A Strategic Framework for Bridging Product Innovation and Production Reality
Introduction: The Last-Mile Problem in Enterprise AI
Enterprise AI projects have a dirty secret: most fail not because of algorithmic inadequacy, but because of the chasm between what product engineers build and what production environments actually need. A 2024 study by Gartner estimated that 85% of enterprise AI projects never make it past the pilot stage, and when they do, the median time-to-production stretches beyond 18 months. The problem isn’t the models—it’s the deployment reality.
This is where Forward Deployment Engineering (FDE) emerges as the critical missing layer. Unlike traditional delivery models that treat deployment as a handoff, FDE embeds product engineers directly at the customer site, in production environments, until the solution isn’t just “working” but woven into business operations. As enterprises rush to become AI-native between 2026 and 2030, FDE is transitioning from a Silicon Valley luxury to an operational necessity for IT services and product engineering firms.
What Is Forward Deployment Engineering?
Definition and Core Principles
Forward Deployment Engineering is a delivery model where product engineers embed directly within customer environments—often on-site or in dedicated customer tenancies—to build, deploy, and operationalize software solutions in close collaboration with end users and stakeholders. Unlike traditional consulting or implementation services, FDE engineers are product builders first, but they operate at the intersection of three critical contexts: the product’s technical capabilities, the customer’s business logic, and the production environment’s operational constraints.
The core principles that define FDE include:
Embedded Context Acquisition: FDE engineers don’t work from requirements documents. They sit with traders on trading floors, clinicians in hospital workflows, supply chain managers in distribution centers. They observe, absorb, and encode business context that can’t be captured in Jira tickets.
Production-First Mindset: Unlike R&D engineers or even DevOps teams that optimize for general scalability, FDE engineers optimize for this specific customer’s production environment. That means working within their IAM policies, their network topologies, their compliance frameworks, their data residency requirements—not around them.
Rapid Iteration in Live Environments: FDE teams operate in compressed cycles. They might deploy three iterations in a week, watching users interact with each version, debugging edge cases in real-time, and incorporating feedback before the user even files a formal bug report.
Ownership Through Operationalization: The engagement doesn’t end at deployment. FDE engineers stay engaged through initial production usage, monitoring dashboards they built, refining performance based on actual usage patterns, and transferring knowledge to internal teams only when the system is truly operationalized.
Historical Evolution: From Field Engineers to Embedded Product Teams
The concept of embedding technical talent at customer sites isn’t new. Field engineering has existed since the mainframe era—IBM’s customer engineers famously lived at client locations for months. But those were support roles, not product development roles. The evolution to modern FDE happened in three waves:
Wave 1 (1990s–2000s): Professional Services and Custom Integrations
Traditional IT services companies like Accenture, IBM Global Services, and Deloitte built massive professional services arms. Engineers would deploy ERP systems, customize enterprise software, and integrate disparate systems. But this model had a fatal flaw: the engineers doing the integration rarely influenced the product roadmap. They were implementers, not innovators. The products they deployed were often bloated, over-engineered for generic use cases, and resistant to the specific workflows customers actually needed.
Wave 2 (2003–2015): The Palantir Inflection Point
Palantir Technologies fundamentally reimagined this model. Facing the challenge of deploying complex data integration and analysis platforms for intelligence agencies and later Fortune 500 companies, Palantir realized that their product was too sophisticated and too context-dependent for traditional implementation services. They created Forward Deployed Engineers (FDEs)—product engineers who would embed with customers for 6–18 months, not just to deploy Palantir’s software, but to build customer-specific workflows, data pipelines, and analytical ontologies using Palantir’s platforms as the substrate.
These FDEs weren’t consultants recommending configurations. They were writing code, building custom integrations, designing data models, and in many cases, influencing Palantir’s core product roadmap based on what they learned in the field. The model proved so successful that Palantir’s revenue growth became directly correlated with FDE headcount expansion. By 2015, every major enterprise software company was studying the model, though few replicated it successfully.
Wave 3 (2018–Present): Product-Led Growth Meets Enterprise Complexity
The third wave emerged as product-led growth companies like Databricks, Snowflake, and Scale AI encountered enterprise deployment complexity at scale. Unlike Palantir’s defense and intelligence focus, these companies faced hundreds or thousands of enterprise customers simultaneously. They couldn’t afford dedicated 18-month engagements for everyone, so they evolved FDE into a more scalable, modular model: shorter engagements (3–6 months), focused on specific high-value workflows, with strong emphasis on building reusable patterns and reference architectures that could be templatized for future customers.
This is the model that IT services and product engineering firms are now adopting and adapting for the AI-native era. Figure 1 captures the era and evolution of FDE:
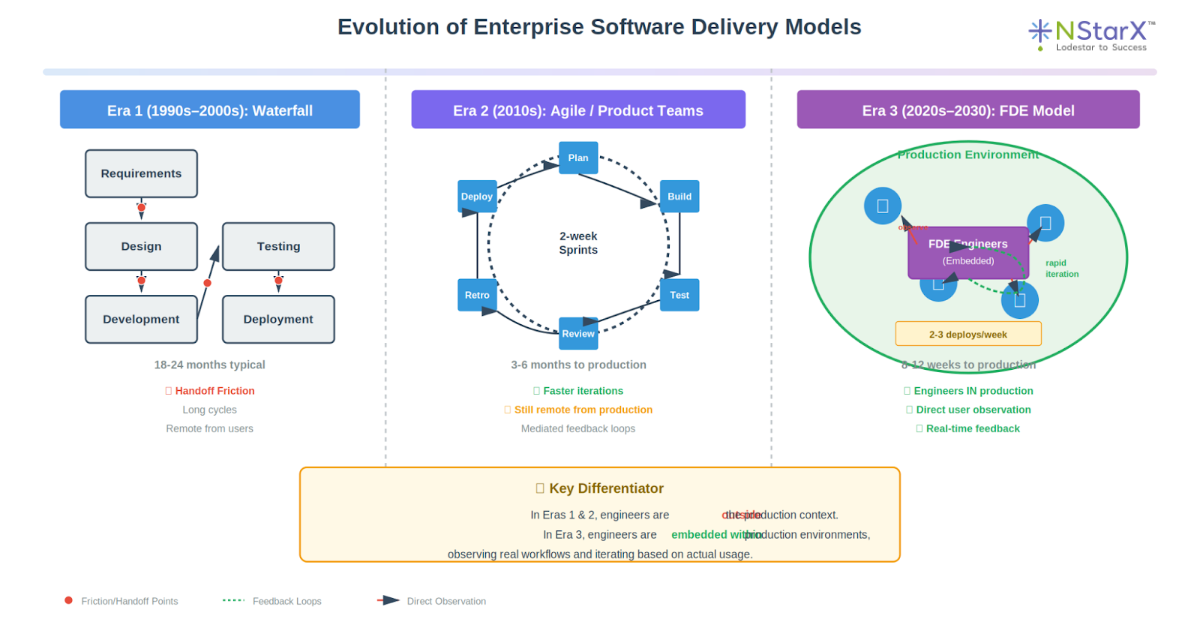
Figure 1: Evolution of Enterprise Software Delivery Models
Why Silicon Valley Product Companies Championed FDE
The FDE model didn’t emerge from consulting playbooks or academic research. It emerged from brutal market reality. Companies like Palantir, Anduril, Scale AI, and later Databricks faced a common challenge: their products were fundamentally different from previous generations of enterprise software. They weren’t applications with configuration menus. They were platforms that required deep customization, workflow integration, and data engineering to deliver value.
The Palantir Case Study: Why Standard Delivery Models Failed
When Palantir first attempted to deploy their Gotham platform to intelligence agencies in the mid-2000s, they tried the standard enterprise software playbook: deliver the product, provide training, offer a support hotline. The deployments failed spectacularly. Analysts couldn’t figure out how to map their investigative workflows to Palantir’s graph-based data model. Data integration became a nightmare because Palantir’s engineers didn’t understand the customer’s classification schemas. The product was powerful but unusable.
Palantir’s solution was radical: send product engineers into the SCIF (Sensitive Compartmented Information Facility). Not support engineers, not implementation consultants—actual product engineers who had built parts of Gotham’s core platform. These engineers would spend months embedded with intelligence analysts, learning how they actually worked, what questions they were trying to answer, which data sources mattered, and how to build workflows that felt native to their operational context.
The results were transformative. Not only did deployments succeed, but Palantir’s product evolved based on patterns FDEs discovered across multiple agencies. The FDE organization became Palantir’s primary feedback loop for product development. Features that FDEs built repeatedly in custom implementations eventually got promoted into the core platform. The FDE organization wasn’t a cost center—it was both a revenue driver and a product innovation engine.
Why Standard Delivery Models Couldn’t Compete
Traditional IT services delivery models failed in this context for several structural reasons:
Requirements Gathering Doesn’t Work for Emergent Complexity: Traditional waterfall or even agile methodologies assume you can gather requirements upfront. But for AI/ML platforms, the value often emerges through experimentation. Users don’t know what’s possible until they see it working with their data. FDE engineers discover requirements by building incrementally and observing reactions.
The Handoff Kills Institutional Knowledge: In traditional models, presales engineers demo the product, solutions architects design the implementation, delivery teams build it, and support teams maintain it. At each handoff, context evaporates. FDE engineers carry context from sale through production, becoming the institutional memory for that customer relationship.
Generic Best Practices Fail in Specific Contexts: Enterprise software companies love to publish “best practices” and “reference architectures.” But production environments are snowflakes. A healthcare provider’s data governance model is fundamentally different from a financial services firm’s, even if both are implementing the same MLOps platform. FDE engineers develop context-specific best practices rather than applying generic ones.
Why FDE Is Now Critical for AI-Native Enterprises (2026–2030)
The transition to AI-native operations between 2026 and 2030 is creating deployment complexity that dwarfs previous enterprise software generations. This isn’t about deploying another SaaS application. This is about fundamentally rewiring how enterprises make decisions, process information, and deliver services. FDE is becoming essential because of five converging forces:
1. The LLMOps Complexity Explosion
Large Language Models aren’t packaged applications. Deploying an enterprise LLM workload involves orchestrating model serving infrastructure, managing prompt templates and retrieval-augmented generation (RAG) pipelines, implementing guardrails and content filtering, monitoring for hallucinations and drift, managing versioning across multiple fine-tuned variants, and integrating with existing systems of record.
A typical enterprise LLM deployment in 2026 might involve fine-tuning a foundation model on proprietary data, implementing a hybrid RAG architecture with both vector databases and knowledge graphs, deploying inferencing across a mix of GPU clusters and edge devices, and integrating with legacy applications through API gateways. There’s no cookbook for this. Every deployment is an engineering project.
FDE engineers don’t just “implement” these systems. They make architectural decisions in real-time based on actual usage patterns. They tune retrieval strategies based on which documents users actually reference. They optimize prompt templates based on observed failure modes. They build monitoring dashboards that surface the specific drift patterns relevant to this customer’s domain.
2. Agentic AI Requires Workflow Integration, Not Just API Calls
The shift from copilots to autonomous agents represents an order-of-magnitude increase in integration complexity. A copilot suggests code completions or email drafts. An agent takes actions: it schedules meetings, processes insurance claims, generates and executes trade strategies, or autonomously handles customer service escalations.
For agentic AI to work in enterprise contexts, it needs to integrate with dozens of systems: identity providers, approval workflows, audit logging, exception handling, rollback procedures, and compliance monitoring. It needs to understand business rules that were never documented because they existed in the heads of senior employees. It needs to handle edge cases that no one anticipated during requirements gathering.
FDE engineers build these integrations by observing workflows in practice. They sit with claims processors and watch how they handle ambiguous cases. They shadow traders to understand when automated strategies should pause for human review. They learn the unwritten rules that govern how work actually gets done, then encode those rules into agent behaviors and guardrails.
3. Context Graphs Are Customer-Specific Knowledge Structures
The most sophisticated AI deployments in 2026 are moving beyond vector embeddings to hybrid architectures that combine semantic search with structured knowledge graphs. These “context graphs” encode relationships, business logic, hierarchies, and domain ontologies specific to each organization.
Building a context graph isn’t a product feature you can turn on. It’s a multi-month engineering effort that requires deep understanding of the customer’s domain. For a pharmaceutical company, it might involve mapping relationships between compounds, clinical trials, regulatory submissions, and adverse event reports. For a media company, it might involve encoding relationships between content assets, rights holders, distribution channels, and revenue models.
FDE engineers build these graphs collaboratively with domain experts. They conduct workshops to understand taxonomies, interview stakeholders to map workflows, analyze existing data structures to extract implicit relationships, and iteratively refine the ontology based on how users actually query the system. This is knowledge engineering in the classical AI sense, but applied to modern LLM and graph database architectures.
4. Confidential Computing and Federated Learning Require Environment-Specific Architecture
As enterprises become more sophisticated about data governance, deployments increasingly involve confidential computing enclaves, federated learning architectures, and hybrid cloud models where different data categories live in different sovereignty zones.
A healthcare consortium might deploy federated learning where patient data never leaves individual hospital networks, but model updates get aggregated in a secure coordination layer. A financial services firm might run sensitive trading algorithms inside AWS Nitro enclaves while pulling market data from public clouds. A manufacturing network might train predictive maintenance models across factory sites without centralizing operational data.
These architectures can’t be designed in a vacuum. They require deep understanding of where data lives, who can access it, what regulatory constraints apply, and how to orchestrate training and inference across these boundaries. FDE engineers work with security teams, compliance officers, and infrastructure teams to design and implement these architectures in ways that actually work operationally, not just theoretically.
5. The Vendor Landscape Is Too Fragmented for Generic Integration
The AI infrastructure stack in 2026 is brutally fragmented. An enterprise might be using OpenAI for general purpose LLMs, Anthropic for code generation, Cohere for embeddings, Pinecone for vector search, Neo4j for knowledge graphs, Databricks for feature engineering, Weights & Biases for experiment tracking, Arize for monitoring, and custom infrastructure for fine-tuning and inference.
Making these components work together isn’t about reading API documentation. It’s about understanding the subtle incompatibilities, the performance characteristics, the failure modes, and the operational gotchas. It’s about knowing when to use which tool, how to route requests efficiently, where to cache, and how to handle fallbacks when services are unavailable.
FDE engineers build the integration layer that makes this heterogeneous stack feel like a coherent platform. They create abstraction layers that hide complexity from application developers while maintaining flexibility for optimization. They implement circuit breakers, retry logic, and fallback strategies tuned to each component’s reliability profile.
Comparing Delivery Models: Traditional, Agile Pods, and FDE
To understand why FDE is gaining traction, it’s useful to contrast it with alternative delivery models:
Traditional Waterfall/Offshore Delivery Model
How It Works: Requirements are gathered upfront, often through a series of workshops and document reviews. A solutions architect creates a detailed design document. Development happens offshore with a distributed team. Testing occurs in a separate phase. Deployment is a big-bang event with extensive change management.
Strengths: Cost efficiency through offshore labor arbitrage. Clear milestone-based governance. Well-understood by procurement and PMO organizations. Works well for clearly-scoped, low-ambiguity projects.
Fatal Flaws for AI Projects: Requirements for AI applications are emergent, not knowable upfront. The value proposition often only becomes clear after users interact with working prototypes. Offshore teams lack the business context needed to make architectural decisions. The handoff from architecture to development to deployment loses critical tacit knowledge. By the time the system is deployed, business needs may have evolved.
Agile Product Teams / Scrum Pods
How It Works: Cross-functional teams (developers, designers, product managers) work in sprints, delivering incremental value. Product backlogs are continuously refined based on stakeholder feedback. Teams work closely with product owners who represent business stakeholders.
Strengths: Faster iteration cycles. Better incorporation of feedback. Teams develop deeper product knowledge over time. Works well for product companies building for broad markets.
Fatal Flaws for Enterprise AI Deployment: Product owners are proxies for users, not actual users in production environments. Teams are usually remote from production reality, developing in idealized staging environments. Limited ability to observe actual usage patterns in real-time. Feedback loops are mediated through sprint reviews and user testing, not direct observation of production workflows.
Forward Deployment Engineering Model
How It Works: Product engineers embed directly in customer environments, often on-site or with dedicated secure access to production systems. They build iteratively, deploying code multiple times per week directly to production or production-adjacent environments. They observe users working with each iteration in real-time, adjusting based on actual behavior rather than reported feedback. They own the full stack from data pipelines to user interfaces to operational monitoring. The engagement continues until the system is fully operationalized and internal teams can maintain it autonomously.
Strengths:
- Engineers develop firsthand understanding of business context and operational constraints
- Extremely rapid iteration cycles with feedback loops measured in hours, not weeks
- Solutions are automatically tuned to the specific production environment’s characteristics
- Tacit knowledge about workflows and edge cases gets encoded directly into the implementation
- Customer teams learn by working alongside FDE engineers, enabling smoother handoff
- FDE engineers can influence product roadmap based on patterns observed across multiple deployments
Trade-offs:
- Higher cost per engineer than offshore or remote agile teams
- Requires engineers who can operate in ambiguous, context-heavy environments
- Less standardized processes, which can complicate scaling
- Customers must provide access to production or near-production environments
- Success depends heavily on individual engineer quality and adaptability
Why It’s Essential for AI: AI systems require tight coupling between algorithms, data, and workflows. The last-mile gap between “the model works in the lab” and “the system delivers business value in production” is where most AI projects fail. FDE eliminates that gap by embedding the engineers who built the solution in the environment where it needs to run.
How FDE Bridges the Last-Mile Gap
The “last mile” in enterprise AI isn’t about the final 10% of engineering effort. It’s about the chasm between what works in a demo and what works when a procurement manager is using it to process 10,000 POs per day with real vendors, real exceptions, and real consequences for mistakes.
The Three Last-Mile Gaps FDE Addresses
Gap 1: From Model Accuracy to Workflow Utility
An FDE team deploying a document extraction model for a law firm discovered that their 95% accuracy rate was useless because the 5% of failures occurred disproportionately on the most important document types—merger agreements and patent filings. The model had been trained on a balanced dataset, but production usage was heavily skewed. Within two weeks of deployment, the FDE engineers retrained the model with weighted sampling toward critical document types, implemented a confidence-based routing system where low-confidence extractions went to human review, and built a feedback interface where attorneys could correct mistakes in real-time to continuously improve the model. None of this could have been designed upfront. It emerged from observing actual usage patterns.
Gap 2: From Generic Infrastructure to Production Constraints
When deploying a real-time recommendation engine for a retail bank, the FDE team discovered that the customer’s network architecture had a 200ms latency penalty for calls from the web tier to the GPU inference cluster due to firewall traversal. The demo had shown 50ms response times, but production would hit 250ms—unacceptable for a real-time experience. Instead of declaring the network architecture “wrong,” the FDE engineers redesigned the solution: they moved to a hybrid architecture where lightweight models ran on CPU in the web tier for common cases, with GPU inference reserved for complex queries, and implemented aggressive caching based on user session patterns they observed in production logs. The end result actually outperformed the demo because it was optimized for the real environment’s characteristics.
Gap 3: From Feature Completeness to Operational Readiness
Operational readiness isn’t about checking boxes on a deployment checklist. It’s about building the institutional knowledge and operational muscle memory that enables internal teams to run the system independently. FDE engineers don’t just build monitoring dashboards—they sit with the operations team during the first week of production, showing them how to interpret latency distributions, what cascading failure patterns look like, when to scale up infrastructure, and how to diagnose data quality issues. They create runbooks based on actual incidents that occurred during early production usage, not generic troubleshooting guides. They train internal engineers by pair-programming on real production issues, not classroom lectures.
Why FDE Is Essential for Specific AI Workload Categories
Different categories of AI workloads present different last-mile challenges. FDE’s value varies based on workload characteristics:
Enterprise LLM Applications (Highest FDE Value)
Enterprise LLM deployments are almost always context-specific. A customer service agent LLM needs to be grounded in the company’s product catalog, support documentation, policy guidelines, and historical interaction patterns. A legal research assistant needs to understand jurisdiction-specific case law, the firm’s precedent library, and attorney work patterns.
FDE engineers build the connective tissue between foundation models and enterprise context. They design RAG architectures tailored to the specific retrieval patterns of the use case. They implement prompt templates that incorporate domain-specific terminology and reasoning patterns. They build evaluation frameworks based on the specific failure modes that matter to this customer—hallucinations about pricing in customer service versus factual inaccuracies in legal research require different monitoring approaches.
Most critically, FDE engineers handle the politics and change management of LLM deployment. When knowledge workers fear being replaced by AI, FDE engineers can demonstrate how the LLM augments their capabilities by building workflows where the LLM handles routine queries and surfaces interesting edge cases for human review. This requires being in the room, understanding team dynamics, and building solutions that work socially as well as technically.
Agentic AI and Autonomous Decision Systems (Critical FDE Value)
Autonomous agents that take actions without human approval require extremely high trust thresholds. The only way to build that trust is through iterative deployment with extensive guardrails, monitoring, and progressive autonomy.
FDE teams deploying agentic systems typically follow a pattern: start with pure observation where the agent generates recommendations but takes no actions, then shadow mode where the agent’s actions are logged but not executed, then limited autonomy with human oversight on exceptions, and finally full autonomy with monitoring. This progression requires being embedded in the customer organization to observe reactions at each stage, tune guardrails based on actual failure modes, and build confidence incrementally.
For example, an FDE team deploying an autonomous pricing agent for an e-commerce platform started with the agent only suggesting prices. After two weeks of monitoring where the agent’s suggestions would have been wrong, they implemented automated price changes but only within narrow bounds (±5%) and only for low-velocity SKUs. After another month, they expanded the bounds and SKU coverage based on observed performance. Six months in, the agent was handling 80% of pricing decisions autonomously, but the progression required constant observation and tuning that could only happen with engineers embedded in the business context.
Federated Learning and Privacy-Preserving ML (High FDE Value)
Federated learning deployments are inherently complex because they involve coordinating model training across multiple organizations or data silos while preserving privacy. This isn’t just a technical challenge—it’s a multi-stakeholder coordination problem.
FDE engineers in federated learning projects spend as much time on governance and trust frameworks as on technical implementation. They work with legal teams to define data sharing agreements, with security teams to implement secure aggregation protocols, with compliance teams to ensure differential privacy guarantees meet regulatory requirements, and with business stakeholders to design incentive structures that encourage participation.
A healthcare consortium implementing federated learning for clinical decision support needed FDE engineers embedded at multiple hospital sites to understand local data governance requirements, navigate IRB approval processes, train local IT teams on secure enclave operations, and troubleshoot site-specific infrastructure issues. The technical implementation was straightforward; the organizational coordination was the hard part, and it required human relationships and trust that can only be built through in-person engagement.
Traditional ML/Predictive Analytics (Moderate FDE Value)
Even traditional supervised learning deployments benefit from FDE when the problem domain is complex or the customer organization is new to ML. Deploying a demand forecasting model might seem straightforward, but FDE engineers often discover that the “ground truth” data is incomplete, that business users apply manual adjustments based on tacit knowledge, or that forecast accuracy matters much more for certain product categories than others.
However, once the initial deployment is successful and internal teams have developed ML literacy, subsequent models in the same domain can often be deployed with lighter-touch engagement. FDE is most valuable for the first few ML deployments that establish patterns and build organizational capability.
FDE’s Impact on Business Outcomes: ROI, Adoption, and Velocity
The business case for FDE is straightforward: despite higher per-engineer costs, FDE dramatically improves the outcomes that actually matter—time-to-value, adoption rates, and customer lifetime value.
Faster Time-to-Production Value
Traditional AI deployments follow a depressing pattern: 6 months of requirements gathering and architecture design, 9 months of development, 3 months of UAT and rework, 2 months of deployment and stabilization, and then another 6 months of low adoption while users figure out how to actually use the system. Total time from kickoff to meaningful business value: 24+ months.
FDE deployments compress this timeline because there’s no handoff friction and no requirements guessing game. A typical FDE engagement might achieve measurable production usage within 8–12 weeks. The FDE team deploys a minimal viable version within the first 2–3 weeks, observes actual usage, and iterates rapidly based on real feedback. By week 8, the system is handling real production load. By week 12, adoption is growing and the team is focusing on optimization rather than core functionality.
This isn’t just about speed—it’s about reducing waste. Traditional projects spend months building features that users don’t need while missing capabilities that would drive immediate value. FDE discovers what actually matters through direct observation.
Higher Adoption Rates Through Co-Creation
Users are far more likely to adopt systems they helped build. When FDE engineers sit with users during development, the users become invested in the solution’s success. They see their feedback incorporated in real-time. They understand why certain design decisions were made. They develop confidence in the system because they watched it evolve from rough prototype to production-ready solution.
Contrast this with traditional deployments where a polished system appears after months of remote development. Users had no visibility into the development process, don’t understand the design rationale, and approach the new system with skepticism. Adoption becomes a change management battle rather than a natural evolution.
Improved ROI Through Production Optimization
The ROI of AI systems isn’t determined by model accuracy in isolation—it’s determined by how well the system integrates into actual workflows. An FDE team can optimize for real ROI drivers because they observe production usage patterns.
For example, when deploying a content moderation system, an FDE team discovered that 60% of moderation decisions involved a very narrow category of borderline content. Instead of optimizing model performance across all categories equally, they focused engineering effort on improving accuracy for that high-frequency borderline category and built specialized review workflows for it. This delivered 3x better ROI than generic accuracy improvements would have because it addressed the actual operational bottleneck.
Customer Stickiness and Expansion Revenue
FDE creates sticky customer relationships because the embedded engineers become trusted advisors, not just vendors. They understand the customer’s business deeply, they’ve proven their ability to deliver, and they’re seen as part of the team rather than external contractors.
This trust translates directly to expansion revenue. When the customer has a new AI use case, they default to working with the team that succeeded on the previous deployment. When competitors try to displace the incumbent, they’re not just competing on product features—they’re competing against established relationships and institutional knowledge.
Implementing FDE Inside Modern IT Services Organizations
For IT services companies, adopting FDE requires rethinking organizational structure, talent models, and delivery governance. It’s not a minor process adjustment—it’s a strategic capability that needs to be built intentionally.
The FDE Organization Structure
Integration with Product Engineering
FDE teams should be tightly coupled with product engineering, not siloed in professional services. FDE engineers need to be able to influence the product roadmap based on field learnings. This works best when FDE is organizationally positioned as an extension of the product team with a dotted line to delivery or customer success.
At NStarX, the FDE function sits within the Product Engineering organization and works closely with Platform Services. FDE engineers have direct access to the platform engineering team and participate in sprint planning to communicate customer requirements and deployment patterns. This ensures that capabilities developed during customer engagements eventually get promoted into the core DLNP platform.
Roles Within FDE Teams
An effective FDE team typically includes:
The Lead FDE: Serves as both technical architect and customer relationship owner, typically 8+ years of experience with deep domain knowledge. This person makes architectural decisions, manages stakeholder expectations, and serves as the escalation point for complex issues.
Product FDEs: Senior engineers (5–8 years) who build the core functionality. They need to be full-stack capable, comfortable working in ambiguous environments, and skilled at rapid prototyping. These engineers spend 80% of their time writing code and 20% in stakeholder meetings.
Data FDEs: Specialize in data engineering and ML infrastructure. They build data pipelines, manage feature engineering, implement training workflows, and ensure data quality. They work closely with the customer’s data teams to understand data lineage and governance requirements.
Integration FDEs: Focus on connecting the new AI capabilities to existing systems. They work with APIs, event streaming, workflow engines, and enterprise service buses. They’re experts in the customer’s existing technology stack and can navigate legacy systems effectively.
Workflow and Delivery Cadence
FDE engagements typically follow a rhythm of rapid iteration punctuated by stakeholder reviews:
Week 1–2: Intensive Discovery
FDE engineers spend this period in deep observation mode. They shadow users, interview stakeholders, review existing systems, analyze data, and develop an initial understanding of workflows and constraints. They should deploy a “Hello World” version by end of week 2—something minimal but running in the production environment to validate access and integration points.
Week 3–8: Rapid Build and Iteration
The team deploys new functionality 2–3 times per week. Each deployment is followed by observation sessions where they watch users interact with the new features. This creates an extremely tight feedback loop. Weekly stakeholder demos ensure alignment, but the real feedback comes from watching actual usage, not scheduled reviews.
Week 9–12: Production Hardening and Scale
As the system handles real production load, focus shifts to performance optimization, reliability improvements, edge case handling, and operational tooling. The FDE team builds monitoring dashboards, runbooks, and automation to support ongoing operations.
Week 13+: Operationalization and Transition
The FDE team progressively hands off operational responsibility to the customer’s internal teams while remaining available for complex issues and feature enhancements. They conduct knowledge transfer sessions, pair-program with internal engineers, and document tribal knowledge.
Governance and Success Metrics
FDE requires different governance than traditional delivery models. Instead of milestone-based approvals, success is measured through:
Production Usage Metrics: What percentage of target users are actively using the system? How frequently? What workflows are they executing?
Business Outcome Metrics: What measurable business impact has been achieved? Cost savings, revenue increase, time reduction, quality improvement—metrics tied to actual business value, not technical deliverables.
Adoption Velocity: How quickly is usage growing? Are users discovering new workflows without prompting? Is usage spreading organically to adjacent teams?
Customer Sentiment: Net Promoter Score from actual users (not procurement stakeholders). Willingness to serve as references or case studies. Expansion pipeline for additional use cases.
Time to Production: How quickly did the team go from kickoff to meaningful production usage? This is a key efficiency metric.
Technical Debt Ratio: Is the solution architected for long-term sustainability, or is it accruing technical debt that will require future rework? FDE teams should build production-grade solutions, not prototypes.
Talent Strategy: Who Makes a Good FDE?
Not every engineer thrives in FDE roles. The most successful FDE engineers share certain characteristics:
Technical Breadth Over Narrow Depth: FDE engineers need to be comfortable working across the full stack—data engineering, backend services, frontend development, infrastructure, and ML. Deep specialization is less valuable than the ability to see the whole system and make architectural trade-offs.
Comfort with Ambiguity: FDE projects start with vague goals and evolve through discovery. Engineers who need clear requirements and well-defined tickets struggle. The best FDEs treat ambiguity as opportunity for creativity.
Business Curiosity: Strong FDEs genuinely care about understanding the business context. They ask “why” questions, not just “what” questions. They want to understand the business problem, not just build what they’re told to build.
Communication and Relationship Skills: FDE engineers spend significant time in stakeholder conversations, user observation sessions, and cross-functional coordination. Pure technical brilliance without communication ability doesn’t work.
Product Mindset: FDE engineers need to think like product managers, not just implementers. They should have opinions about what should be built, informed by user observation and business value assessment.
Below is the diagrammatic representation of FDE delivery stack in Figure 2:
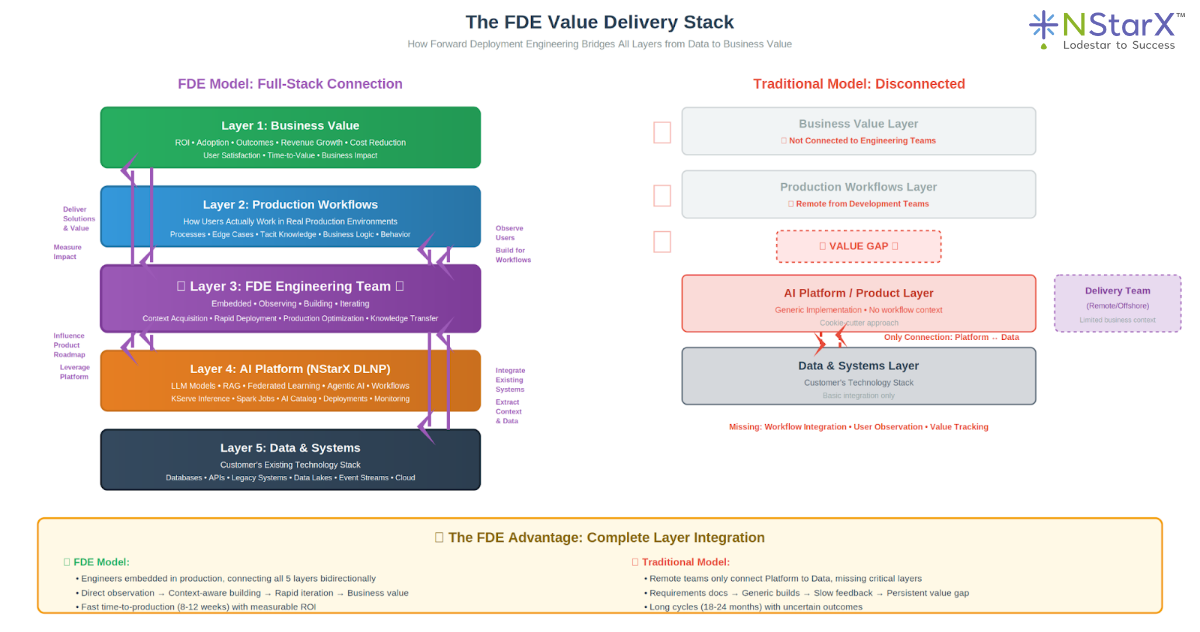
Figure 2: The FDE Value Delivery Stack
Case Study Examples (Realistic Scenarios)
Case Study 1: Federated Clinical Decision Support for Regional Health Network
Context: A network of 12 community hospitals wanted to deploy AI-powered clinical decision support for sepsis detection, but patient data couldn’t leave individual hospital networks due to HIPAA constraints and institutional governance policies.
Traditional Approach Would Have Failed: A traditional ML deployment would have required centralizing patient data for model training, which was non-negotiable. A standard consulting engagement would have designed a federated learning architecture but handed off implementation to hospital IT teams who lacked ML expertise.
FDE Approach: NStarX deployed a 4-person FDE team with engineers embedded at three pilot hospitals plus a central coordination engineer. Over 12 weeks, the team implemented secure training enclaves at each hospital site using confidential computing (AWS Nitro). They built federated learning orchestration using the DLNP platform to coordinate model updates across sites without sharing raw data. They worked directly with clinical informaticists at each hospital to validate model outputs against known cases and tune alert thresholds to minimize false positives. They observed clinical workflows to understand how alerts needed to integrate into existing EHR interfaces and paging systems.
Outcomes: Production deployment in 14 weeks versus 18+ months estimated for traditional approach. Model accuracy improved 15% from initial baseline through site-specific tuning. Seven additional hospitals joined the network in the following six months based on proven results. The FDE team’s observations led to three enhancements to NStarX’s federated learning capabilities that benefited future healthcare deployments.
Case Study 2: Agentic Procurement for Manufacturing Enterprise
Context: A Fortune 500 manufacturer processed 200,000+ purchase orders annually through a team of 45 procurement specialists. They wanted to automate routine PO processing using LLM-based agents while maintaining human oversight for exceptions.
Traditional Approach Would Have Failed: Generic procurement automation tools had failed because this company’s approval workflows involved complex, undocumented business rules varying by supplier category, region, and historical relationships. Requirements gathering had produced contradictory specifications because different procurement managers described the rules differently.
FDE Approach: A 5-person FDE team embedded with the procurement organization for 16 weeks. They shadowed procurement specialists for two weeks, observing hundreds of real PO decisions and documenting the actual decision patterns. They built an agent architecture where the LLM extracted structured data from requisitions, checked against policy rules, and routed to the appropriate approval workflow. They started in shadow mode where the agent generated recommendations without taking action, then progressively increased autonomy, eventually reaching 68% full automation for routine POs.
Outcomes: Within six months, processing time for routine POs dropped from 48 hours to 4 hours. Procurement specialists refocused on strategic sourcing and supplier negotiations. The agent automatically escalated the 32% of POs requiring human judgment with context about why they were exceptional. Employee satisfaction increased, and the company expanded the approach to invoice processing and contract renewals.
Case Study 3: Context-Graph Powered News Intelligence for Media Conglomerate
Context: A major media company wanted to build an AI assistant that could answer complex queries about their content archive while understanding relationships between topics, people, events, and evolving narratives.
Traditional Approach Would Have Failed: Vector search over article embeddings produced superficially relevant but contextually wrong results. Generic knowledge graphs didn’t capture the company’s specific editorial ontology and content relationships.
FDE Approach: A 6-person FDE team combined graph engineering, LLM expertise, and content domain knowledge over 20 weeks. They conducted workshops with senior editors to understand editorial relationships, built a hybrid architecture combining a Neo4j knowledge graph with vector embeddings and GPT-4, refined ontologies through real usage, and implemented a continuous learning loop where editors corrected relationship mappings.
Outcomes: Query response relevance improved 3.5x compared to pure vector search. Researchers reported 40% time savings finding contextual background for breaking stories. The system became strategic IP for the media company, enabling personalized content recommendations and automated storyline tracking. The FDE team’s knowledge graph design patterns influenced NStarX’s approach to context-graph architectures for other media and publishing clients.
The NStarX Perspective: FDE as Core to “Service-as-Software”
At NStarX, Forward Deployment Engineering isn’t a service offering—it’s the delivery mechanism for our entire Service-as-Software philosophy. Traditional IT services companies sell labor hours. Product companies sell software licenses. NStarX’s DLNP (Data Lake and Neural Platform) is positioned as a third category: service capabilities delivered through software, with FDE as the realization layer.
Why Service-as-Software Requires FDE
The Service-as-Software model assumes that common enterprise AI capabilities—data engineering, ML training pipelines, federated learning, LLM orchestration, monitoring, and governance—can be delivered as a unified platform rather than custom-built for each customer. But platforms require customization to deliver value. The DLNP provides the substrate; FDE teams build the customer-specific applications on that substrate.
This creates a virtuous cycle: FDE teams deploy the DLNP into diverse customer environments, encounter new integration patterns and use cases, and feed those learnings back into platform development. Capabilities that FDE teams build repeatedly in custom implementations get promoted into core platform features. The platform becomes smarter with each deployment, and FDE becomes more efficient because more functionality exists as reusable components.
Rapid MVP Cycles Through FDE
NStarX’s go-to-market strategy emphasizes rapid MVP cycles—prove value in production within 8–12 weeks, then expand based on demonstrated ROI. FDE is what makes this possible. Instead of spending months gathering requirements and designing generic solutions, NStarX FDE teams deploy minimal viable versions of the DLNP into customer environments and build value-driving applications iteratively.
This approach de-risks AI investments for customers. Instead of committing to 18-month transformation programs with uncertain outcomes, customers start with focused use cases deployed through FDE. Success builds confidence and creates expansion opportunities. Failed experiments fail fast and cheap.
FDE as Competitive Differentiation
In a market crowded with AI consulting firms and platform vendors, FDE provides differentiation through outcomes, not features. Competitors might have better models or cheaper consulting rates, but they can’t replicate the institutional knowledge and deployment patterns NStarX accumulates through hundreds of FDE engagements.
This becomes particularly powerful in regulated industries where compliance, data governance, and operational risk management are critical. NStarX FDE teams have deployed federated learning in healthcare networks navigating HIPAA, confidential computing for financial services firms managing trading algorithm IP, and privacy-preserving analytics for media companies protecting user data. Each deployment builds expertise that translates to faster, lower-risk deployments for the next customer in that vertical.
Future Outlook 2026–2030: The FDE Imperative for IT Services
Looking ahead to 2030, Forward Deployment Engineering won’t be a premium service offering—it will be table stakes for IT services companies that want to remain relevant in AI-native enterprises.
The Commoditization of Algorithms, The Value Migration to Integration
As foundation models become commodity infrastructure and AutoML platforms democratize model development, the scarce resource isn’t algorithmic innovation—it’s the ability to integrate AI into complex production environments and drive adoption. This is fundamentally an FDE capability, not a traditional consulting or product capability.
By 2028, we’ll see a clear bifurcation in the IT services market: firms that built robust FDE capabilities will command premium pricing and high customer retention, while firms still relying on offshore development factories will compete on cost for undifferentiated implementation work.
The Rise of Hybrid Product-Services Companies
The distinction between “product companies” and “services companies” will blur. Successful AI platform vendors will all have FDE-like deployment teams because pure software licensing can’t succeed in the enterprise AI market. Conversely, successful IT services firms will all have platform capabilities because pure services labor without reusable software IP can’t achieve the margins or scale needed to invest in AI expertise.
NStarX is architected for this convergence: the DLNP provides the product layer, FDE provides the services layer, but they’re deeply integrated rather than separate businesses.
The Talent War for FDE Engineers
The demand for FDE-caliber engineers will far exceed supply by 2027. These aren’t typical enterprise architects or application developers—they’re rare combinations of technical breadth, business acumen, and adaptability. Companies that can attract, develop, and retain FDE talent will have sustainable competitive advantage.
This will drive innovation in how companies develop FDE capabilities: hybrid models combining experienced senior FDEs with junior engineers being groomed for FDE roles, partnerships with universities to create FDE training programs, internal rotations where product engineers spend time in FDE roles to build customer empathy before returning to core platform development.
FDE Will Reshape Professional Services Economics
Traditional professional services economics relied on labor arbitrage—junior offshore developers doing implementation work billed out at multiples of their cost. FDE economics are different: highly skilled engineers command high costs but deliver much higher value through faster time-to-production, higher adoption rates, and expansion revenue. The business model shifts from maximizing billable hours to maximizing outcomes and customer lifetime value.
This economic shift will be challenging for traditional IT services giants with massive offshore delivery centers optimized for the old model. They’ll need to either transform their talent model (expensive and slow) or cede the high-value AI deployment market to nimbler competitors who built FDE-first.
Conclusion: FDE as the Deployment Model for AI-Native Enterprises
The transition to AI-native operations is the most significant enterprise technology shift since the client-server era. Unlike previous waves where new technology could be deployed through established IT delivery models, AI deployments require a fundamentally different approach. The gap between “the model works” and “the business gets value” is too large, too context-dependent, and too dynamic for traditional delivery methodologies.
Forward Deployment Engineering solves this problem by embedding engineers who understand both the technology and the product directly in customer environments where they can observe, build, and iterate based on production reality. It’s expensive in per-engineer costs but dramatically more efficient in outcomes—faster time to value, higher adoption, better ROI, and sticky customer relationships.
For IT services companies, the choice is stark: build FDE capabilities and compete on outcomes, or optimize for cost and compete in the shrinking market for commoditized implementation services. The companies that succeed in the AI-native era will be those that invested early in FDE as a core organizational capability, not a boutique offering.
For product engineering firms building AI platforms, FDE isn’t just a deployment strategy—it’s a competitive moat. The institutional knowledge accumulated through hundreds of deployments creates advantages that pure product features can’t replicate.
At NStarX, we’ve built FDE into the foundation of our Service-as-Software model because we believe the future of enterprise AI isn’t about selling algorithms or selling hours—it’s about delivering measurable business outcomes through AI-powered capabilities. FDE is how we turn that philosophy into production reality.
The AI-native enterprise era demands a new deployment model. Forward Deployment Engineering is that model. By 2030, every IT services company will either have built FDE capabilities or will have ceded the high-value AI market to those who did.
Forward Deployment Engineering – Core Concepts
- Palantir Technologies – Forward Deployed Engineering
- Palantir Careers: Forward Deployed Engineer Role
- URL: https://www.palantir.com/careers/teams/forward-deployed-engineering/
- Description: Overview of Palantir’s pioneering FDE model and role expectations
- Anduril Industries – Mission Software Engineering
- Anduril Careers: Mission Software Engineer
- URL: https://www.anduril.com/careers/
- Description: Modern defense tech company’s evolution of the FDE model
- Scale AI – Rapid Deployment Engineering
- Scale AI Blog: Building AI for the Real World
- URL: https://scale.com/blog
- Description: Insights on deploying production AI at scale
Enterprise AI Deployment Challenges
- Gartner Research – AI Project Success Rates
- “Why 85% of AI and Analytics Projects Fail” (2024)
- URL: https://www.gartner.com/en/newsroom/press-releases
- Note: Industry benchmark data on AI project failure rates and time-to-production metrics
- McKinsey & Company – State of AI Report
- “The State of AI in 2024: Generative AI’s Breakout Year”
- URL: https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
- Description: Comprehensive analysis of enterprise AI adoption patterns
- Harvard Business Review – AI Implementation
- “Why Companies That Wait to Adopt AI May Never Catch Up”
- URL: https://hbr.org/topic/subject/artificial-intelligence
- Description: Strategic perspectives on AI-native transformation
NStarX Platform and Service-as-Software
- NStarX Corporate Website
- NStarX – AI-First Enterprise Transformation
- URL: https://www.nstarxinc.com/
- Description: Company overview and Service-as-Software philosophy
AI/ML Operations and Platform Engineering
- Databricks – MLOps and LLMOps
- Databricks MLOps Guide
- URL: https://www.databricks.com/glossary/mlops
- Description: Best practices for ML operations at scale
- Google Cloud – MLOps: Continuous Delivery and Automation
- MLOps: Continuous delivery and automation pipelines in machine learning
- URL: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- Description: Comprehensive MLOps framework and architecture patterns
- Anthropic – Claude Enterprise Documentation
- Claude API Documentation
- URL: https://docs.anthropic.com/
- Description: Enterprise LLM deployment and integration patterns
- OpenAI – GPT Best Practices
- OpenAI Platform Documentation
- URL: https://platform.openai.com/docs/guides/production-best-practices
- Description: Production deployment guidelines for LLM applications
Federated Learning and Privacy-Preserving AI
- Google Research – Federated Learning
- “Federated Learning: Collaborative Machine Learning without Centralized Training Data”
- URL: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
- Description: Foundational concepts in federated learning
- NVIDIA – Federated Learning Framework
- NVIDIA FLARE: Federated Learning Application Runtime Environment
- URL: https://developer.nvidia.com/flare
- Description: Open-source framework for federated learning deployment
- Microsoft Research – Confidential Computing
- Azure Confidential Computing
- URL: https://azure.microsoft.com/en-us/solutions/confidential-compute/
- Description: Privacy-preserving computation and secure enclaves
Agentic AI and Multi-Agent Systems
- LangChain – Agent Documentation
- LangChain Agents Guide
- URL: https://python.langchain.com/docs/modules/agents/
- Description: Framework for building autonomous AI agents
- Microsoft – AutoGen Framework
- AutoGen: Multi-Agent Conversation Framework
- URL: https://microsoft.github.io/autogen/
- Description: Framework for developing multi-agent AI applications
Retrieval-Augmented Generation (RAG)
- Meta Research – RAG Paper
- “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”
- URL: https://arxiv.org/abs/2005.11401
- Description: Original research paper on RAG architecture
- Pinecone – Vector Database for RAG
- Pinecone Learning Center: RAG
- URL: https://www.pinecone.io/learn/retrieval-augmented-generation/
- Description: Practical guide to implementing RAG systems
- Weaviate – Vector Search and RAG
- Weaviate RAG Documentation
- URL: https://weaviate.io/developers/weaviate/concepts/retrieval-augmented-generation
- Description: Vector database approach to RAG implementation
Knowledge Graphs and Context Management
- Neo4j – Graph Database for AI
- Neo4j and Generative AI
- URL: https://neo4j.com/generativeai/
- Description: Knowledge graphs for LLM context enhancement
- AWS – Graph Databases
- Amazon Neptune for AI/ML
- URL: https://aws.amazon.com/neptune/
- Description: Graph database services for AI applications
Agile and Product Development Methodologies
- Scrum Alliance – Agile Framework
- What is Scrum?
- URL: https://www.scrumalliance.org/about-scrum
- Description: Agile methodology overview and best practices
- Atlassian – Agile Project Management
- Agile Project Management
- URL: https://www.atlassian.com/agile/project-management
- Description: Practical guides to agile implementation
Enterprise Architecture and Integration
- The Standish Group – CHAOS Report
- Project Success and Failure Rates
- URL: https://www.standishgroup.com/
- Note: Historical benchmark for waterfall vs. agile outcomes
- Martin Fowler – Software Architecture
- Martin Fowler’s Blog on Software Architecture
- URL: https://martinfowler.com/architecture/
- Description: Authoritative perspectives on software architecture patterns
Industry-Specific AI Applications
- Healthcare AI – Clinical Decision Support
- FDA – Artificial Intelligence and Machine Learning in Software as a Medical Device
- URL: https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-aiml-enabled-medical-devices
- Description: Regulatory framework for healthcare AI deployment
- Financial Services – AI Governance
- Federal Reserve – Artificial Intelligence and Machine Learning in Financial Services
- URL: https://www.federalreserve.gov/publications/ai-and-machine-learning.htm
- Description: Regulatory considerations for financial AI applications
Data Governance and Compliance
- GDPR – General Data Protection Regulation
- Official GDPR Portal
- URL: https://gdpr.eu/
- Description: European data protection and privacy requirements
- HIPAA – Health Insurance Portability and Accountability Act
- HHS HIPAA for Professionals
- URL: https://www.hhs.gov/hipaa/for-professionals/index.html
- Description: Healthcare data privacy requirements in the United States
Cloud and Infrastructure Platforms
- AWS – AI/ML Services
- Amazon Web Services Machine Learning
- URL: https://aws.amazon.com/machine-learning/
- Description: Cloud infrastructure for AI/ML workloads
- Google Cloud – Vertex AI
- Vertex AI Platform
- URL: https://cloud.google.com/vertex-ai
- Description: Unified ML platform for model deployment
- Microsoft Azure – AI Platform
- Azure AI Services
- URL: https://azure.microsoft.com/en-us/solutions/ai/
- Description: Enterprise AI services and infrastructure
Model Serving and Inference
- KServe – Kubernetes Model Serving
- KServe Documentation
- URL: https://kserve.github.io/website/
- Description: Kubernetes-native model serving framework
- Seldon – ML Deployment
- Seldon Core Documentation
- URL: https://docs.seldon.io/projects/seldon-core/
- Description: ML deployment platform for Kubernetes
Monitoring and Observability
- Arize AI – ML Observability
- Arize ML Observability Platform
- URL: https://arize.com/
- Description: Monitoring and troubleshooting for ML models in production
- Weights & Biases – Experiment Tracking
- W&B Documentation
- URL: https://docs.wandb.ai/
- Description: ML experiment tracking and model management
Big Data Processing
- Apache Spark – Unified Analytics Engine
- Apache Spark Documentation
- URL: https://spark.apache.org/docs/latest/
- Description: Large-scale data processing framework
- Databricks – Lakehouse Architecture
- Databricks Lakehouse Platform
- URL: https://www.databricks.com/product/data-lakehouse
- Description: Unified data architecture for AI/ML
DevOps and CI/CD for AI
- Tekton – Cloud Native CI/CD
- Tekton Documentation
- URL: https://tekton.dev/
- Description: Kubernetes-native CI/CD pipelines
- MLflow – ML Lifecycle Management
- MLflow Documentation
- URL: https://mlflow.org/docs/latest/index.html
- Description: Open source platform for ML lifecycle management
Additional Resources and Industry Analysis
- O’Reilly – AI Adoption Survey
- O’Reilly AI Adoption in the Enterprise
- URL: https://www.oreilly.com/radar/ai-adoption-in-the-enterprise/
- Description: Annual survey of enterprise AI adoption trends
- Stanford HAI – AI Index Report
- Stanford AI Index Report
- URL: https://aiindex.stanford.edu/
- Description: Comprehensive tracking of AI progress and adoption
- CB Insights – AI Trends
- CB Insights AI Research
- URL: https://www.cbinsights.com/research/artificial-intelligence-trends/
- Description: Market intelligence on AI investment and adoption
- Forrester Research – Enterprise AI
- Forrester AI and Machine Learning Research
- URL: https://www.forrester.com/research/ai-machine-learning/
- Description: Market analysis and best practices for enterprise AI