NStarX Engineering team shares its experience with modernization of the data architecture to support current and future AI workloads
Executive Summary
Only 22% of organizations believe their current architecture can support AI workloads without modifications, making unified data platforms a top investment priority according to recent research by Databricks and Economist Impact. As enterprises rush to adopt artificial intelligence and generative AI technologies, they’re discovering a fundamental truth: their existing data architectures, designed for traditional business intelligence and reporting, simply cannot handle the demands of modern AI workloads.
Enterprise AI strategies will center on post-training and specialized AI agents, with infrastructure emerging as the biggest investment area as companies race to build AI agent systems. Data observability platforms are crucial for validating the quality and reliability of data fueling advanced analytical models, yet most organizations lack the integrated monitoring and governance frameworks necessary to ensure AI reliability at scale. Despite the promise, 47% of CIOs indicate that AI has not met their return on investment expectations, highlighting the challenges of deployment, unpredictable costs, and potential negative behaviors.
This comprehensive guide explores why current data architectures are inadequate, examines real-world modernization successes and failures, and provides actionable insights for building AI-ready data infrastructure.
Why Current Data Architectures Are Inadequate for AI Workloads
The Fundamental Mismatch
Traditional data architectures revolve around centralized data lakes or warehouses. These systems consolidate data into a single repository, enabling analytics at scale. However, this approach creates several critical bottlenecks for AI workloads:
Architectural Limitations:
- Batch Processing Focus: Traditional data pipelines operate in batches—processing data once an hour or even once a day. That’s fine for dashboards and quarterly reports, but insufficient for AI systems that need to make decisions in milliseconds
- Centralization Bottlenecks: Centralization often leads to bottlenecks, slow onboarding, and poor data discoverability—especially as the volume and variety of data grow
- Schema Rigidity: Legacy data warehouses impose fixed schemas that cannot accommodate the diverse, unstructured data types required for modern AI applications
AI-Specific Requirements:
Next-generation AI demands something more: real-time responsiveness, richer context, greater scalability, and tighter integration between data and model lifecycles. As companies evolve how they navigate scaling laws, they’re shifting focus from pre-training and bigger models to post-training techniques. Companies are building agentic AI agent systems, composed of multiple models, techniques and tools that work together to improve efficiency and outputs. Modern AI systems require:
- Real-time Data Processing: AI models need access to streaming data for real-time inference and continuous learning
- Multi-modal Data Support: AI applications must process text, images, video, audio, and sensor data simultaneously
- High-quality, Governed Data: AI systems depend on high-quality data that is well-understood, well-governed, and reusable across teams
- Elastic Compute Resources: AI workloads require massive, variable compute power for training and inference
- Agentic Workflow Support: AI agents must be able to work outside the boundaries of proprietary IT environments and interact with many data sources, LLMs and other components to deliver accurate and reliable outputs
The Scale of the Problem and ROI Challenges
In banking, while 70 percent of financial institutions we surveyed have had a modern data-architecture road map for 18 to 24 months, almost half still have disparate data models. The majority have integrated less than 25 percent of their critical data in the target architecture.
This implementation gap highlights a critical issue: organizations recognize the need for modernization but struggle with execution. The challenges are compounded by disappointing returns on AI investments. According to recent Gartner research, 47% of CIOs indicated that AI has not met their return on investment expectations, highlighting the challenges of deployment, unpredictable costs, and potential negative behaviors.
Despite these challenges, the urgency remains high. Generative AI is expected to be embedded in more than 80% of independent software vendor enterprise applications by 2026, a significant increase from less than 5% in 2024. Data Quality issues have risen by 15 hours between 2022 and 2023. In 2023 and beyond, 25% or more of revenue will be subjected to Data Quality issues.
Real-World Examples of Modernization Success and Failure
Success Stories
PayPal’s Data Warehouse Modernization
PayPal described their success story of moving into cloud-native infrastructure to gain real-time visibility and analytics capabilities. The outcome of the data warehouse modernization and building a cloud-native architecture: Reduce the time for readouts from 12 hours to a few seconds. PayPal implemented a streaming application that ingests events from Kafka directly to BigQuery, which became critical for their analytical operations.
PhonePe’s Infrastructure Scale-up
Acceldata helped top digital payments business PhonePe increase its data infrastructure by 2000%, lowering expenses and enhancing system dependability. This transformation enabled PhonePe to handle massive transaction volumes while maintaining data quality and governance.
Airbnb’s Data Democratization
Airbnb, the vacation rental marketplace, revolutionized its data architecture to foster data democratization. They developed an internal tool, “Airflow,” to streamline and visualize their data workflows. It allows all team members to access, understand, and use data, promoting a data-driven culture.
Confluent’s Internal Modernization
Confluent eats its dog food to modernize the internal data warehouse pipeline, demonstrating how streaming ETL and real-time customer analytics can transform internal operations while proving the technology’s value.
Failure Patterns and Lessons Learned
Common Failure Points:
- Overplanning Paralysis: Traditional architecture design and evaluation approaches may paralyze progress as organizations overplan and overinvest in developing road-map designs and spend months on technology assessments and vendor comparisons that often go off the rails
- Legacy System Constraints: A prominent U.S.-based multinational food and beverage company operating in over 200 countries encountered difficulties due to its dependence on outdated systems and on-premises databases. These legacy systems were costly to maintain and impeded performance enhancements
- Testing and Development Oversights: We’ve been in situations where we’ve left the development environment out of the project’s scope, thinking the client had it under control. After diving in, we were then surprised to find nothing was ready on the development environment front
Key Success Factors:
The perfect client is one who has already figured out their total cost of ownership and has clear reasons for why they want to migrate. Great clients also already use modern development practices including CI/CD, blue-green deployments, and automated testing.
Current Limitations and Data Architecture Gaps
Primary Limitations
Traditional data warehouses often struggle with cost, scalability, and agility challenges. The Table 1 below nicely calls out the gap in today vs moder data stack need. The fundamental limitations include:
Structural Limitations:
- Single Point of Failure: From a high-availability perspective, data virtualization represents a single point of failure, which can be a significant risk for organizations that rely heavily on continuous access to virtualized data
- Schema Inflexibility: Traditional data warehouses often impose a single canonical schema for all analytics needs, which can be impractical for anything but the smallest organizations
- Complex Data Quality Management: Ensuring data quality in traditional data warehouses requires extensive analysis to create a single authoritative source, which can be both impractical and undesirable
Comprehensive Gap Analysis Table (Table 1)
| Gap Category | Traditional Architecture Limitation | AI Workload Requirement | Business Impact |
|---|---|---|---|
| Data Processing | Batch processing (hourly/daily) | Real-time streaming and millisecond response | Delayed insights, poor user experience |
| Data Types | Structured data focus | Multi-modal (text, images, video, sensor data) | Limited AI use cases, missed opportunities |
| Scalability | Fixed infrastructure sizing | Elastic compute for variable AI workloads | Resource waste, performance bottlenecks |
| Data Quality | Reactive quality checks | Continuous monitoring and validation | Poor model performance, regulatory risk |
| Governance | Siloed access controls | Unified governance across data-to-AI lifecycle | Compliance issues, security vulnerabilities |
| Integration | Point-to-point connections | API-first, event-driven architecture | Technical debt, slow development cycles |
| Metadata Management | Static documentation | Active metadata for model lineage | Poor debugging capabilities, compliance gaps |
| Cost Management | Predictable, fixed costs | Variable costs based on workload demands | Budget overruns, inefficient resource use |
| Security | Perimeter-based security | Zero-trust, data-centric security | Data breaches, regulatory violations |
| Observability | Limited monitoring | End-to-end pipeline and model observability | Blind spots, extended downtime |
| Interoperability | Vendor lock-in | Open standards and formats | Reduced flexibility, higher switching costs |
| Automation | Manual processes | AI-powered automation and self-service | High operational overhead, human error |
Infrastructure Readiness Gap
Artificial intelligence and machine learning call for specialized infrastructure and large computational capability. Especially for businesses without cloud-based, scalable resources, it might be challenging to modify current data architectures to enable these technologies.
Enterprise Modernization Challenges
Technical Challenges
Legacy System Integration
Legacy systems present fundamental obstacles that extend beyond simple compatibility issues, creating cascading effects throughout modernization initiatives. These systems often rely on outdated programming languages, deprecated frameworks, and architectural patterns that cannot accommodate modern data processing requirements.
Data Quality and Consistency
Maintaining data quality is always difficult, particularly with vast, dispersed datasets. Modern architecture can be less successful depending on incorrect data, duplications, and missing information.
Security and Compliance Complexity
Ensuring data security and compliance gets increasingly difficult when data is scattered over several systems and cloud environments. Safeguarding private data depends on following privacy rules, including GDPR or CCPA, and implementing strong security controls.
Organizational Challenges
Skill Gap and Resource Constraints
Manual monitoring processes are also too time-consuming, which distracts teams from tasks that create new value for customers and the business. In fact, 81% of technology leaders say the effort their teams invest in maintaining monitoring tools and preparing data for analysis steals time from innovation.
Cultural Resistance
Legitimate business concerns over the impact any changes might have on traditional workloads can slow modernization efforts to a crawl. Companies often spend significant time comparing the risks, trade-offs, and business outputs of new and legacy technologies.
Fragmentation and Tool Proliferation
The average multicloud environment spans 12 different platforms and services. On average, organizations use 10 different observability or monitoring tools to manage applications, infrastructure, and user experience across these environments.
Financial Challenges
Total Cost of Ownership Complexity
Many companies don’t do this calculation of total cost of ownership, which can be a showstopper because we aren’t able to calculate the difference in licensing costs on their behalf. And licensing contributes to about 90% of TCO.
Budgeting for Variable AI Workloads
Traditional budgeting models based on fixed infrastructure costs don’t align with the variable, elastic nature of AI workloads, creating financial planning challenges.
Pitfalls During Data Architecture Modernization
Technical Pitfalls
- Underestimating Testing RequirementsWe initially expected our clients to take the lead on the testing side of things. However, we’ve since learned that we can’t rely on customers for appropriate test cases. Many clients aren’t ready or haven’t thought enough about their database modernization testing strategy.
- Inadequate Change ManagementOrganizations often focus solely on technical implementation while neglecting the people and process changes required for successful modernization.
- Premature Technology SelectionRather than engaging in detailed evaluations against legacy solutions, data and technology leaders better serve their organization by educating business leaders on the need to let go of legacy technologies.
Organizational Pitfalls
- Lack of Executive Buy-inWithout strong leadership commitment and clear business case articulation, modernization projects lose momentum during challenging phases.
- Insufficient Investment in TrainingTeams require significant upskilling to work with modern data architectures, cloud-native technologies, and AI/ML tools.
- Neglecting Data Governance EarlyAbout 54% of executives have made Data Governance a top priority for 2024 to 2025. Instead, managers face the challenge of driving accountable Data Governance that serves the organization’s data infrastructure.
Strategic Pitfalls
- Monolithic Migration ApproachAttempting to replace entire systems at once rather than taking an incremental, domain-by-domain approach often leads to project failure.
- Ignoring Business ContinuityFailing to maintain operational systems during transition periods can cause significant business disruption.
Best Practices for Data Architecture Modernization
The Unified Data Platform Approach
According to PwC, a unified enterprise-wide data strategy, underpinned by governance, is key to unlocking AI at scale. It also provides the flexibility to adapt to emerging compliance standards across different jurisdictions.
Key Components of a Unified Data Platform:
- Integrated Storage and Compute: The flexibility of the data lakehouse architecture enables it to be adaptive to business’ future analytical requirements. Data in a lakehouse can be stored in its raw form without any predefined schema or structure
- Real-time Processing Capabilities: In 2025, it will be essential for businesses to stay competitive. Companies will need data architecture that supports instant data processing, allowing them to react quickly to market changes
- AI-Native Architecture: Organizations that invest in a data product operating model—supported by a modern data catalog and aligned with federated governance—are well-positioned to operationalize AI at scale
Modern Data Architecture Principles
- Treat Data as a Shared Asset Treating data as a shared asset throughout the company helps to break down silos and guarantee that every team has access to correct and timely information.
- Implement Federated Governance The federated governance model ensures that while domains operate independently, they still align with the organization’s overall data strategy and regulatory requirements.
- Embrace Cloud-Native Technologies Elastic scale and fully-managed end-to-end pipelines are crucial success factors in gaining business value with consistently up-to-date information.
- Prioritize Data Observability In 2025, data observability is no longer a nice to have—it’s a business-critical capability for any organization serious about data-driven decision making and AI initiatives.
Implementation Strategies
DataOps and Automation
According to recent research, approximately half of organizations are now adopting DataOps methodologies, which bring together IT, analysts, and business users to iteratively refine data pipelines and outputs.
Phased Migration Approach
A chemical company in Eastern Europe, for instance, created a data-as-a-service environment, offloading large parts of its existing enterprise resource planning and data-warehouse setup to a new cloud-based data lake and provisioning the underlying data through standardized application programming interfaces (APIs).
Is a Unified Data Platform a Necessity?
The evidence strongly suggests yes. Google’s distinctive and forward-thinking vision is to provide a unified, agentic, intelligent, and seamlessly integrated data platform that blends data management, advanced analytics, and AI capabilities at scale.
Benefits of Unified Platforms:
- Reduced Complexity: Elimination of multiple point solutions and data movement
- Improved Governance: Consistent policies across the entire data-to-AI lifecycle
- Enhanced Performance: Optimized data processing for AI workloads
- Cost Efficiency: On average, companies have been able to reduce metrics costs by 35% through intelligent data management
The Role of Federated Learning in Modern Data Architecture
Understanding Federated Learning’s Potential
Federated learning enables devices or organizations to collaboratively train a global model by sharing only model parameters. This ensures that sensitive data remains local, reducing privacy risks and complying with regulations like GDPR.
Can Federated Learning Replace Unified Data Platforms?
Current State of Maturity: The global federated learning market, valued at $150 million in 2023, is forecasted to reach $2.3 billion by 2032, growing at a remarkable CAGR of 35.4%. However, federated learning is not yet mature enough to fully replace unified data platforms for all AI workloads.
Strengths of Federated Learning:
- Privacy Preservation: This approach mitigates privacy risks as raw data remains locally on the sources, which is particularly beneficial in scenarios where data sensitivity or regulatory requirements make data centralisation impractical
- Regulatory Compliance: This decentralised approach aligns with the core principles of data protection, such as data minimisation and purpose limitation, by ensuring that personal data remains under the control of the controller
- Industry Applications: Federated learning is particularly valuable in healthcare, where patient data privacy is paramount. Hospitals and research institutions can collaboratively train models on medical data without sharing sensitive information
⠀
Current Limitations:
- Resource Constraints: Devices participating in Federated Learning may have limited computational resources, which can impact their ability to train models effectively
- Model Complexity: Designing models and algorithms that can efficiently operate in a federated setting can be complex. It requires careful consideration of factors like update frequency, model size, and aggregation methods
- Infrastructure Requirements: Coordinating training across loosely synchronized and heterogeneous devices produces countless operational challenges that hinder the broader adoption of FL
Federated Learning and Data Mesh Integration
Federated Learning and Data Mesh are not just complementary technologies; they are a match made in heaven. Federated Learning allows for collaborative model training across decentralized data sources without compromising data privacy, while Data Mesh provides a scalable and flexible framework for managing data as a product within decentralized domains.
Where Federated Learning Excels:
- Cross-border data collaboration
- Highly regulated industries (healthcare, finance)
- IoT and edge computing scenarios
- Privacy-critical applications
Where Unified Platforms Are Still Essential:
- Complex data transformations and ETL processes
- Real-time analytics requiring centralized compute
- Multi-modal AI applications requiring data fusion
- Enterprise-wide data governance and lineage
The Future of Data Architecture in the AI Landscape
Emerging Trends Shaping 2025 and Beyond
AI-Native Architecture Evolution
Next-gen AI thrives in decentralized environments. Intelligent agents and machine learning models require rapid access to relevant, trustworthy data across domains.
Autonomous Data Management
As we evolve BigQuery into an autonomous data-to-AI platform, we are committed to helping you navigate the complexities of the modern data landscape and lead with data and AI.
Semantic Layer Integration
From an architect’s point of view, a semantic layer architecture adds significant value to modern data architecture and it is becoming a trend organizations are embracing – primarily because it provides the framework for addressing these traditional challenges.
Key Architectural Patterns for the Future
- Data Mesh with Federated GovernanceKroger’s implementation of the data mesh architecture reorganized teams and data around domains, such as supply chain, aligned to business capabilities.
- Event-Driven ArchitecturesEvent-driven architectures that trigger downstream actions automatically and low-latency pipelines that power real-time AI models and inference will become standard.
- Agentic AI IntegrationBigQuery’s AI-powered data management capabilities are designed for users of all skill levels. Data analysts can use natural language to query data, generate SQL, and summarize results.
Technology Convergence
Multimodal Data Support
Multimodal support lets you store and analyze structured and unstructured data within the same table, streamlining complex analytics workflows.
Synthetic Data Integration
With stricter privacy regulations, synthetic data will become more important for businesses. These artificially created datasets mimic real-world information, allowing companies to train machine learning models without exposing sensitive data.
Cost Optimization Through AI
Cut down on the added cost of scale with AI-powered tools like Adaptive Metrics, which aggregates unused or partially used metrics.
Investment Priorities
Data Observability Platforms
As LLMs become more prevalent in customers’ day-to-day work, organizations are developing various ways to monitor and observe LLMs including tracking user interactions, token usage, costs, and performance metrics.
Unified Governance Frameworks
According to PwC, a unified enterprise-wide data strategy, underpinned by governance, is key to unlocking AI at scale.
Real-time Analytics Infrastructure
Organizations will prioritize infrastructure that supports instant data processing and millisecond response times for AI applications.
We summarize pictorially in Figure 1 of the Data Architecture for the future AI workload:
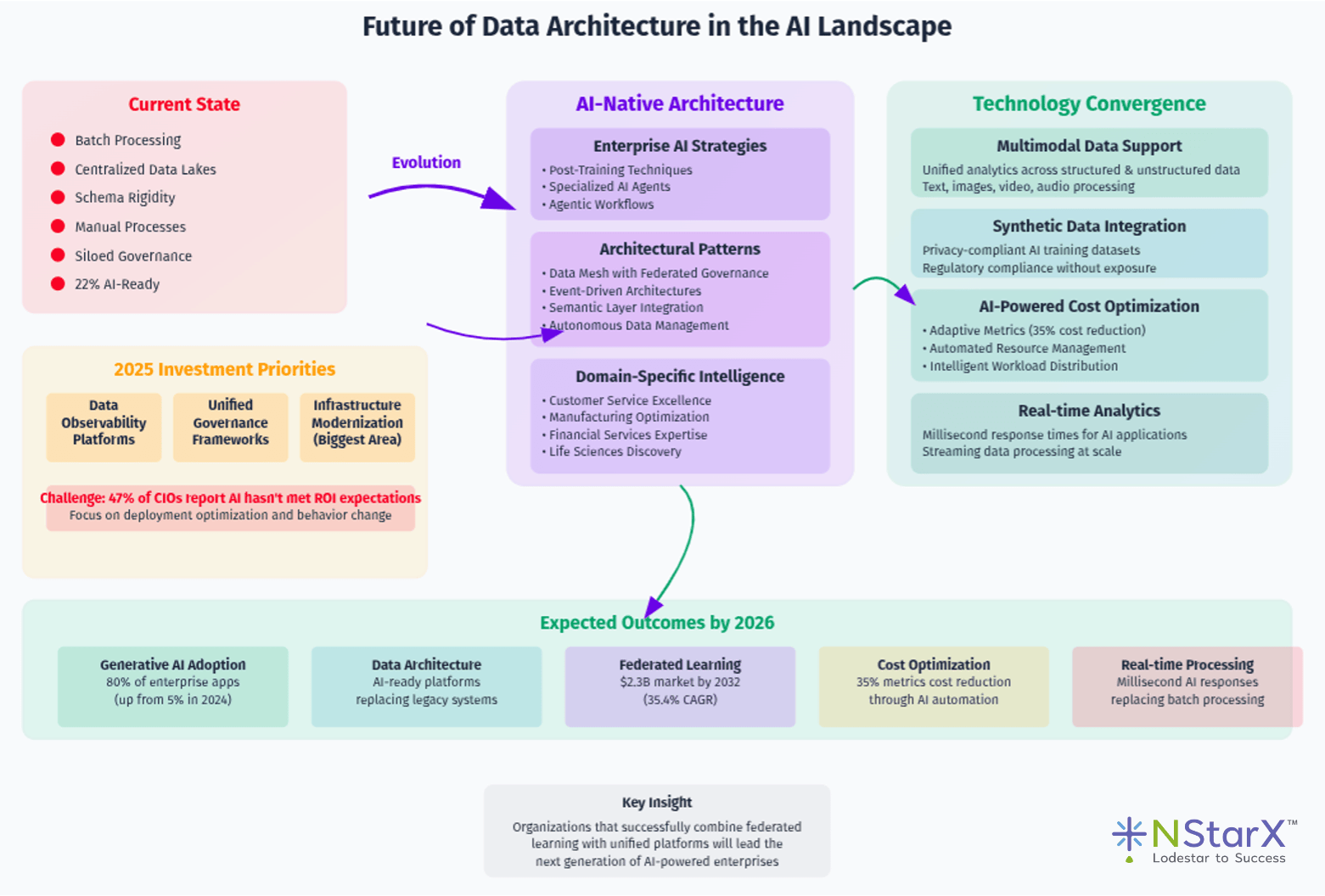
Figure 1: Data Architecture for the AI workloads (Generic and high level)
Conclusion
The data architecture landscape is undergoing a fundamental transformation driven by AI adoption. Only 22% of organizations believe their current architecture can support AI workloads without modifications, highlighting the urgent need for comprehensive modernization efforts.
Key Takeaways
- The Modernization ImperativeTraditional data architectures, built for batch processing and structured reporting, fundamentally cannot support the real-time, multi-modal, and elastic requirements of modern AI workloads. Organizations that delay modernization risk being left behind in the AI revolution.
- Success Requires Holistic ApproachThe most successful modernization initiatives address technical, organizational, and strategic challenges simultaneously rather than treating them as separate concerns. Technical modernization alone is insufficient without corresponding changes in governance, culture, and processes.
- Unified Platforms Are EssentialWhile federated learning shows promise for specific use cases, unified data platforms remain necessary for comprehensive AI operations. The future lies in hybrid approaches that combine centralized governance with decentralized execution.
- Investment in Observability is CriticalData teams today are managing increasingly complex data stacks spanning cloud data warehouses, real-time pipelines, and AI/ML workloads. In 2025, data observability is no longer a nice to have—it’s a business-critical capability.
- Continuous Evolution RequiredOrganizations must recognize that data modernization represents an ongoing capability rather than a one-time project, requiring sustained investment in workforce development, change management, and technical architecture.
Strategic Recommendations
For CTOs and Data Leaders:
- Develop a clear business case for modernization with quantified benefits
- Adopt a phased, domain-by-domain migration approach
- Invest heavily in data observability and governance from day one
- Build AI-native architectures that support real-time, multi-modal workloads
⠀
For Organizations Beginning Their Journey:
- Start with data quality and governance fundamentals
- Implement modern data observability tools
- Adopt cloud-native, elastic infrastructure
- Establish federated governance frameworks
The organizations that successfully navigate this transformation will gain significant competitive advantages through faster innovation, better decision-making, and the ability to deploy AI at scale. Those that delay risk obsolescence in an increasingly AI-driven business landscape.
The future belongs to organizations that can effectively combine the privacy benefits of federated learning with the governance and performance capabilities of unified data platforms, creating truly intelligent, autonomous data architectures that power the next generation of AI applications.
References
- DATAVERSITY. “Data Architecture Trends in 2025.” January 7, 2025.
- Cockroach Labs. “Big Ideas for 2025: What is ‘data modernization’ today?” 2025.
- Addepto. “Modern data architecture: Cost-effective innovations for 2025.” February 21, 2025.
- McKinsey & Company. “Breaking through data-architecture gridlock to scale AI.” January 26, 2021.
- Forvis Mazars. “Data Modernization Strategy: Fueling AI & Faster Decisions.” August 2025.
- DATAVERSITY. “Data Architecture Trends in 2024.” January 2, 2024.
- World Economic Forum. “Designing more inclusive AI starts with data architecture.” May 2025.
- Alation. “How to Evolve Your Data Architecture for Next-Gen AI.” May 14, 2025.
- Enterprise Knowledge. “Data Management and Architecture Trends for 2025.” January 27, 2025.
- Lumen Data. “Complete 2025 Data Warehouse Modernization Guide.” July 2025.
- European Data Protection Supervisor. “TechDispatch #1 /2025 – Federated Learning.” June 10, 2025.
- Nature Scientific Reports. “Adaptive federated learning for resource-constrained IoT devices.” November 20, 2024.
- Vertu. “How AI Federated Learning is Transforming Industries in 2025.” May 29, 2025.
- ScienceDirect. “Federated learning: Overview, strategies, applications, tools and future directions.” September 20, 2024.
- Wikipedia. “Federated learning.” Updated August 25, 2025.
- Flower AI. “Flower: A Friendly Federated AI Framework.” 2025.
- AIMulit. “Federated Learning: 5 Use Cases & Real Life Examples.” July 24, 2025.
- Google Cloud. “AI and machine learning resources.” May 2, 2025.
- arXiv. “Federated Learning in Practice: Reflections and Projections.” October 11, 2024.
- Apheris. “Federated Learning and Data Mesh: how it enhances data architecture.” April 24, 2025.
- Acceldata. “Modern Data Architecture: Building the Foundation for Data-Driven Success.” April 29, 2025.
- Tredence. “What Is Data Modernization? Key Benefits & 5 Best Practices.” December 18, 2024.
- Kai Waehner. “Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization.” August 8, 2022.
- Airbyte. “What Is Data Modernization Strategy: Benefits & Examples.” July 2025.
- Medium. “Modern Data Architectures Explained.” October 27, 2024.
- Net Solutions. “Application Modernization Case studies and Success Stories.” May 5, 2025.
- AtScale. “6 Principles of Modern Data Analytics Architecture.” April 25, 2025.
- EQengineered. “Modern Data Architecture – A Data Modernization Green Paper.” October 31, 2023.
- ClearScale. “Database Modernization: Key Lessons Learned.” March 31, 2024.
- Softermii. “5 Best Practices to Modernize Your Data Architecture.” December 12, 2023.
- CNCF. “Observability Trends in 2025 – What’s Driving Change?” March 16, 2025.
- Gartner Peer Insights. “Best Data Observability Tools Reviews 2025.” 2025.
- Coralogix. “The Best AI Observability Tools in 2025.” June 19, 2025.
- Google Cloud Blog. “2025 Forrester Wave Data Management for Analytics Platforms.” April 29, 2025.
- Grafana. “AI/ML tools for observability.” 2025.
- Cloudian. “Data Management Platform: Key Components & Top 8 Solutions in 2025.” April 1, 2025.
- Gartner Peer Insights. “Best Observability Platforms Reviews 2025.” 2025.
- SYNQ. “The 10 Best Data Observability Tools in 2025.” July 9, 2025.
- Dynatrace. “The state of observability in 2024: AI, analytics, and automation.” April 8, 2025.
- Snowflake. “The Snowflake Platform.” 2025.