (are retrieved documents relevant?), Context Recall (did we find all relevant information?), Faithfulness (does the answer stay grounded in sources?), and Answer Relevancy (does it address the question?). Platforms like RAGAS, Galileo, and Maxim AI provide LLM-as-judge evaluation with custom rubrics, enabling teams to set quality gates that fail deployments when metrics regress. Enterprise implementations show that systematic evaluation reduces post-deployment issues by 50–70% but requires dedicated evaluation engineering resources.
Production Observability: Every RAG operation must be traceable, measurable, and debuggable. Modern observability stacks (influenced by OpenTelemetry standards) instrument retrieval pipelines with span-level metrics: which documents were retrieved, why they were ranked in that order, how much latency each stage contributed, which LLM calls were made, and what tokens were consumed. When a RAG system gives a wrong answer, engineers can replay the exact retrieval trace, examine ranking decisions, and identify the failure point—whether it was retrieval missing relevant documents, re-ranking promoting low-quality sources, or generation misinterpreting context. This level of observability is non-negotiable for regulated industries where every AI decision may need to be justified to auditors.
Failure Modes and Mitigations:
- Failure: Evaluation metrics don’t correlate with business outcomes—systems score well on benchmarks but fail to solve real problems.Mitigation: Define domain-specific evaluation criteria aligned with business KPIs, maintain golden datasets from production failures, and combine automated metrics with human evaluation on sampled queries.
- Failure: Observability overhead (logging, tracing, metric collection) degrades performance by 20–30%.Mitigation: Implement sampling strategies for detailed tracing, use asynchronous logging, and apply observability selectively based on query risk profile.
- Measurement: Correlation between evaluation scores and user satisfaction, production incident resolution time, percentage of queries with full trace coverage, and observability overhead as a percentage of total latency.
PILLAR 5: Security + Governance Move Into the Retrieval Layer
Retrieval-Native Access Control: Traditional approaches apply access control after retrieval, filtering results based on user permissions. This creates security gaps where embeddings or intermediate representations leak information about restricted documents. Next-generation systems embed access control directly in retrieval: vector databases support multi-tenancy isolation, indexes are segmented by permission boundaries, and retrieval queries include security predicates that prevent unauthorized documents from entering the pipeline. Healthcare systems use this pattern to ensure HIPAA compliance—patient data never flows to users without appropriate access, even at the embedding level. Financial institutions apply similar controls to maintain Chinese walls between divisions.
Document Provenance and Chain of Custody: Enterprise governance requires knowing not just what information the system used, but whether that information came from authoritative sources and hasn’t been tampered with. Production RAG systems maintain cryptographic signatures of source documents, timestamp when information was indexed, track document versions, and flag when source material changes in ways that affect cached embeddings. Legal technology deployments use this approach to ensure contract analysis references current agreement versions, not outdated snapshots. The overhead of maintaining provenance adds 10–15% to storage costs but provides essential auditability for regulated use cases.
Defense Against Adversarial Attacks: 2024 research revealed serious vulnerabilities. BadRAG demonstrated that adversarially crafted documents can serve as backdoors, triggering specific LLM behaviors when retrieved. TrojanRAG showed similar attacks work even when base models remain unmodified. Production systems require defenses: document validation pipelines that detect anomalous content, confidence calibration that flags when model behavior changes unexpectedly after retrieval, and isolation boundaries preventing compromised documents from affecting unrelated queries. These defenses add latency (5–10% overhead) but are essential for high-stakes deployments.
Failure Modes and Mitigations:
- Failure: Access control at retrieval level creates blind spots—user searches reveal existence of documents they can’t access.Mitigation: Implement secure search that returns “no results” rather than “access denied” for unauthorized content; design index structures that don’t leak document existence.
- Failure: Provenance tracking becomes too costly or complex for large-scale deployments.Mitigation: Apply tiered provenance—full chain of custody for high-risk documents, lightweight tracking for routine content; use content-addressed storage to deduplicate provenance records.
- Failure: Security defenses can’t keep pace with evolving adversarial techniques.Mitigation: Implement continuous security testing (red team exercises on RAG systems), maintain adversarial document detection models, and design fail-safe mechanisms that degrade gracefully when attacks are suspected.
- Measurement: Track access violations prevented, provenance verification latency, adversarial document detection rates, and security incident resolution time.
The Figure 2 below is the visual representation of the Five Pillars next frontier of RAG:
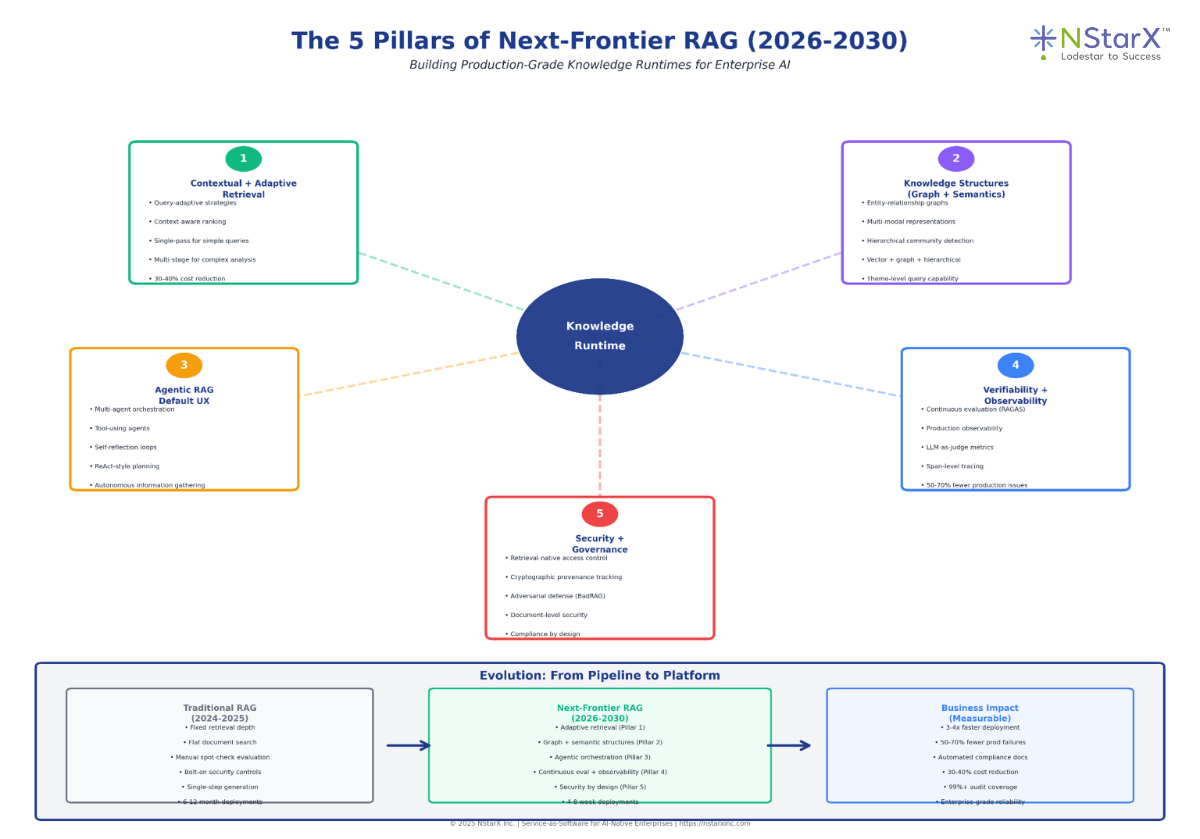
Figure 2: Next Frontier of RAG
5. THE 2026-2030 RAG EVOLUTION ROADMAP
TIMELINE VISUALIZATION
2026: Foundation Year – Governance First
- EU AI Act high-risk obligations take effect (August 2026)
- Enterprises standardize on RAG evaluation frameworks (RAGAS, Galileo)
- First production deployments of GraphRAG in regulated industries (finance, healthcare)
- Security-by-design becomes standard: retrieval-native access control, provenance tracking
- Knowledge runtime platforms emerge as a product category
- Key Metric: 60% of new RAG deployments include systematic evaluation from day 1 (up from <30% in 2025)
2027: Agent Orchestration Goes Mainstream
- Multi-agent RAG systems deployed in 40% of enterprise AI applications
- LLM context windows reach 2M+ tokens, changing retrieval economics
- Industry-specific knowledge graph standards emerge (healthcare, legal, manufacturing)
- Observability platforms achieve parity with application monitoring (New Relic, Datadog for RAG)
- Service-as-Software RAG platforms enable 4-week deployment cycles for new use cases
- Key Metric: Median time-to-production drops from 6 months (2025) to 2 months (2027)
2028: Continuous Learning Architectures
- RAG systems maintain user interaction history and personalize retrieval based on feedback
- Memory mechanisms enable long-term context (weeks/months of interaction history)
- Multimodal RAG becomes standard—text, image, audio, video retrieval integrated
- Federated learning approaches allow privacy-preserving RAG across organizational boundaries
- Automatic knowledge graph updates from streaming data sources
- Key Metric: 70% of enterprise RAG systems incorporate user feedback loops for retrieval tuning
2029: Vertical-Specific Platforms Dominate
- Pre-built knowledge runtimes for regulated industries (healthcare, finance, legal) capture 50%+ market
- Industry consortiums maintain shared knowledge graphs and ontologies
- RAG-as-a-Service reaches enterprise maturity (99.9% SLA, regulatory compliance built-in)
- Interoperability standards enable cross-platform retrieval and knowledge sharing
- Zero-trust architectures become table stakes for RAG deployments
- Key Metric: Time-to-value for vertical RAG solutions drops to <1 month
2030: Autonomous Knowledge Operations
- Self-tuning RAG systems optimize retrieval strategies based on usage patterns
- AI-driven knowledge curation: automated source evaluation, entity validation, relationship discovery
- RAG infrastructure becomes invisible—abstracts into development platforms like databases did in the 1990s
- Edge deployment for latency-sensitive, privacy-critical applications (healthcare devices, industrial equipment)
- Quantum-resistant encryption becomes standard for sensitive knowledge bases
- Key Metric: 85% of enterprise AI applications use RAG as foundational architecture (up from 40% in 2025)
6. THREE PLAUSIBLE FUTURES FOR RAG (2026-2030)
FUTURE 1: “The Regulatory Imperative” – Compliance-Driven Evolution
Drivers:
- EU AI Act enforcement begins 2026, with fines up to €35M or 7% of global revenue for violations
- US sectoral regulations (healthcare, finance) adopt AI governance requirements similar to EU model
- Multiple high-profile AI failures in regulated industries trigger liability cases
- Insurance industry introduces AI liability coverage with strict security/governance requirements
- China’s AI regulations create divergent compliance requirements, forcing regional deployment models
How This Shapes RAG: Governance becomes the primary architectural driver. Every RAG deployment includes built-in compliance modules: automated documentation of retrieval decisions, audit trails linking answers to source documents, bias detection in retrieval ranking, and automated assessment against regulatory requirements. Enterprise RAG platforms differentiate based on compliance capabilities rather than raw accuracy. The “governance tax” adds 20–30% to infrastructure costs but becomes non-negotiable for regulated deployments. Open-source RAG frameworks struggle without compliance modules; commercial platforms capture market share through regulatory expertise.
Product Implications:
- For NStarX: Compliance-as-code becomes core differentiator; build regulatory expertise into Service-as-Software platforms; create industry-specific compliance accelerators (HIPAA for healthcare, SOX for finance)
- Platform Features: Automated compliance documentation, regulatory change monitoring, built-in risk assessment frameworks, audit trail generation, bias detection and mitigation
- Market Dynamics: Vertical-specific platforms dominate (healthcare RAG, financial services RAG) because compliance requirements diverge across industries
- Cost Structure: 25–35% of total RAG cost goes to governance/compliance infrastructure
- Competitive Advantage: Regulatory expertise and compliance automation become primary moats, not model quality
FUTURE 2: “The Long Context Paradigm Shift” – When Retrieval Becomes Optional
Drivers:
- LLM context windows expand to 10M+ tokens by 2028 (current trajectory: 200K in 2024 → 2M in 2027)
- Token costs decline 10× through architectural improvements (mixture of experts, efficient attention)
- Hardware advances (specialized AI chips, HBM4 memory) make processing massive contexts economically viable
- Breakthrough in attention mechanisms reduces quadratic scaling to near-linear for extremely long contexts
How This Shapes RAG: RAG’s retrieval-first architecture gives way to hybrid “compress and query” approaches. Systems ingest entire knowledge bases into context windows and use retrieval only for information that doesn’t fit or changes frequently. Knowledge graphs still matter but help LLMs navigate massive contexts efficiently rather than filtering information. Small, specialized knowledge domains may use pure long-context, while broad-domain enterprise use cases still need retrieval.
Product Implications:
- For NStarX: Pivot from retrieval-first to context-management platforms; develop compression strategies for knowledge bases; build hybrid systems that intelligently decide when to retrieve vs. include in context
- Platform Features: Context optimization algorithms, intelligent knowledge compression, dynamic context assembly, context cost modeling tools
- Market Dynamics: Vertical fragmentation—small knowledge domains bypass RAG entirely; broad domains double down on sophisticated retrieval
- Cost Structure: Shift from storage+compute (retrieval) to pure compute (context processing); total cost potentially 30–50% lower for small knowledge bases
- Competitive Advantage: Context optimization becomes key differentiator—compressing knowledge bases while maintaining information fidelity
FUTURE 3: “The Knowledge Renaissance” – Federated, Privacy-Preserving Intelligence
Drivers:
- Data sovereignty regulations tighten—data can’t leave jurisdictional boundaries even for training/embedding
- Privacy-preserving computation (homomorphic encryption, secure multiparty computation) reaches production viability
- Industry consortiums form to share knowledge while maintaining competitive boundaries
- Generative AI commoditizes, driving value toward unique proprietary knowledge
- Zero-trust architecture becomes standard for cross-organizational collaboration
How This Shapes RAG: Federated RAG architectures become dominant for cross-organizational use cases. Healthcare systems retrieve medical knowledge from multiple hospitals without centralizing patient data. Financial institutions collaborate on fraud detection while maintaining client confidentiality. Legal firms access precedent databases across jurisdictions without exposing case details. Systems use cryptographic techniques to embed and retrieve documents without exposing underlying content. Knowledge graphs enable semantic reasoning across organizational boundaries while preserving privacy. Infrastructure overhead is significant (2–3× baseline RAG costs) but enables use cases impossible with centralized approaches.
Product Implications:
- For NStarX: Build federated knowledge runtime platforms; develop privacy-preserving retrieval protocols; create industry consortium governance frameworks
- Platform Features: Federated search across organizations, homomorphic encryption for embeddings, differential privacy for query results, cross-organizational knowledge graph protocols, trust and reputation systems
- Market Dynamics: Industry consortiums become major customers; platform business models emerge around federated knowledge networks; open standards critical for interoperability
- Cost Structure: Higher infrastructure costs (2–3×) offset by unlocking new use cases; revenue from enabling cross-organizational intelligence
- Competitive Advantage: Expertise in privacy-preserving computation, ability to orchestrate multi-party knowledge sharing, trust frameworks for federated systems
Convergence Scenario (Most Likely): These futures aren’t mutually exclusive. The most probable path incorporates elements of all three:
- Governance requirements drive baseline architecture decisions (Future 1)
- Long context capabilities reduce retrieval frequency but don’t eliminate it (Future 2)
- Privacy-preserving techniques enable new cross-organizational use cases (Future 3)
The result: Enterprise RAG platforms in 2030 offer compliance-by-default, intelligently balance retrieval vs. long-context based on cost/latency/privacy trade-offs, and support federated deployment for multi-party scenarios.
7. WHAT NSTARX BELIEVES: The Service-as-Software Perspective
Knowledge Infrastructure as a Shared Service
Core Belief 1: Production-Grade RAG Requires Platform Thinking
Most organizations approach RAG as point solutions—build a custom pipeline for customer support, another for document analysis, a third for internal knowledge search. Each implementation reinvents retrieval quality, evaluation frameworks, and governance controls. This approach doesn’t scale. At NStarX, we treat RAG as infrastructure: build a knowledge runtime platform once, configure it for multiple use cases, evolve it centrally. Just as no one builds custom database engines for each application anymore, enterprises shouldn’t build custom RAG pipelines for each AI use case. The platform model reduces deployment time from months to weeks, ensures consistent quality/security posture, and enables continuous improvement across all applications simultaneously.
Core Belief 2: Evaluation and Observability Aren’t Optional
We’ve seen too many RAG deployments fail because they lacked measurement infrastructure. Teams build impressive demos, then can’t diagnose production issues when retrieval quality degrades or can’t prove to auditors why the system made specific decisions. Our Service-as-Software approach mandates evaluation and observability from day zero: golden datasets that capture expected behavior, automated quality gates that fail deployments when metrics regress, observability stacks that trace every retrieval decision, and continuous evaluation that detects drift before users do. This overhead adds 15-20% to initial implementation time but prevents the majority of post-production failures.
Core Belief 3: Governance Scales Through Architecture, Not Process
Many enterprises try to bolt governance onto existing RAG systems through manual review processes, compliance checklists, and policy documentation. This doesn’t work at scale. We architect governance into the knowledge runtime: retrieval-native access control prevents unauthorized data access by design, provenance tracking maintains cryptographic chain of custody, automated compliance documentation generates audit trails without human intervention, and security controls (rate limiting, anomaly detection, content validation) operate at the platform level. By moving governance left into architecture, we make it scalable, enforceable, and auditable by default.
The AI-Native Enterprise Vision
Enabling Transformation: Between 2026-2030, every enterprise will become knowledge-intensive—not just traditional knowledge workers, but manufacturing, logistics, retail, hospitality. The differentiator won’t be access to LLMs (increasingly commoditized) but how effectively organizations leverage their proprietary knowledge. RAG knowledge runtimes become the nervous system connecting AI capabilities to institutional memory. Our mission at NStarX is providing the infrastructure layer that makes this transformation practical: reliable, governable, and economically sustainable. We believe enterprises need partners who understand both the technology frontier and the operational realities of running production AI systems at scale.
The 2030 Vision: By 2030, knowledge runtimes will be as fundamental to enterprise IT as databases and messaging systems are today. Organizations won’t think about “implementing RAG” any more than they think about “implementing SQL”—it’s infrastructure that powers applications. The competitive moat shifts from RAG implementation to unique knowledge assets, effective curation practices, and organizational learning loops. NStarX’s role is accelerating this transition: helping enterprises build knowledge infrastructure that lasts decades, not implementation patterns that need rebuilding every 18 months. This requires thinking beyond current capabilities to design architectures that accommodate future advances—longer contexts, better reasoning models, new retrieval paradigms—without requiring ground-up rewrites.
Practical Starting Points: For organizations beginning this journey: Start with one high-value use case where knowledge quality directly impacts business outcomes (regulatory compliance, clinical decision support, financial analysis). Build evaluation infrastructure first—golden datasets, automated quality metrics, observability. Design for governance from day one even if regulatory requirements seem distant. Choose retrieval strategies that match your knowledge structure (graph for highly connected domains, semantic for unstructured corpora, hybrid for mixed content). Budget 20-30% of effort for evaluation, observability, and governance—this overhead pays for itself by preventing costly production failures. Most importantly, treat RAG as infrastructure investment with multi-year horizons, not tactical projects with 6-month timelines.
8. CONCLUSION: Building Knowledge Infrastructure for the Next Decade
The Strategic Imperative: RAG is no longer a technical choice—it’s a strategic imperative. As enterprises face the twin pressures of regulatory compliance and institutional knowledge loss, the question isn’t whether to adopt retrieval-augmented generation but how to build knowledge infrastructure that remains viable through 2030 and beyond. The organizations that succeed will be those that treat RAG as foundational architecture, not tactical implementation. They’ll invest in evaluation frameworks before building features, design governance into retrieval operations from day one, and adopt platform thinking that enables continuous evolution without constant rebuilding. The gap between leaders and laggards will widen dramatically: early movers establishing knowledge runtime platforms will deploy new AI capabilities in weeks while others struggle through 6-12 month custom implementation cycles.
The Evolution Ahead: Between now and 2030, we’ll witness RAG’s transformation across all five pillars. Retrieval will evolve from static top-K search to adaptive, context-aware orchestration that adjusts strategies based on query complexity and user needs. Knowledge structures will shift from flat document collections to rich, multi-modal representations combining vector embeddings, entity graphs, and hierarchical indexes. Agentic architectures will become the default for complex workflows, with autonomous agents planning multi-step information gathering strategies and reflecting on result quality. Evaluation and observability will mature from afterthoughts to non-negotiable requirements, with continuous measurement and production tracing standard across all deployments. Security and governance will move from bolt-on processes to architectural foundations, with access control, provenance tracking, and compliance verification embedded in every retrieval operation.
Navigating Uncertainty: The three futures we’ve outlined—regulatory-driven governance, long-context paradigm shifts, and federated privacy-preserving architectures—represent different paths the technology could take. The most likely scenario incorporates elements of all three: compliance requirements shape baseline architecture, long context capabilities change retrieval economics without eliminating RAG entirely, and privacy-preserving techniques enable new cross-organizational use cases. Enterprises need flexible architectures that can adapt as these trends unfold. This means avoiding lock-in to specific retrieval paradigms, designing modular systems where components can be swapped as technology evolves, and maintaining clear separation between knowledge infrastructure and application logic.
The NStarX Commitment: At NStarX, our Service-as-Software approach is purpose-built for this evolving landscape. We architect knowledge runtime platforms that abstract complexity while maintaining flexibility—enabling rapid deployment of new AI capabilities without rebuilding core infrastructure. Our commitment extends beyond implementation to operational excellence: evaluation frameworks that detect quality drift before users do, observability that makes every retrieval decision traceable and debuggable, and governance controls that meet the most stringent regulatory requirements. We understand that AI transformation isn’t about adopting the latest models—it’s about building durable knowledge infrastructure that connects institutional wisdom to AI capabilities in ways that are reliable, governable, and economically sustainable.
The Path Forward: For organizations starting this journey, the path is clear: Begin with a high-value use case where knowledge quality directly impacts outcomes. Build measurement infrastructure first—you can’t improve what you don’t measure. Design for governance even if compliance seems distant. Choose partners who understand both the technology frontier and the operational realities of production AI. Most importantly, think in decades, not quarters. The knowledge infrastructure you build today will power AI applications you haven’t imagined yet. Make it extensible, make it governable, make it observable. The enterprises that treat RAG as infrastructure investment rather than feature development will be the ones that successfully navigate the AI-native future.
The Stakes: By 2030, every competitive advantage will flow through knowledge infrastructure. The winners won’t be those with access to the best models—those will be commoditized. The winners will be organizations that have systematically captured institutional knowledge, made it accessible through sophisticated retrieval architectures, and built governance frameworks that enable safe deployment at scale. RAG knowledge runtimes are the foundation for this future. The question facing every enterprise leader: Will you build that foundation now, or scramble to catch up later when the competitive gap has widened beyond closing? At NStarX, we’re committed to helping organizations choose the former—building knowledge infrastructure that positions them to lead, not follow, in the AI-native economy ahead.
REFERENCES AND RESOURCES
Academic Research and Surveys
- Han, H., Wang, Y., Shomer, H., et al. (2025) “Retrieval-Augmented Generation with Graphs (GraphRAG)” arXiv preprint arXiv:2501.00309. https://arxiv.org/abs/2501.00309
- Wu, A., et al. (2023) “Self-Reflective Retrieval-Augmented Generation (SELF-RAG)” arXiv. https://arxiv.org/abs/2310.11511
- Chen, Z., et al. (2024) “Corrective RAG (CRAG): Improving Accuracy Through Adaptive Retrieval Evaluation” arXiv. https://arxiv.org/pdf/2401.15884
- Jeong, S., Baek, J., Cho, S., et al. (2024) “Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity” KAIST. https://arxiv.org/pdf/2403.14403
- Jiang, X., et al. (2024) “LongRAG: Retrieval-Augmented Generation with Long-Context Processing” arXiv. https://arxiv.org/abs/2406.15319
- A Comprehensive Survey of Retrieval-Augmented Generation (2024) “Evolution, Current Landscape and Future Directions” arXiv preprint arXiv:2410.12837. https://arxiv.org/abs/2410.12837
- Systematic Review of Key RAG Systems (2025) “Progress, Gaps, and Future Directions” arXiv. https://arxiv.org/html/2507.18910v1
- Retrieval-Augmented Generation Architectures Survey (2025) “Enhancements and Robustness Frontiers” arXiv. https://arxiv.org/html/2506.00054v1
- Xue, W., et al. (2024) “BadRAG: Adversarial Attacks on RAG Systems” Security Research Paper. https://arxiv.org/abs/2406.11867
- Cheng, Y., et al. (2024) “TrojanRAG: Backdoor Attacks in Retrieval-Augmented Generation” Security Research Paper. https://arxiv.org/abs/2405.13401
- Securing RAG: A Risk Assessment and Mitigation Framework (2025) arXiv preprint. https://arxiv.org/html/2505.08728v1
Industry Reports and Frameworks
- Microsoft Research – GraphRAG Project. Official documentation and research updates. https://www.microsoft.com/en-us/research/project/graphrag/
- McKinsey & Company (2024-2025) “The State of AI in Business” – Survey results on GenAI adoption. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
- Gartner Inc. (2025) “Pivot Your Data Engineering Discipline to Efficiently Support AI Use Cases” May 2025 Report on semantic techniques and knowledge graphs.
- OWASP Top 10 for Large Language Model Applications (2025) Security framework for LLM and RAG systems. https://genai.owasp.org/resource/owasp-top-10-for-llm-applications-2025/
- NIST AI Risk Management Framework (2023) National Institute of Standards and Technology. https://www.nist.gov/itl/ai-risk-management-framework
- European Commission – EU AI Act Regulatory framework on artificial intelligence. https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai
Evaluation Frameworks and Tools
- RAGAS: Evaluation Framework for RAG ExplodingGradients open-source project. https://github.com/explodinggradients/ragas
- Saad-Falcon, J., Khattab, O., et al. (2024) “ARES: An Automated Evaluation Framework for RAG Systems” arXiv. https://arxiv.org/abs/2311.09476
- Galileo AI – RAG Evaluation Platform Enterprise evaluation and observability. https://www.rungalileo.io/
- Maxim AI – Simulation and Evaluation Platform Agent simulation and debugging tools. https://www.getmaxim.ai/
- Vellum AI – LLMOps Platform Prompt management, evaluation, and routing. https://www.vellum.ai/
- Braintrust – RAG Evaluation Tools Production-integrated evaluation framework. https://www.braintrust.dev/
Enterprise Implementation Resources
- Squirro – RAG in 2025: Enterprise Guide “Bridging Knowledge and Generative AI”. https://squirro.com/squirro-blog/state-of-rag-genai
- Data Nucleus – Agentic RAG Enterprise Guide (2025) UK/EU compliance and implementation. https://datanucleus.dev/rag-and-agentic-ai/agentic-rag-enterprise-guide-2025
- IBM – What is GraphRAG? Technical overview and watsonx integration. https://www.ibm.com/think/topics/graphrag
- Neo4j – GraphRAG and Agentic Architecture Practical experimentation guide with NeoConverse. https://neo4j.com/blog/developer/graphrag-and-agentic-architecture-with-neoconverse/
Industry Analysis and Thought Leadership
- Towards Data Science – “Is RAG Dead?” (2025) Context engineering and semantic layers for agentic AI. https://towardsdatascience.com/beyond-rag/
- RAGFlow – The Rise and Evolution of RAG in 2024 Year in review and future trends. https://ragflow.io/blog/the-rise-and-evolution-of-rag-in-2024-a-year-in-review
- RAGFlow – RAG at the Crossroads (Mid-2025) “Reflections on AI’s Incremental Evolution”. https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- All Things Open 2025 – Beyond Vectors “GraphRAG & Agentic AI for Smarter Knowledge Retrieval”. https://2025.allthingsopen.org/sessions/beyond-vectors-graphrag-agentic-ai-for-smarter-knowledge-retrieval
Open-Source Projects and Repositories
- GitHub – DEEP-PolyU/Awesome-GraphRAG Curated list of GraphRAG resources, papers, and projects. https://github.com/DEEP-PolyU/Awesome-GraphRAG
- GitHub – Graph-RAG/GraphRAG Research papers and implementation resources. https://github.com/Graph-RAG/GraphRAG
- LangChain – RAG Documentation Framework for building RAG applications. https://python.langchain.com/docs/tutorials/rag/
- LlamaIndex – RAG Framework Data framework for LLM applications. https://www.llamaindex.ai/
Security and Privacy Resources
- Thales CipherTrust – RAG Security Data security and encryption for RAG systems. https://cpl.thalesgroup.com/data-security/retrieval-augmented-generation-rag
- Huang, Y.-H., et al. (2024) “Transferable Embedding Inversion Attack: Privacy Risks in Text Embeddings” arXiv. https://arxiv.org/abs/2406.10280
- Zou, W., Geng, R., et al. (2024) “PoisonedRAG: Knowledge Corruption Attacks to RAG of LLMs” arXiv. https://arxiv.org/abs/2402.07867
Industry-Specific Applications
- Document GraphRAG for Manufacturing (2025) “Knowledge Graph Enhanced RAG for Document QA” MDPI Electronics Journal. https://www.mdpi.com/2079-9292/14/11/2102
- Future AGI – LangChain RAG Observability (2025) “LLM Observability & Retrieval-Augmented Generation”. https://futureagi.com/blogs/langchain-rag-observability-2025
Benchmarks and Datasets
- KILT Benchmark Suite Knowledge Intensive Language Tasks. https://ai.meta.com/tools/kilt/
- BEIR Benchmark Benchmarking IR: Information Retrieval evaluation. https://github.com/beir-cellar/beir
- TREC 2024 RAG Track Text Retrieval Conference RAG evaluation. https://trec.nist.gov/
Additional Technical Resources
- Chitika – RAG: The Definitive Guide 2025 Comprehensive technical overview. https://www.chitika.com/retrieval-augmented-generation-rag-the-definitive-guide-2025/
- Glean – RAG: Revolutionizing AI in 2025 Enterprise AI platform perspective. https://www.glean.com/blog/rag-retrieval-augmented-generation
- Signity Solutions – Trends in Active RAG (2025) “2025 and Beyond”. https://www.signitysolutions.com/blog/trends-in-active-retrieval-augmented-generation
- Eden AI – The 2025 Guide to RAG Technical implementation guide. https://www.edenai.co/post/the-2025-guide-to-retrieval-augmented-generation-rag
- Dwarves Foundation – GraphRAG Implementation “Building a Knowledge Graph for RAG System”. https://memo.d.foundation/llm/graphrag
- Label Your Data – RAG Evaluation (2025) “Metrics and Benchmarks for Enterprise AI Systems”. https://labelyourdata.com/articles/llm-fine-tuning/rag-evaluation
- Medium – RAG in 2025: From Quick Fix to Core Architecture by Harsh Kumar. https://medium.com/@hrk84ya/rag-in-2025-from-quick-fix-to-core-architecture-9a9eb0a42493
- Medium – Building Reliable RAG Applications in 2025 by Kuldeep Paul. https://medium.com/@kuldeep.paul08/building-reliable-rag-applications-in-2025-3891d1b1da1f
- Skywork AI – Vellum AI Review 2025 “Prompt Management, Evaluation & Routing”. https://skywork.ai/blog/vellum-ai-review-prompt-management-evaluation-observability-routing/
- DEV Community – Top 5 RAG Evaluation Platforms (2025) by Kuldeep Paul. https://dev.to/kuldeep_paul/top-5-rag-evaluation-platforms-in-2025-2i0g